 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Predictive Distributions: Does Bayesian Deep Learning Work?
Oct 09, 2021
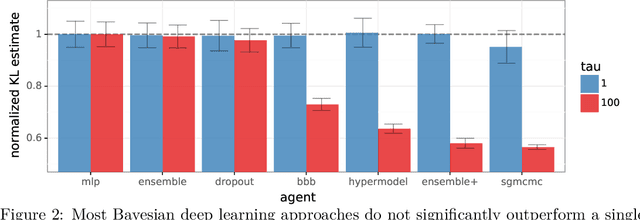
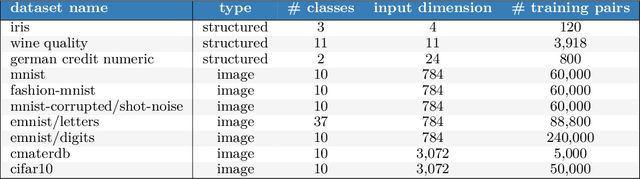
Posterior predictive distributions quantify uncertainties ignored by point estimates. This paper introduces \textit{The Neural Testbed}, which provides tools for the systematic evaluation of agents that generate such predictions. Crucially, these tools assess not only the quality of marginal predictions per input, but also joint predictions given many inputs. Joint distributions are often critical for useful uncertainty quantification, but they have been largely overlooked by the Bayesian deep learning community. We benchmark several approaches to uncertainty estimation using a neural-network-based data generating process. Our results reveal the importance of evaluation beyond marginal predictions. Further, they reconcile sources of confusion in the field, such as why Bayesian deep learning approaches that generate accurate marginal predictions perform poorly in sequential decision tasks, how incorporating priors can be helpful, and what roles epistemic versus aleatoric uncertainty play when evaluating performance. We also present experiments on real-world challenge datasets, which show a high correlation with testbed results, and that the importance of evaluating joint predictive distributions carries over to real data. As part of this effort, we opensource The Neural Testbed, including all implementations from this paper.
Deep Exploration for Recommendation Systems
Sep 26, 2021
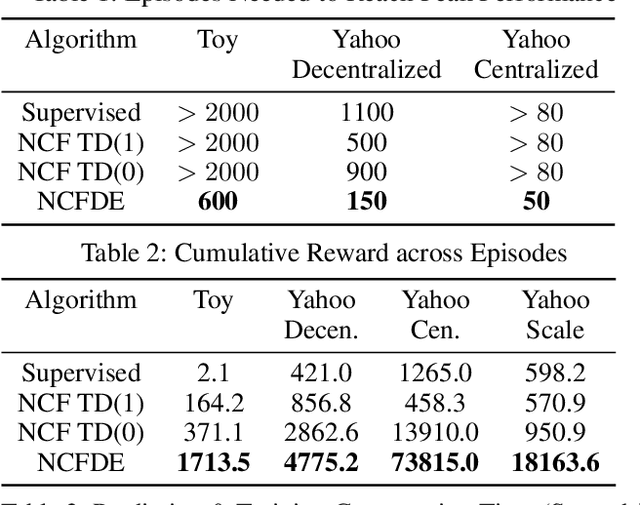
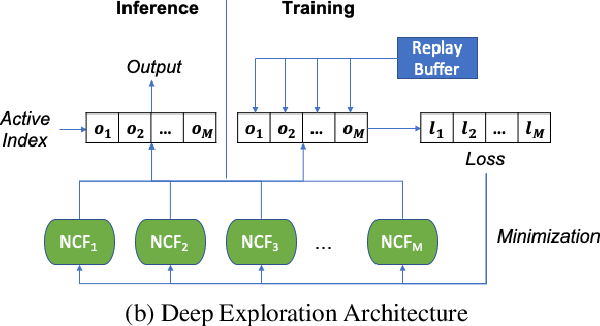
We investigate the design of recommendation systems that can efficiently learn from sparse and delayed feedback. Deep Exploration can play an important role in such contexts, enabling a recommendation system to much more quickly assess a user's needs and personalize service. We design an algorithm based on Thompson Sampling that carries out Deep Exploration. We demonstrate through simulations that the algorithm can substantially amplify the rate of positive feedback relative to common recommendation system designs in a scalable fashion. These results demonstrate promise that we hope will inspire engineering of production recommendation systems that leverage Deep Exploration.
