 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest-Choice Edge Grafting for Efficient Structure Learning of Markov Random Fields
May 20, 2018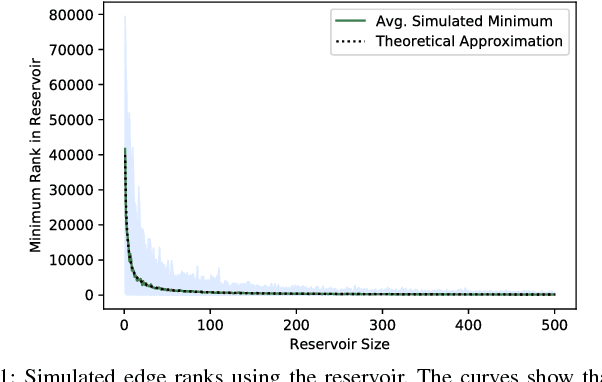
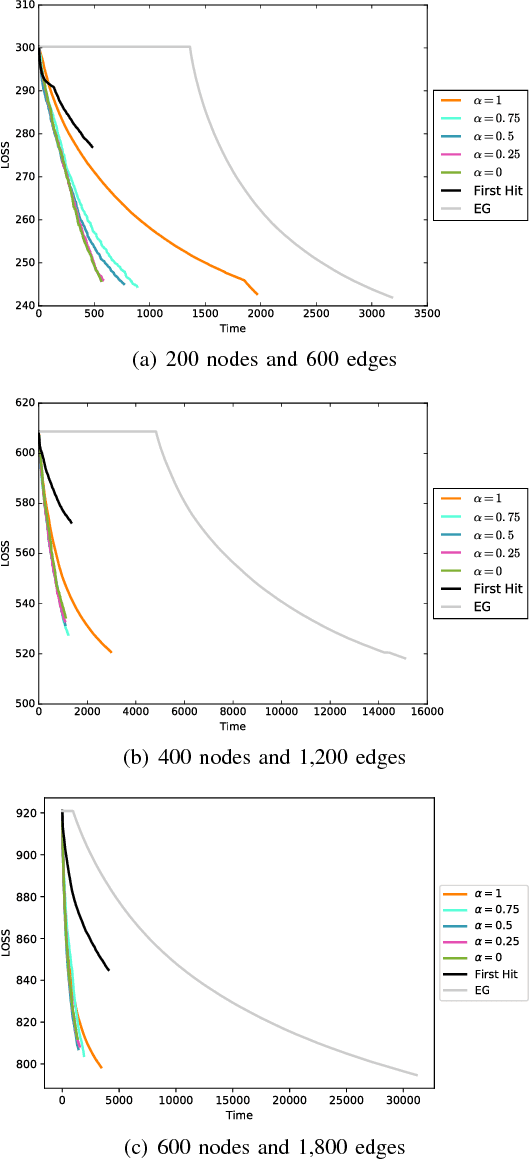
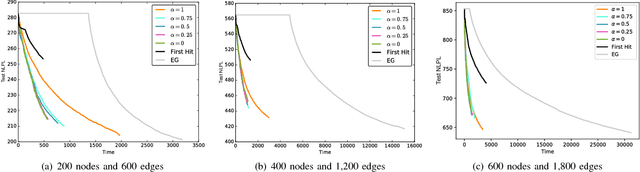
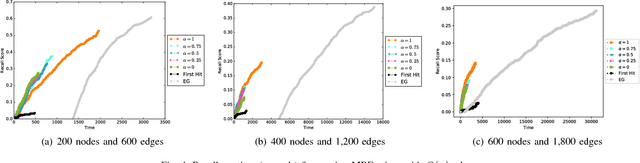
Incremental methods for structure learning of pairwise Markov random fields (MRFs), such as grafting, improve scalability by avoiding inference over the entire feature space in each optimization step. Instead, inference is performed over an incrementally grown active set of features. In this paper, we address key computational bottlenecks that current incremental techniques still suffer by introducing best-choice edge grafting, an incremental, structured method that activates edges as groups of features in a streaming setting. The method uses a reservoir of edges that satisfy an activation condition, approximating the search for the optimal edge to activate. It also reorganizes the search space using search-history and structure heuristics. Experiments show a significant speedup for structure learning and a controllable trade-off between the speed and quality of learning.
