 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilter Style Transfer between Photos
Jul 15, 2020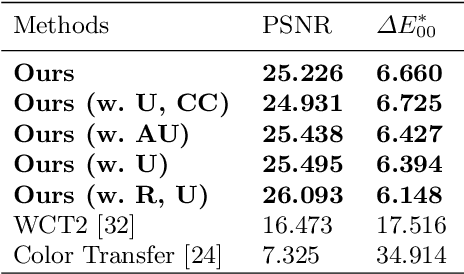
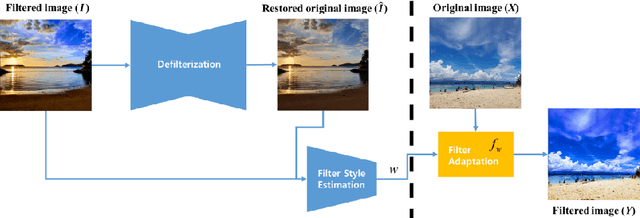


Over the past few years, image-to-image style transfer has risen to the frontiers of neural image processing. While conventional methods were successful in various tasks such as color and texture transfer between images, none could effectively work with the custom filter effects that are applied by users through various platforms like Instagram. In this paper, we introduce a new concept of style transfer, Filter Style Transfer (FST). Unlike conventional style transfer, new technique FST can extract and transfer custom filter style from a filtered style image to a content image. FST first infers the original image from a filtered reference via image-to-image translation. Then it estimates filter parameters from the difference between them. To resolve the ill-posed nature of reconstructing the original image from the reference, we represent each pixel color of an image to class mean and deviation. Besides, to handle the intra-class color variation, we propose an uncertainty based weighted least square method for restoring an original image. To the best of our knowledge, FST is the first style transfer method that can transfer custom filter effects between FHD image under 2ms on a mobile device without any textual context loss.
MarioNETte: Few-shot Face Reenactment Preserving Identity of Unseen Targets
Nov 19, 2019
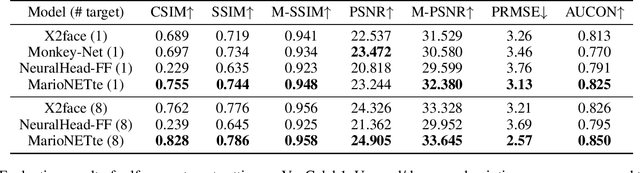
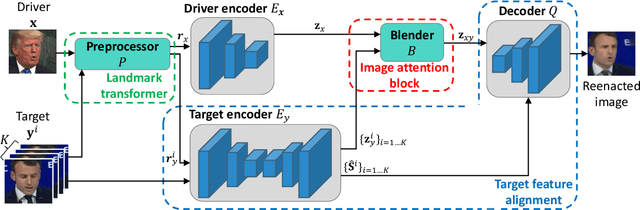
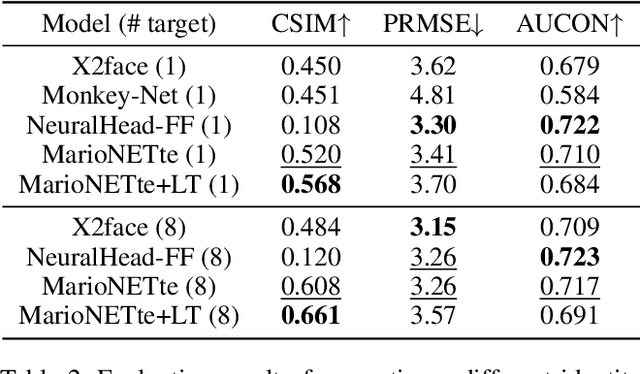
When there is a mismatch between the target identity and the driver identity, face reenactment suffers severe degradation in the quality of the result, especially in a few-shot setting. The identity preservation problem, where the model loses the detailed information of the target leading to a defective output, is the most common failure mode. The problem has several potential sources such as the identity of the driver leaking due to the identity mismatch, or dealing with unseen large poses. To overcome such problems, we introduce components that address the mentioned problem: image attention block, target feature alignment, and landmark transformer. Through attending and warping the relevant features, the proposed architecture, called MarioNETte, produces high-quality reenactments of unseen identities in a few-shot setting. In addition, the landmark transformer dramatically alleviates the identity preservation problem by isolating the expression geometry through landmark disentanglement. Comprehensive experiments are performed to verify that the proposed framework can generate highly realistic faces, outperforming all other baselines, even under a significant mismatch of facial characteristics between the target and the driver.