Evaluating Probabilistic Inference in Deep Learning: Beyond Marginal Predictions
Jul 20, 2021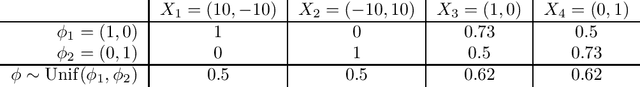
A fundamental challenge for any intelligent system is prediction: given some inputs $X_1,..,X_\tau$ can you predict outcomes $Y_1,.., Y_\tau$. The KL divergence $\mathbf{d}_{\mathrm{KL}}$ provides a natural measure of prediction quality, but the majority of deep learning research looks only at the marginal predictions per input $X_t$. In this technical report we propose a scoring rule $\mathbf{d}_{\mathrm{KL}}^\tau$, parameterized by $\tau \in \mathcal{N}$ that evaluates the joint predictions at $\tau$ inputs simultaneously. We show that the commonly-used $\tau=1$ can be insufficient to drive good decisions in many settings of interest. We also show that, as $\tau$ grows, performing well according to $\mathbf{d}_{\mathrm{KL}}^\tau$ recovers universal guarantees for any possible decision. Finally, we provide problem-dependent guidance on the scale of $\tau$ for which our score provides sufficient guarantees for good performance.
Epistemic Neural Networks
Jul 19, 2021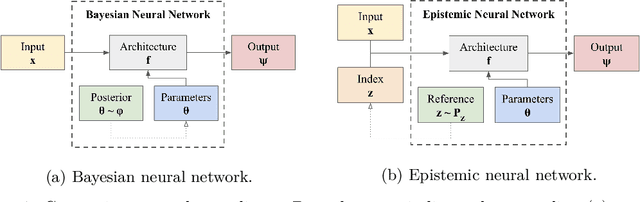
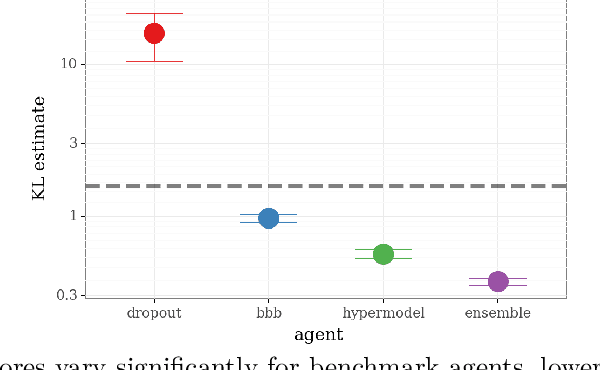
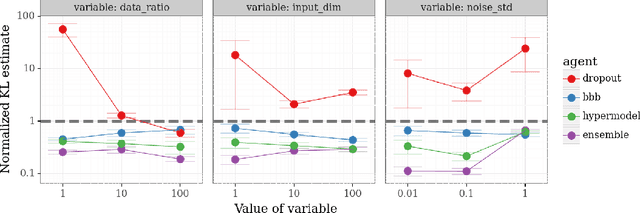
We introduce the \textit{epistemic neural network} (ENN) as an interface for uncertainty modeling in deep learning. All existing approaches to uncertainty modeling can be expressed as ENNs, and any ENN can be identified with a Bayesian neural network. However, this new perspective provides several promising directions for future research. Where prior work has developed probabilistic inference tools for neural networks; we ask instead, `which neural networks are suitable as tools for probabilistic inference?'. We propose a clear and simple metric for progress in ENNs: the KL-divergence with respect to a target distribution. We develop a computational testbed based on inference in a neural network Gaussian process and release our code as a benchmark at \url{https://github.com/deepmind/enn}. We evaluate several canonical approaches to uncertainty modeling in deep learning, and find they vary greatly in their performance. We provide insight to the sensitivity of these results and show that our metric is highly correlated with performance in sequential decision problems. Finally, we provide indications that new ENN architectures can improve performance in both the statistical quality and computational cost.
Reinforcement Learning, Bit by Bit
Mar 14, 2021
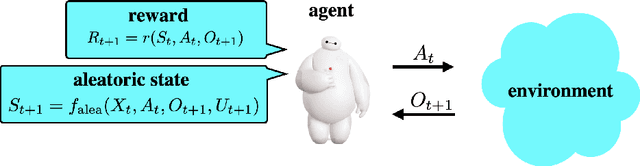
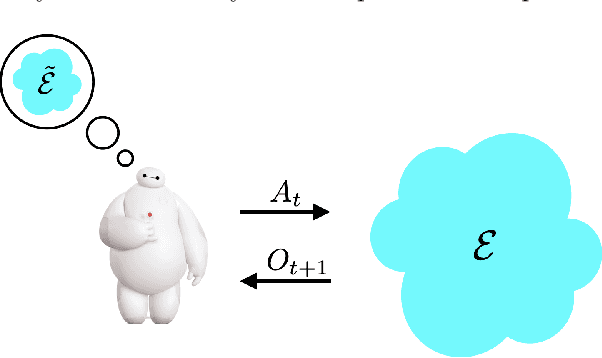

Reinforcement learning agents have demonstrated remarkable achievements in simulated environments. Data efficiency poses an impediment to carrying this success over to real environments. The design of data-efficient agents calls for a deeper understanding of information acquisition and representation. We develop concepts and establish a regret bound that together offer principled guidance. The bound sheds light on questions of what information to seek, how to seek that information, and it what information to retain. To illustrate concepts, we design simple agents that build on them and present computational results that demonstrate improvements in data efficiency.