New Fairness Metrics for Recommendation that Embrace Differences
Dec 13, 2017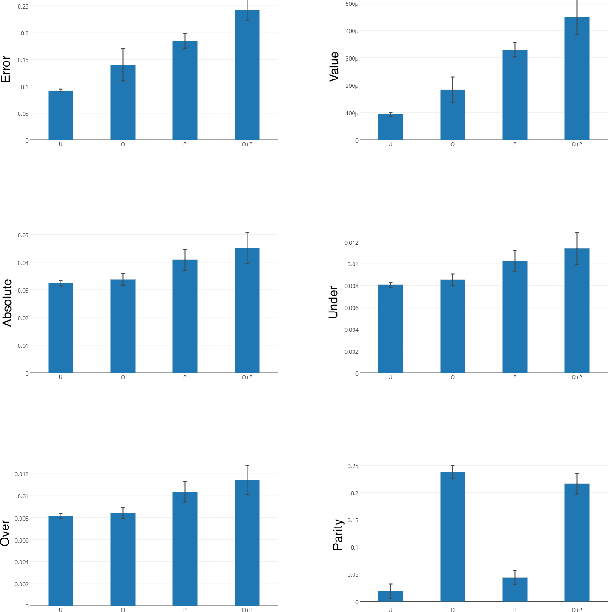
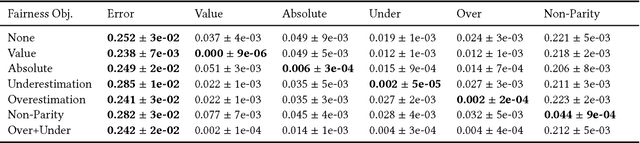
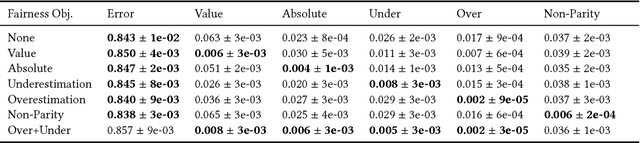
We study fairness in collaborative-filtering recommender systems, which are sensitive to discrimination that exists in historical data. Biased data can lead collaborative filtering methods to make unfair predictions against minority groups of users. We identify the insufficiency of existing fairness metrics and propose four new metrics that address different forms of unfairness. These fairness metrics can be optimized by adding fairness terms to the learning objective. Experiments on synthetic and real data show that our new metrics can better measure fairness than the baseline, and that the fairness objectives effectively help reduce unfairness.
Beyond Parity: Fairness Objectives for Collaborative Filtering
Nov 30, 2017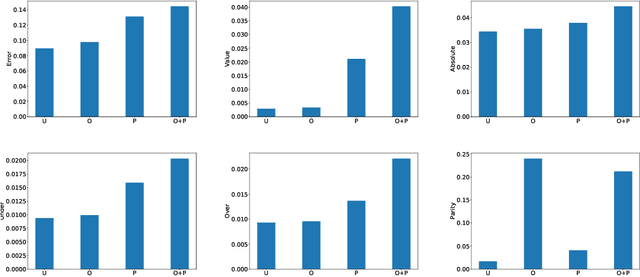

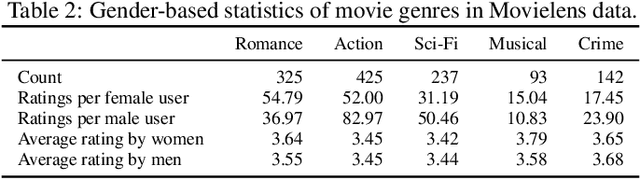

We study fairness in collaborative-filtering recommender systems, which are sensitive to discrimination that exists in historical data. Biased data can lead collaborative-filtering methods to make unfair predictions for users from minority groups. We identify the insufficiency of existing fairness metrics and propose four new metrics that address different forms of unfairness. These fairness metrics can be optimized by adding fairness terms to the learning objective. Experiments on synthetic and real data show that our new metrics can better measure fairness than the baseline, and that the fairness objectives effectively help reduce unfairness.