Revisiting Classical Bagging with Modern Transfer Learning for On-the-fly Disaster Damage Detector
Oct 04, 2019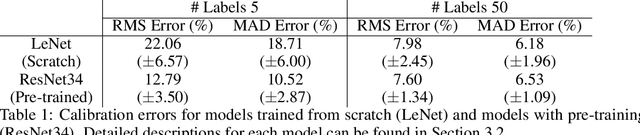
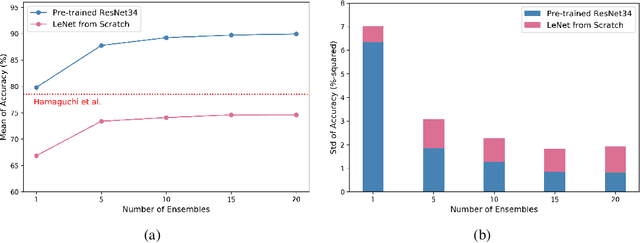
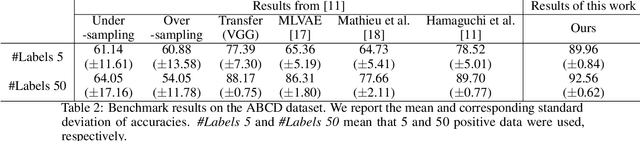
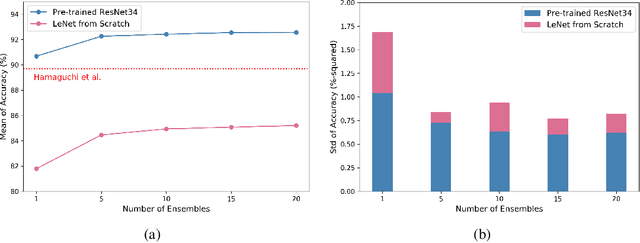
Automatic post-disaster damage detection using aerial imagery is crucial for quick assessment of damage caused by disaster and development of a recovery plan. The main problem preventing us from creating an applicable model in practice is that damaged (positive) examples we are trying to detect are much harder to obtain than undamaged (negative) examples, especially in short time. In this paper, we revisit the classical bootstrap aggregating approach in the context of modern transfer learning for data-efficient disaster damage detection. Unlike previous classical ensemble learning articles, our work points out the effectiveness of simple bagging in deep transfer learning that has been underestimated in the context of imbalanced classification. Benchmark results on the AIST Building Change Detection dataset show that our approach significantly outperforms existing methodologies, including the recently proposed disentanglement learning.
Bridging Adversarial Robustness and Gradient Interpretability
Apr 19, 2019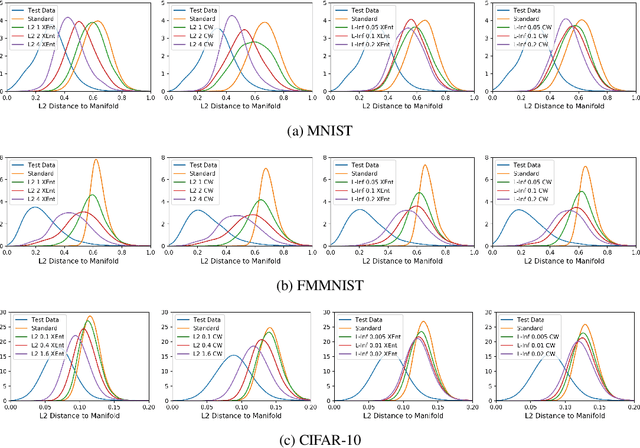

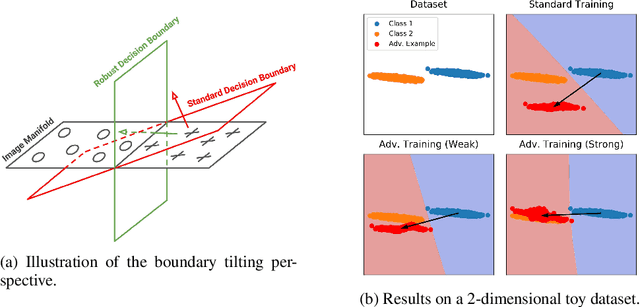
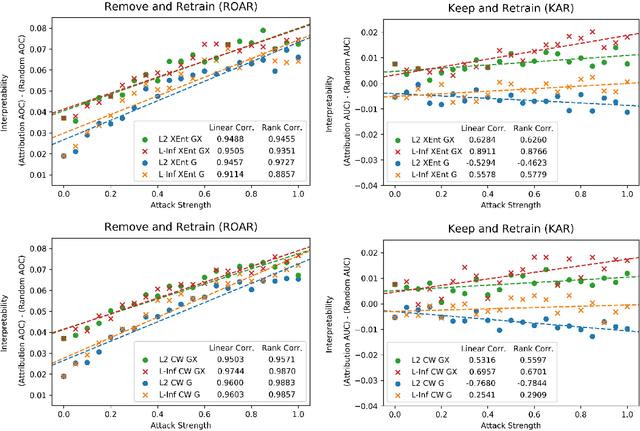
Adversarial training is a training scheme designed to counter adversarial attacks by augmenting the training dataset with adversarial examples. Surprisingly, several studies have observed that loss gradients from adversarially trained DNNs are visually more interpretable than those from standard DNNs. Although this phenomenon is interesting, there are only few works that have offered an explanation. In this paper, we attempted to bridge this gap between adversarial robustness and gradient interpretability. To this end, we identified that loss gradients from adversarially trained DNNs align better with human perception because adversarial training restricts gradients closer to the image manifold. We then demonstrated that adversarial training causes loss gradients to be quantitatively meaningful. Finally, we showed that under the adversarial training framework, there exists an empirical trade-off between test accuracy and loss gradient interpretability and proposed two potential approaches to resolving this trade-off.