Simple Agent, Complex Environment: Efficient Reinforcement Learning with Agent State
Mar 08, 2021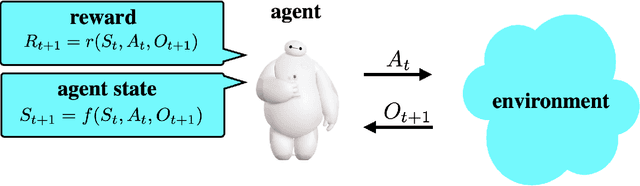
We design a simple reinforcement learning agent that, with a specification only of agent state dynamics and a reward function, can operate with some degree of competence in any environment. The agent maintains only visitation counts and value estimates for each agent-state-action pair. The value function is updated incrementally in response to temporal differences and optimistic boosts that encourage exploration. The agent executes actions that are greedy with respect to this value function. We establish a regret bound demonstrating convergence to near-optimal per-period performance, where the time taken to achieve near-optimality is polynomial in the number of agent states and actions, as well as the reward mixing time of the best policy within the reference policy class, which is comprised of those that depend on history only through agent state. Notably, there is no further dependence on the number of environment states or mixing times associated with other policies or statistics of history. Our result sheds light on the potential benefits of (deep) representation learning, which has demonstrated the capability to extract compact and relevant features from high-dimensional interaction histories.
A Bit Better? Quantifying Information for Bandit Learning
Feb 18, 2021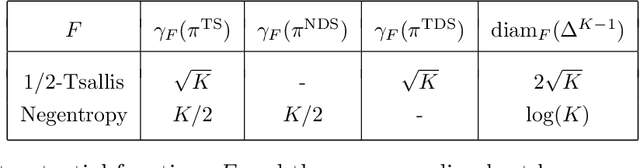
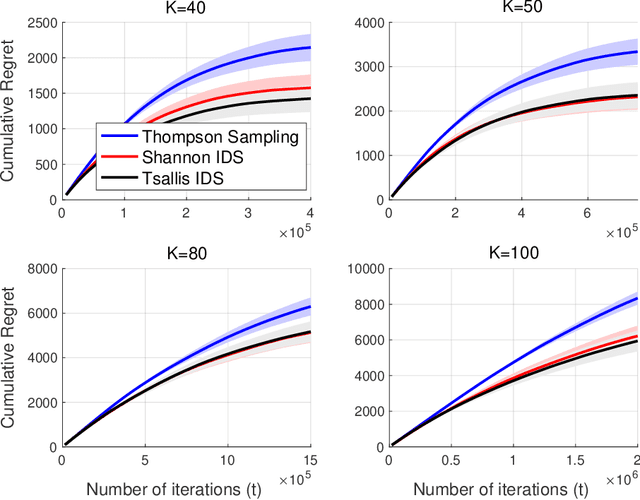
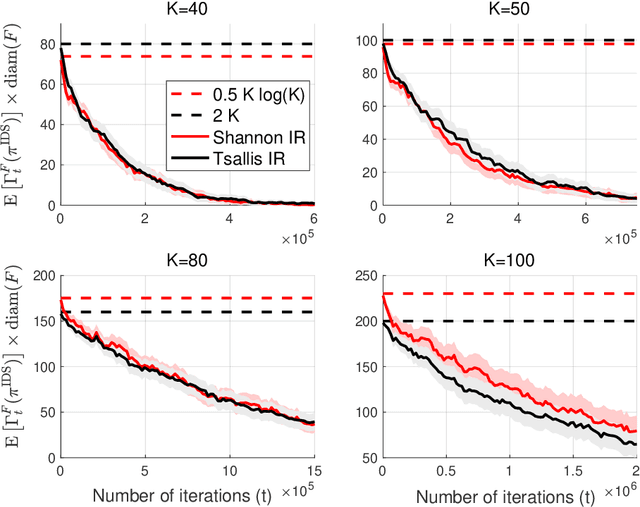
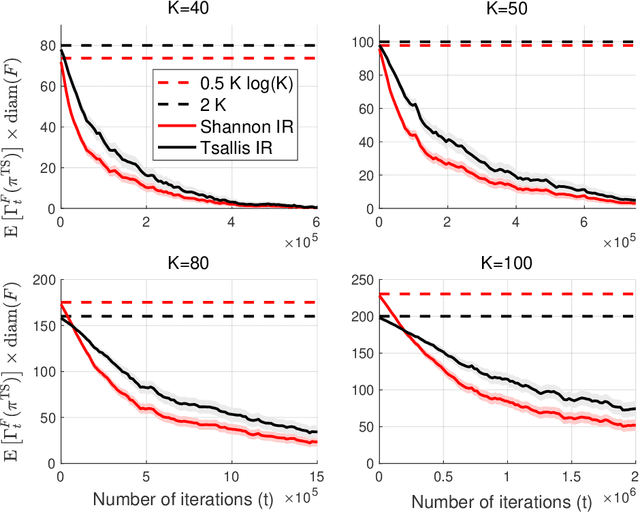