Hinge-Loss Markov Random Fields and Probabilistic Soft Logic
Nov 17, 2017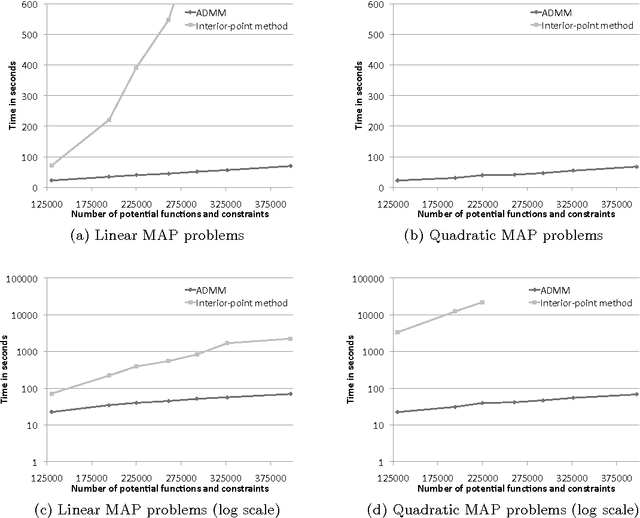
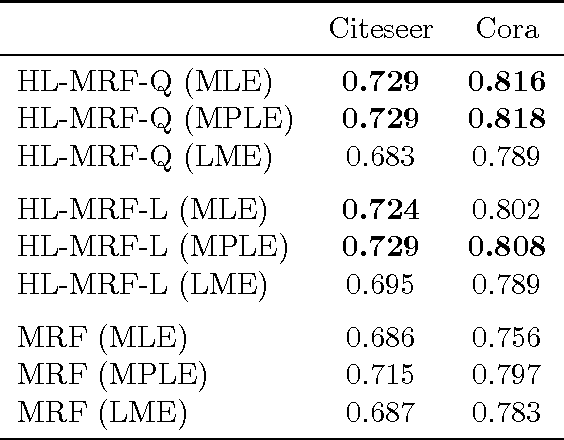
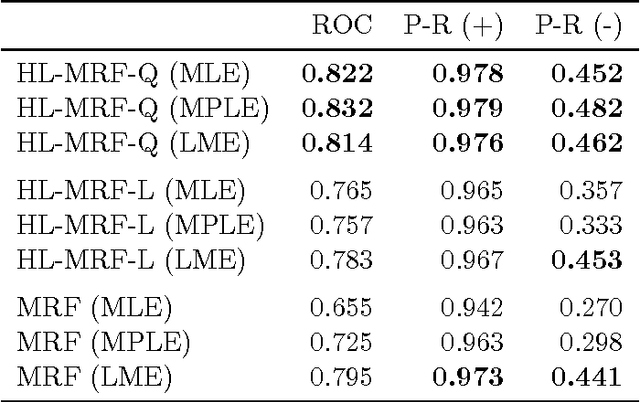

A fundamental challenge in developing high-impact machine learning technologies is balancing the need to model rich, structured domains with the ability to scale to big data. Many important problem areas are both richly structured and large scale, from social and biological networks, to knowledge graphs and the Web, to images, video, and natural language. In this paper, we introduce two new formalisms for modeling structured data, and show that they can both capture rich structure and scale to big data. The first, hinge-loss Markov random fields (HL-MRFs), is a new kind of probabilistic graphical model that generalizes different approaches to convex inference. We unite three approaches from the randomized algorithms, probabilistic graphical models, and fuzzy logic communities, showing that all three lead to the same inference objective. We then define HL-MRFs by generalizing this unified objective. The second new formalism, probabilistic soft logic (PSL), is a probabilistic programming language that makes HL-MRFs easy to define using a syntax based on first-order logic. We introduce an algorithm for inferring most-probable variable assignments (MAP inference) that is much more scalable than general-purpose convex optimization methods, because it uses message passing to take advantage of sparse dependency structures. We then show how to learn the parameters of HL-MRFs. The learned HL-MRFs are as accurate as analogous discrete models, but much more scalable. Together, these algorithms enable HL-MRFs and PSL to model rich, structured data at scales not previously possible.