Temporal Convolution for Real-time Keyword Spotting on Mobile Devices
Apr 08, 2019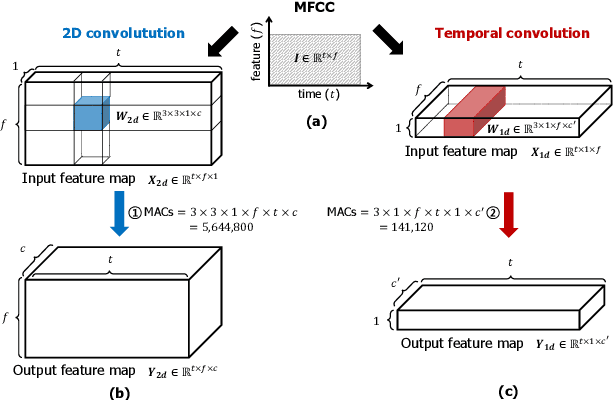
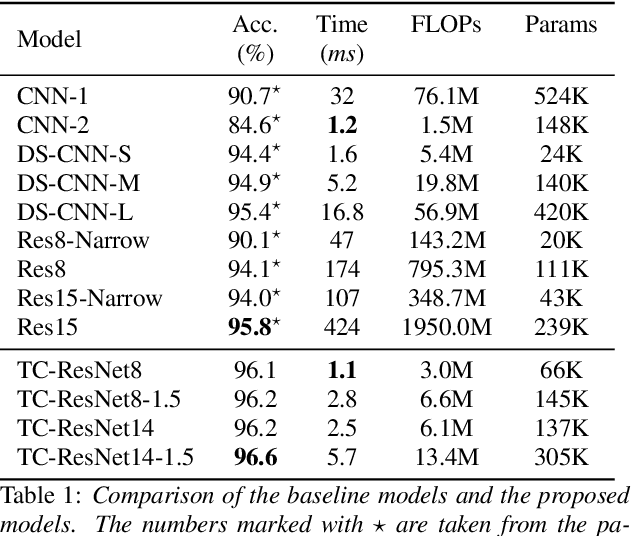
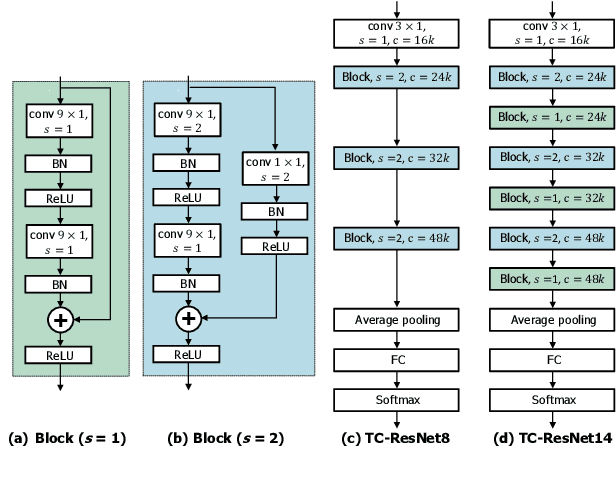
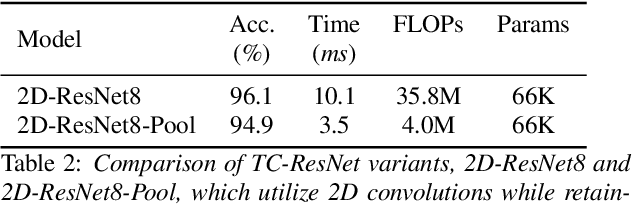
Keyword spotting (KWS) plays a critical role in enabling speech-based user interactions on smart devices. Recent developments in the field of deep learning have led to wide adoption of convolutional neural networks (CNNs) in KWS systems due to their exceptional accuracy and robustness. The main challenge faced by KWS systems is the trade-off between high accuracy and low latency. Unfortunately, there has been little quantitative analysis of the actual latency of KWS models on mobile devices. This is especially concerning since conventional convolution-based KWS approaches are known to require a large number of operations to attain an adequate level of performance. In this paper, we propose a temporal convolution for real-time KWS on mobile devices. Unlike most of the 2D convolution-based KWS approaches that require a deep architecture to fully capture both low- and high-frequency domains, we exploit temporal convolutions with a compact ResNet architecture. In Google Speech Command Dataset, we achieve more than \textbf{385x} speedup on Google Pixel 1 and surpass the accuracy compared to the state-of-the-art model. In addition, we release the implementation of the proposed and the baseline models including an end-to-end pipeline for training models and evaluating them on mobile devices.