The information ratio offers an approach to assessing the efficacy with which an agent balances between exploration and exploitation. Originally, this was defined to be the ratio between squared expected regret and the mutual information between the environment and action-observation pair, which represents a measure of information gain. Recent work has inspired consideration of alternative information measures, particularly for use in analysis of bandit learning algorithms to arrive at tighter regret bounds. We investigate whether quantification of information via such alternatives can improve the realized performance of information-directed sampling, which aims to minimize the information ratio.
Deciding What to Learn: A Rate-Distortion Approach
Jan 15, 2021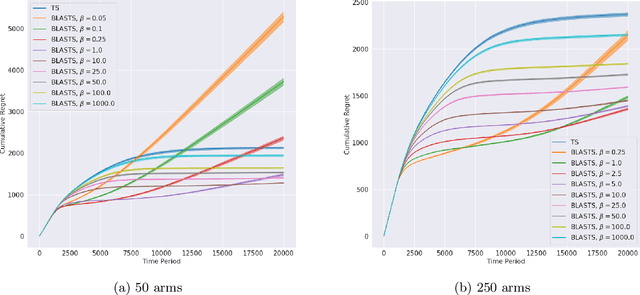
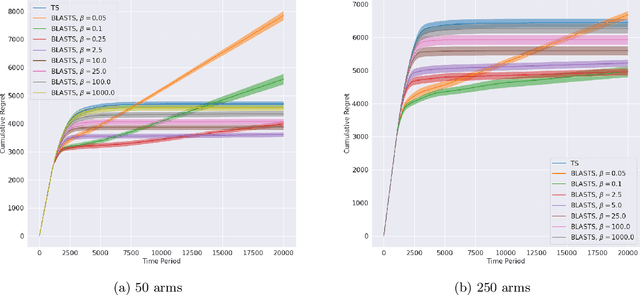
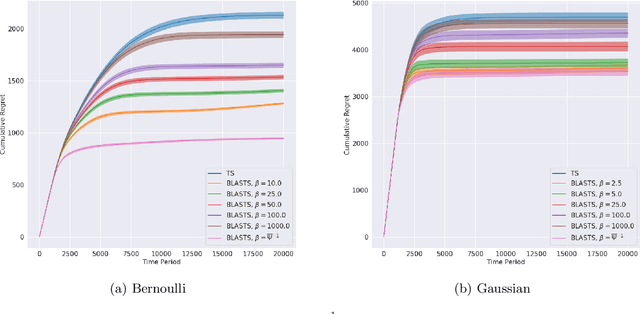
Agents that learn to select optimal actions represent a prominent focus of the sequential decision-making literature. In the face of a complex environment or constraints on time and resources, however, aiming to synthesize such an optimal policy can become infeasible. These scenarios give rise to an important trade-off between the information an agent must acquire to learn and the sub-optimality of the resulting policy. While an agent designer has a preference for how this trade-off is resolved, existing approaches further require that the designer translate these preferences into a fixed learning target for the agent. In this work, leveraging rate-distortion theory, we automate this process such that the designer need only express their preferences via a single hyperparameter and the agent is endowed with the ability to compute its own learning targets that best achieve the desired trade-off. We establish a general bound on expected discounted regret for an agent that decides what to learn in this manner along with computational experiments that illustrate the expressiveness of designer preferences and even show improvements over Thompson sampling in identifying an optimal policy.