Recurrent Collective Classification
Mar 19, 2017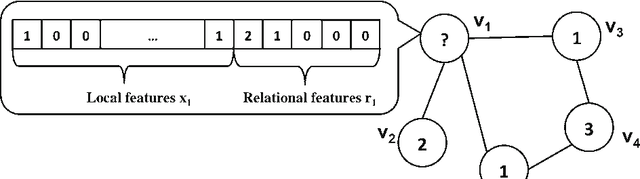
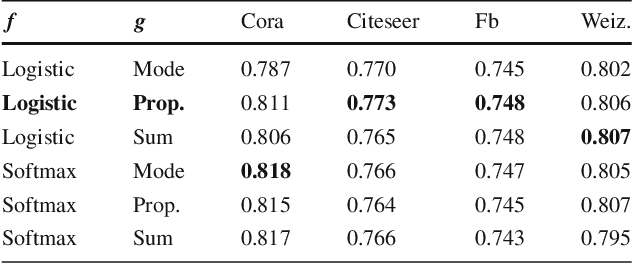
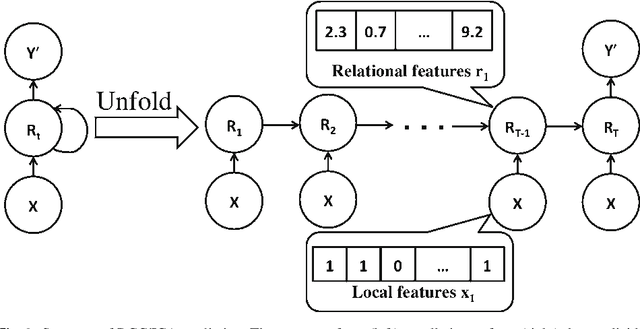
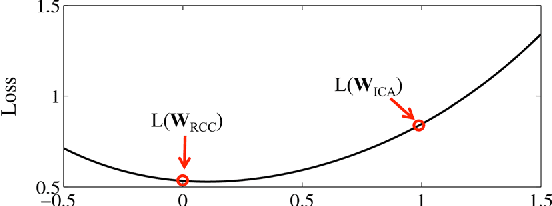
We propose a new method for training iterative collective classifiers for labeling nodes in network data. The iterative classification algorithm (ICA) is a canonical method for incorporating relational information into classification. Yet, existing methods for training ICA models rely on the assumption that relational features reflect the true labels of the nodes. This unrealistic assumption introduces a bias that is inconsistent with the actual prediction algorithm. In this paper, we introduce recurrent collective classification (RCC), a variant of ICA analogous to recurrent neural network prediction. RCC accommodates any differentiable local classifier and relational feature functions. We provide gradient-based strategies for optimizing over model parameters to more directly minimize the loss function. In our experiments, this direct loss minimization translates to improved accuracy and robustness on real network data. We demonstrate the robustness of RCC in settings where local classification is very noisy, settings that are particularly challenging for ICA.
Cyberbullying Identification Using Participant-Vocabulary Consistency
Jun 26, 2016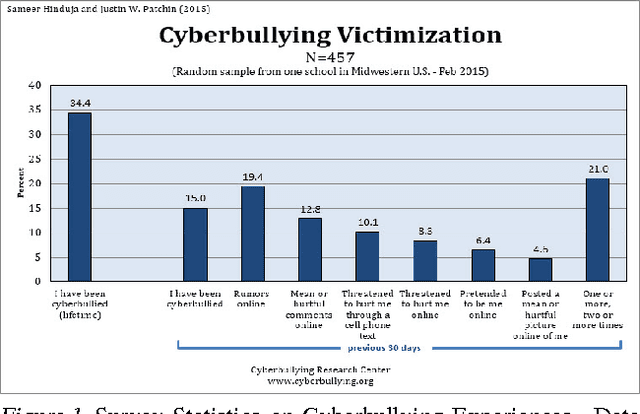

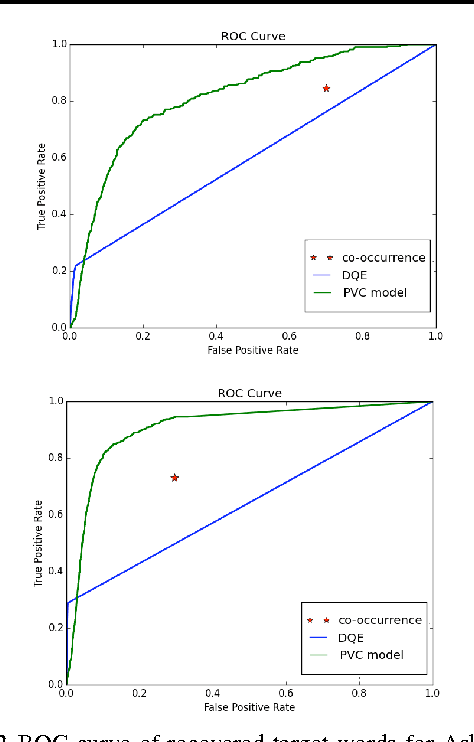

With the rise of social media, people can now form relationships and communities easily regardless of location, race, ethnicity, or gender. However, the power of social media simultaneously enables harmful online behavior such as harassment and bullying. Cyberbullying is a serious social problem, making it an important topic in social network analysis. Machine learning methods can potentially help provide better understanding of this phenomenon, but they must address several key challenges: the rapidly changing vocabulary involved in cyber- bullying, the role of social network structure, and the scale of the data. In this study, we propose a model that simultaneously discovers instigators and victims of bullying as well as new bullying vocabulary by starting with a corpus of social interactions and a seed dictionary of bullying indicators. We formulate an objective function based on participant-vocabulary consistency. We evaluate this approach on Twitter and Ask.fm data sets and show that the proposed method can detect new bullying vocabulary as well as victims and bullies.
