 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkip-gram word embeddings in hyperbolic space
Aug 30, 2018
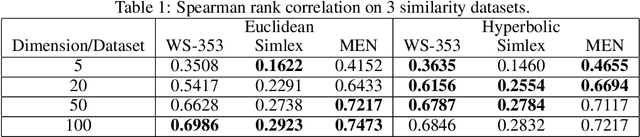
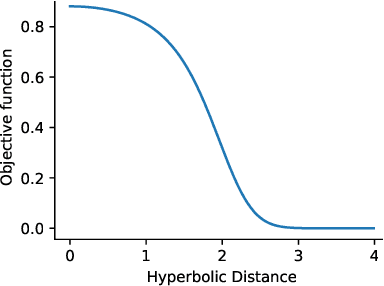
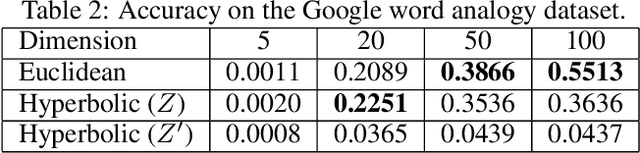
Embeddings of tree-like graphs in hyperbolic space were recently shown to surpass their Euclidean counterparts in performance by a large margin. Inspired by these results, we present an algorithm for learning word embeddings in hyperbolic space from free text. An objective function based on the hyperbolic distance is derived and included in the skip-gram architecture from word2vec. The hyperbolic word embeddings are then evaluated on word similarity and analogy benchmarks. The results demonstrate the potential of hyperbolic word embeddings, particularly in low dimensions, though without clear superiority over their Euclidean counterparts. We further discuss problems in the formulation of the analogy task resulting from the curvature of hyperbolic space.
Controlled Experiments for Word Embeddings
Dec 14, 2015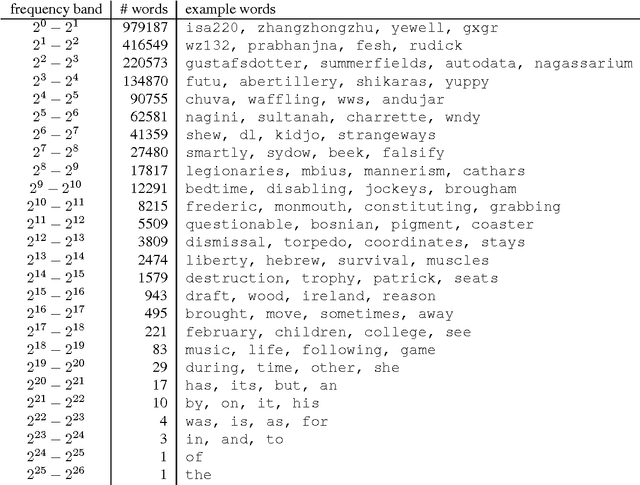

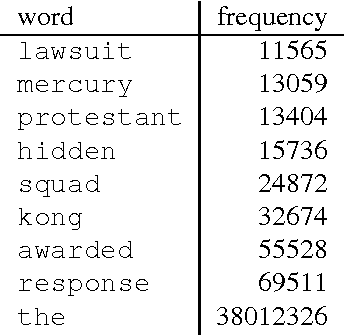
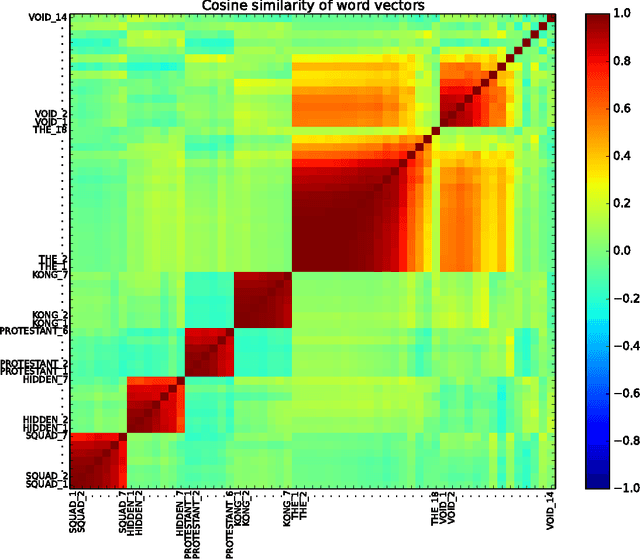
An experimental approach to studying the properties of word embeddings is proposed. Controlled experiments, achieved through modifications of the training corpus, permit the demonstration of direct relations between word properties and word vector direction and length. The approach is demonstrated using the word2vec CBOW model with experiments that independently vary word frequency and word co-occurrence noise. The experiments reveal that word vector length depends more or less linearly on both word frequency and the level of noise in the co-occurrence distribution of the word. The coefficients of linearity depend upon the word. The special point in feature space, defined by the (artificial) word with pure noise in its co-occurrence distribution, is found to be small but non-zero.
Measuring Word Significance using Distributed Representations of Words
Aug 10, 2015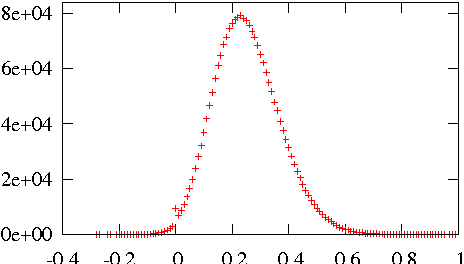

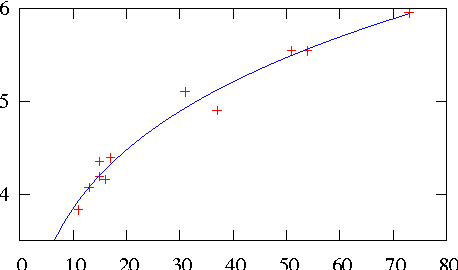
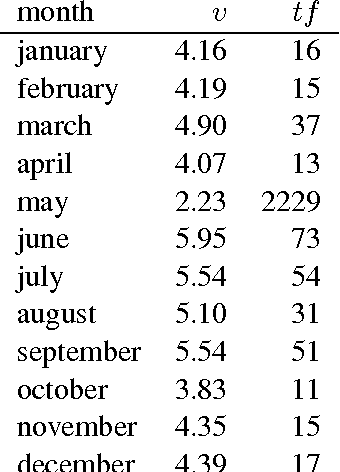
Distributed representations of words as real-valued vectors in a relatively low-dimensional space aim at extracting syntactic and semantic features from large text corpora. A recently introduced neural network, named word2vec (Mikolov et al., 2013a; Mikolov et al., 2013b), was shown to encode semantic information in the direction of the word vectors. In this brief report, it is proposed to use the length of the vectors, together with the term frequency, as measure of word significance in a corpus. Experimental evidence using a domain-specific corpus of abstracts is presented to support this proposal. A useful visualization technique for text corpora emerges, where words are mapped onto a two-dimensional plane and automatically ranked by significance.