 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisrupting Cognitive Passivity: Rethinking AI-Assisted Data Literacy through Cognitive Alignment
Apr 03, 2026AI chatbots are increasingly stepping into roles as collaborators or teachers in analyzing, visualizing, and reasoning through data and domain problem. Yet, AI's default assistant mode with its comprehensive and one-off responses may undermine opportunities for practitioners to develop literacy through their own thinking, inducing cognitive passivity. Drawing on evidence from empirical studies and theories, we argue that disrupting cognitive passivity necessitates a nuanced approach: rather than simply making AI promote deliberative thinking, there is a need for more dynamic and adaptive strategy through cognitive alignment -- a framework that characterizes effective human-AI interaction as a function of alignment between users' cognitive demand and AI's interaction mode. In the framework, we provide the mapping between AI's interaction mode (transmissive or deliberative) and users' cognitive demand (receptive or deliberative), otherwise leading to either cognitive passivity or friction. We further discuss implications and offer open questions for future research on data literacy.
From Answer Givers to Design Mentors: Guiding LLMs with the Cognitive Apprenticeship Model
Jan 27, 2026Design feedback helps practitioners improve their artifacts while also fostering reflection and design reasoning. Large Language Models (LLMs) such as ChatGPT can support design work, but often provide generic, one-off suggestions that limit reflective engagement. We investigate how to guide LLMs to act as design mentors by applying the Cognitive Apprenticeship Model, which emphasizes demonstrating reasoning through six methods: modeling, coaching, scaffolding, articulation, reflection, and exploration. We operationalize these instructional methods through structured prompting and evaluate them in a within-subjects study with data visualization practitioners. Participants interacted with both a baseline LLM and an instructional LLM designed with cognitive apprenticeship prompts. Surveys, interviews, and conversational log analyses compared experiences across conditions. Our findings show that cognitively informed prompts elicit deeper design reasoning and more reflective feedback exchanges, though the baseline is sometimes preferred depending on task types or experience levels. We distill design considerations for AI-assisted feedback systems that foster reflective practice.
Investigating the Capabilities and Limitations of Machine Learning for Identifying Bias in English Language Data with Information and Heritage Professionals
Apr 01, 2025Despite numerous efforts to mitigate their biases, ML systems continue to harm already-marginalized people. While predominant ML approaches assume bias can be removed and fair models can be created, we show that these are not always possible, nor desirable, goals. We reframe the problem of ML bias by creating models to identify biased language, drawing attention to a dataset's biases rather than trying to remove them. Then, through a workshop, we evaluated the models for a specific use case: workflows of information and heritage professionals. Our findings demonstrate the limitations of ML for identifying bias due to its contextual nature, the way in which approaches to mitigating it can simultaneously privilege and oppress different communities, and its inevitability. We demonstrate the need to expand ML approaches to bias and fairness, providing a mixed-methods approach to investigating the feasibility of removing bias or achieving fairness in a given ML use case.
ChatGPT in Data Visualization Education: A Student Perspective
May 01, 2024



Unlike traditional educational chatbots that rely on pre-programmed responses, large-language model-driven chatbots, such as ChatGPT, demonstrate remarkable versatility and have the potential to serve as a dynamic resource for addressing student needs from understanding advanced concepts to solving complex problems. This work explores the impact of such technology on student learning in an interdisciplinary, project-oriented data visualization course. Throughout the semester, students engaged with ChatGPT across four distinct projects, including data visualizations and implementing them using a variety of tools including Tableau, D3, and Vega-lite. We collected conversation logs and reflection surveys from the students after each assignment. In addition, we conducted interviews with selected students to gain deeper insights into their overall experiences with ChatGPT. Our analysis examined the advantages and barriers of using ChatGPT, students' querying behavior, the types of assistance sought, and its impact on assignment outcomes and engagement. Based on the findings, we discuss design considerations for an educational solution that goes beyond the basic interface of ChatGPT, specifically tailored for data visualization education.
Feature-Action Design Patterns for Storytelling Visualizations with Time Series Data
Feb 05, 2024



We present a method to create storytelling visualization with time series data. Many personal decisions nowadays rely on access to dynamic data regularly, as we have seen during the COVID-19 pandemic. It is thus desirable to construct storytelling visualization for dynamic data that is selected by an individual for a specific context. Because of the need to tell data-dependent stories, predefined storyboards based on known data cannot accommodate dynamic data easily nor scale up to many different individuals and contexts. Motivated initially by the need to communicate time series data during the COVID-19 pandemic, we developed a novel computer-assisted method for meta-authoring of stories, which enables the design of storyboards that include feature-action patterns in anticipation of potential features that may appear in dynamically arrived or selected data. In addition to meta-storyboards involving COVID-19 data, we also present storyboards for telling stories about progress in a machine learning workflow. Our approach is complementary to traditional methods for authoring storytelling visualization, and provides an efficient means to construct data-dependent storyboards for different data-streams of similar contexts.
Situated Data, Situated Systems: A Methodology to Engage with Power Relations in Natural Language Processing Research
Nov 11, 2020
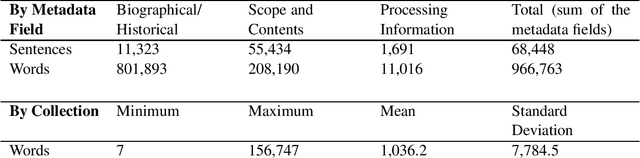
We propose a bias-aware methodology to engage with power relations in natural language processing (NLP) research. NLP research rarely engages with bias in social contexts, limiting its ability to mitigate bias. While researchers have recommended actions, technical methods, and documentation practices, no methodology exists to integrate critical reflections on bias with technical NLP methods. In this paper, after an extensive and interdisciplinary literature review, we contribute a bias-aware methodology for NLP research. We also contribute a definition of biased text, a discussion of the implications of biased NLP systems, and a case study demonstrating how we are executing the bias-aware methodology in research on archival metadata descriptions.