Hinge-loss Markov Random Fields: Convex Inference for Structured Prediction
Sep 26, 2013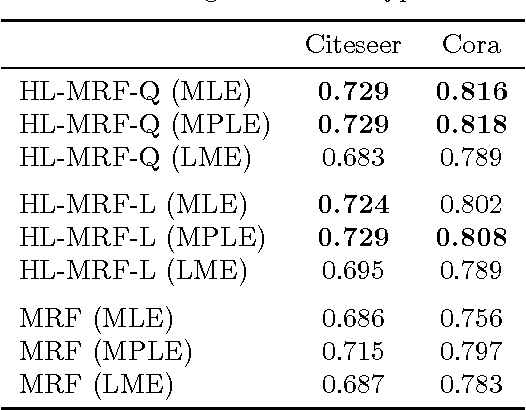

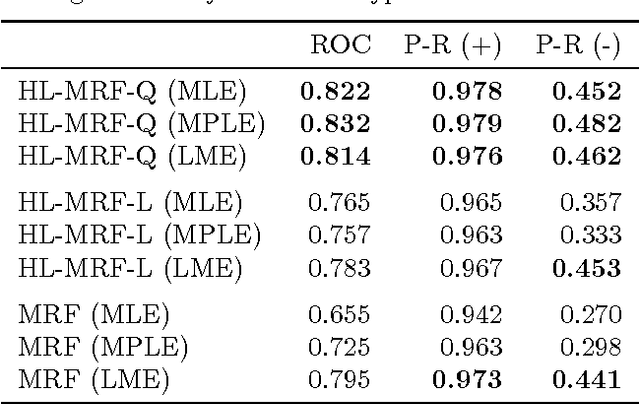
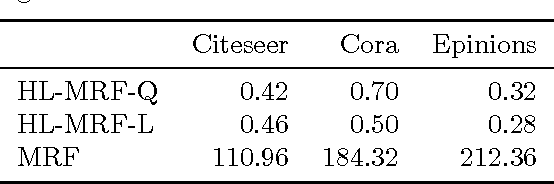
Graphical models for structured domains are powerful tools, but the computational complexities of combinatorial prediction spaces can force restrictions on models, or require approximate inference in order to be tractable. Instead of working in a combinatorial space, we use hinge-loss Markov random fields (HL-MRFs), an expressive class of graphical models with log-concave density functions over continuous variables, which can represent confidences in discrete predictions. This paper demonstrates that HL-MRFs are general tools for fast and accurate structured prediction. We introduce the first inference algorithm that is both scalable and applicable to the full class of HL-MRFs, and show how to train HL-MRFs with several learning algorithms. Our experiments show that HL-MRFs match or surpass the predictive performance of state-of-the-art methods, including discrete models, in four application domains.