Why are Saliency Maps Noisy? Cause of and Solution to Noisy Saliency Maps
Feb 20, 2019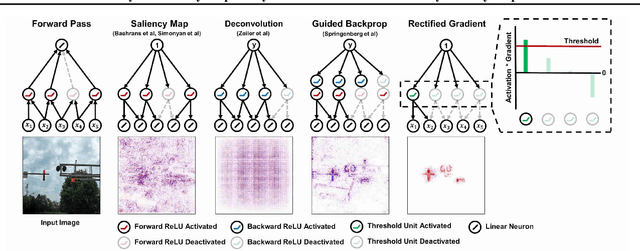
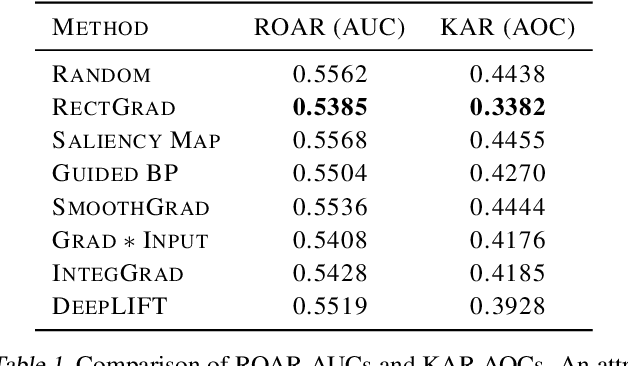
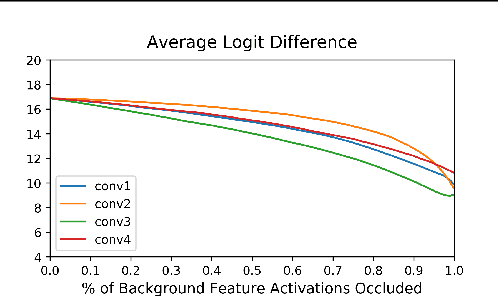

Saliency Map, the gradient of the score function with respect to the input, is the most basic technique for interpreting deep neural network decisions. However, saliency maps are often visually noisy. Although several hypotheses were proposed to account for this phenomenon, there are few works that provide rigorous analyses of noisy saliency maps. In this paper, we identify that noise occurs in saliency maps when irrelevant features pass through ReLU activation functions. Then we propose Rectified Gradient, a method that solves this problem through layer-wise thresholding during backpropagation. Experiments with neural networks trained on CIFAR-10 and ImageNet showed effectiveness of our method and its superiority to other attribution methods.
Noise-adding Methods of Saliency Map as Series of Higher Order Partial Derivative
Jun 08, 2018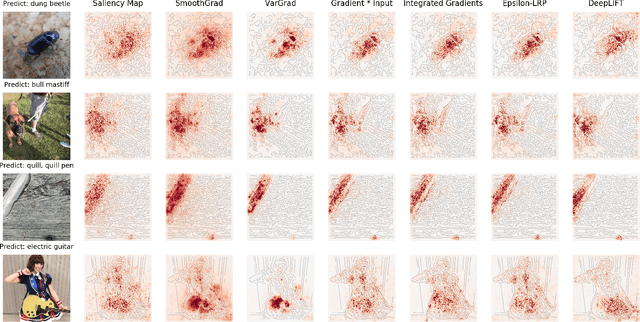

SmoothGrad and VarGrad are techniques that enhance the empirical quality of standard saliency maps by adding noise to input. However, there were few works that provide a rigorous theoretical interpretation of those methods. We analytically formalize the result of these noise-adding methods. As a result, we observe two interesting results from the existing noise-adding methods. First, SmoothGrad does not make the gradient of the score function smooth. Second, VarGrad is independent of the gradient of the score function. We believe that our findings provide a clue to reveal the relationship between local explanation methods of deep neural networks and higher-order partial derivatives of the score function.