Randomized Value Functions via Posterior State-Abstraction Sampling
Oct 05, 2020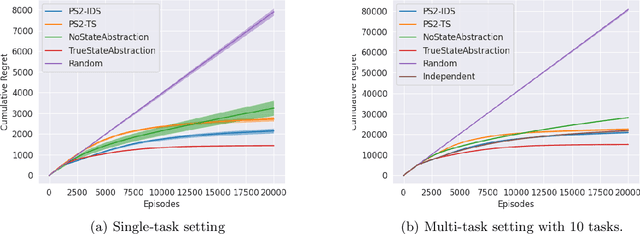
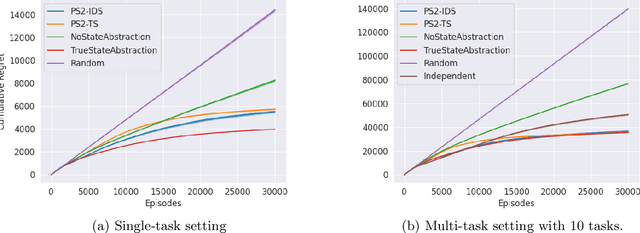
State abstraction has been an essential tool for dramatically improving the sample efficiency of reinforcement-learning algorithms. Indeed, by exposing and accentuating various types of latent structure within the environment, different classes of state abstraction have enabled improved theoretical guarantees and empirical performance. When dealing with state abstractions that capture structure in the value function, however, a standard assumption is that the true abstraction has been supplied or unrealistically computed a priori, leaving open the question of how to efficiently uncover such latent structure while jointly seeking out optimal behavior. Taking inspiration from the bandit literature, we propose that an agent seeking out latent task structure must explicitly represent and maintain its uncertainty over that structure as part of its overall uncertainty about the environment. We introduce a practical algorithm for doing this using two posterior distributions over state abstractions and abstract-state values. In empirically validating our approach, we find that substantial performance gains lie in the multi-task setting where tasks share a common, low-dimensional representation.
Hypermodels for Exploration
Jun 12, 2020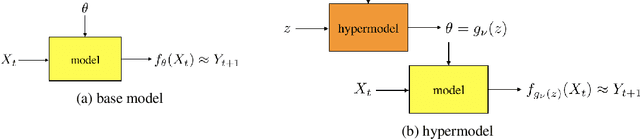
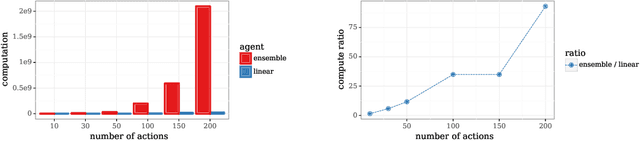
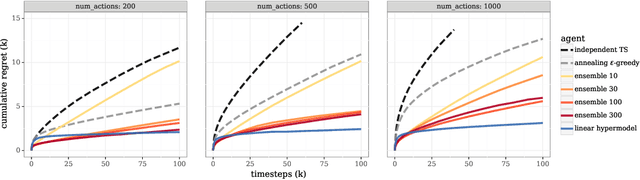
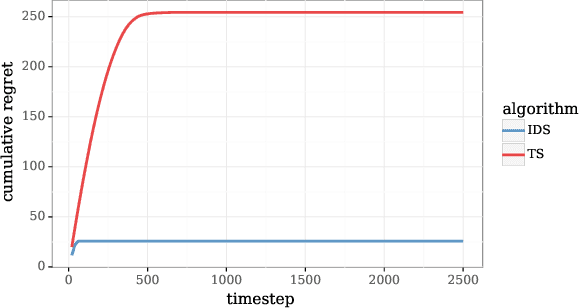
We study the use of hypermodels to represent epistemic uncertainty and guide exploration. This generalizes and extends the use of ensembles to approximate Thompson sampling. The computational cost of training an ensemble grows with its size, and as such, prior work has typically been limited to ensembles with tens of elements. We show that alternative hypermodels can enjoy dramatic efficiency gains, enabling behavior that would otherwise require hundreds or thousands of elements, and even succeed in situations where ensemble methods fail to learn regardless of size. This allows more accurate approximation of Thompson sampling as well as use of more sophisticated exploration schemes. In particular, we consider an approximate form of information-directed sampling and demonstrate performance gains relative to Thompson sampling. As alternatives to ensembles, we consider linear and neural network hypermodels, also known as hypernetworks. We prove that, with neural network base models, a linear hypermodel can represent essentially any distribution over functions, and as such, hypernetworks are no more expressive.