A Hypergraph-Partitioned Vertex Programming Approach for Large-scale Consensus Optimization
Aug 30, 2013


In modern data science problems, techniques for extracting value from big data require performing large-scale optimization over heterogenous, irregularly structured data. Much of this data is best represented as multi-relational graphs, making vertex programming abstractions such as those of Pregel and GraphLab ideal fits for modern large-scale data analysis. In this paper, we describe a vertex-programming implementation of a popular consensus optimization technique known as the alternating direction of multipliers (ADMM). ADMM consensus optimization allows elegant solution of complex objectives such as inference in rich probabilistic models. We also introduce a novel hypergraph partitioning technique that improves over state-of-the-art partitioning techniques for vertex programming and significantly reduces the communication cost by reducing the number of replicated nodes up to an order of magnitude. We implemented our algorithm in GraphLab and measure scaling performance on a variety of realistic bipartite graph distributions and a large synthetic voter-opinion analysis application. In our experiments, we are able to achieve a 50% improvement in runtime over the current state-of-the-art GraphLab partitioning scheme.
Graph-based Generalization Bounds for Learning Binary Relations
May 31, 2013We investigate the generalizability of learned binary relations: functions that map pairs of instances to a logical indicator. This problem has application in numerous areas of machine learning, such as ranking, entity resolution and link prediction. Our learning framework incorporates an example labeler that, given a sequence $X$ of $n$ instances and a desired training size $m$, subsamples $m$ pairs from $X \times X$ without replacement. The challenge in analyzing this learning scenario is that pairwise combinations of random variables are inherently dependent, which prevents us from using traditional learning-theoretic arguments. We present a unified, graph-based analysis, which allows us to analyze this dependence using well-known graph identities. We are then able to bound the generalization error of learned binary relations using Rademacher complexity and algorithmic stability. The rate of uniform convergence is partially determined by the labeler's subsampling process. We thus examine how various assumptions about subsampling affect generalization; under a natural random subsampling process, our bounds guarantee $\tilde{O}(1/\sqrt{n})$ uniform convergence.
Multi-relational Learning Using Weighted Tensor Decomposition with Modular Loss
May 31, 2013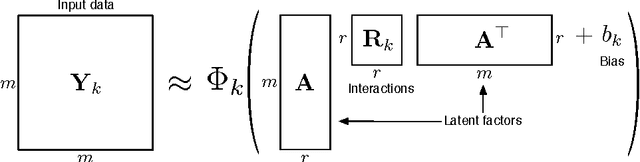
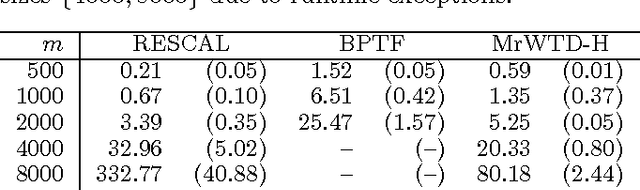
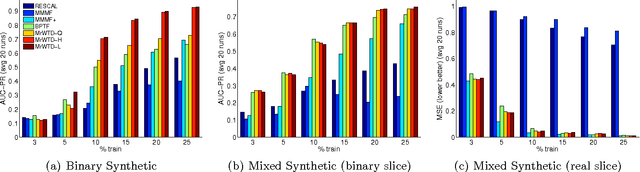
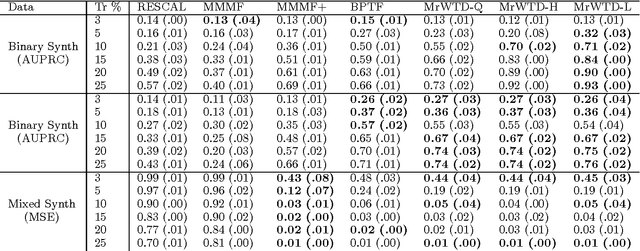
We propose a modular framework for multi-relational learning via tensor decomposition. In our learning setting, the training data contains multiple types of relationships among a set of objects, which we represent by a sparse three-mode tensor. The goal is to predict the values of the missing entries. To do so, we model each relationship as a function of a linear combination of latent factors. We learn this latent representation by computing a low-rank tensor decomposition, using quasi-Newton optimization of a weighted objective function. Sparsity in the observed data is captured by the weighted objective, leading to improved accuracy when training data is limited. Exploiting sparsity also improves efficiency, potentially up to an order of magnitude over unweighted approaches. In addition, our framework accommodates arbitrary combinations of smooth, task-specific loss functions, making it better suited for learning different types of relations. For the typical cases of real-valued functions and binary relations, we propose several loss functions and derive the associated parameter gradients. We evaluate our method on synthetic and real data, showing significant improvements in both accuracy and scalability over related factorization techniques.