 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorised Neural Relational Inference for Multi-Interaction Systems
May 21, 2019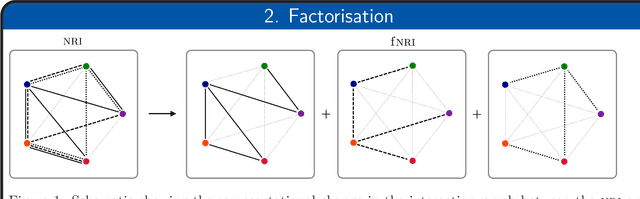
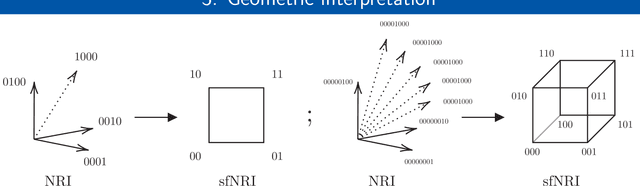
Many complex natural and cultural phenomena are well modelled by systems of simple interactions between particles. A number of architectures have been developed to articulate this kind of structure, both implicitly and explicitly. We consider an unsupervised explicit model, the NRI model, and make a series of representational adaptations and physically motivated changes. Most notably we factorise the inferred latent interaction graph into a multiplex graph, allowing each layer to encode for a different interaction-type. This fNRI model is smaller in size and significantly outperforms the original in both edge and trajectory prediction, establishing a new state-of-the-art. We also present a simplified variant of our model, which demonstrates the NRI's formulation as a variational auto-encoder is not necessary for good performance, and make an adaptation to the NRI's training routine, significantly improving its ability to model complex physical dynamical systems.
On Graph Classification Networks, Datasets and Baselines
May 12, 2019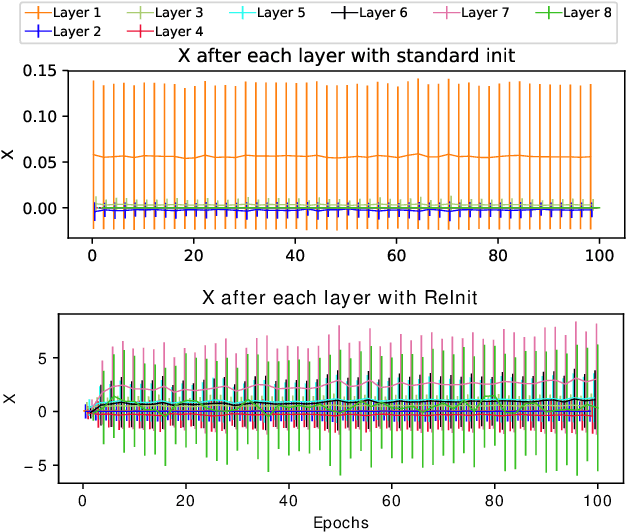
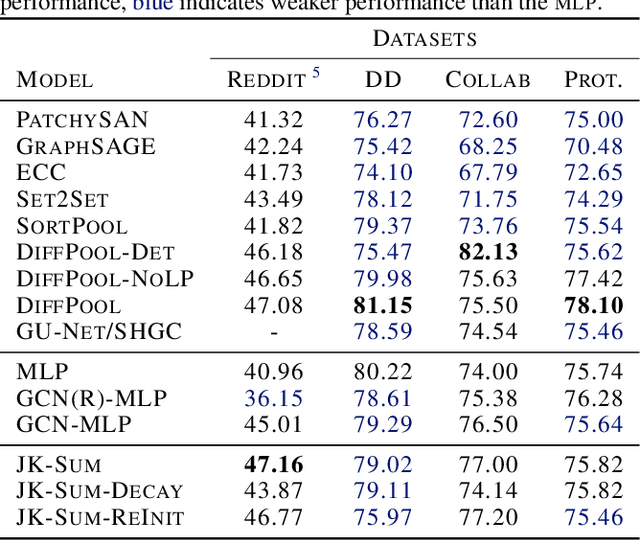
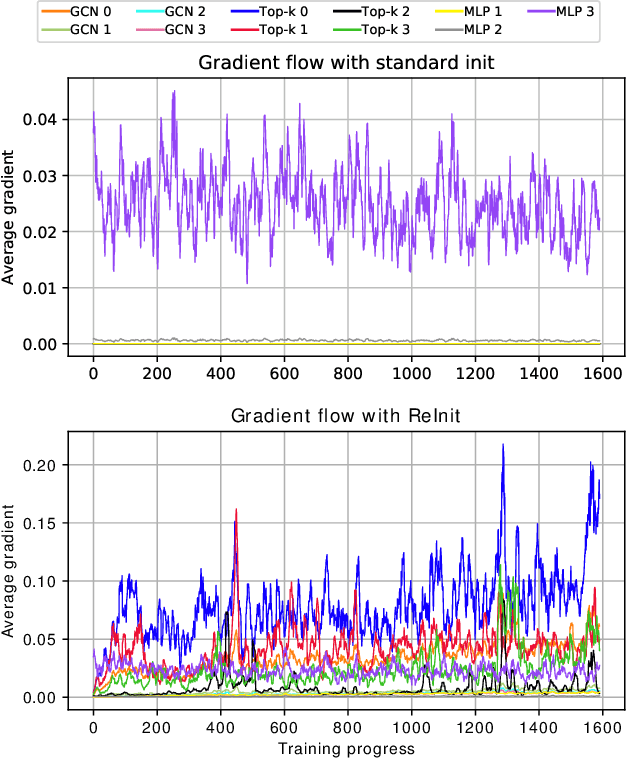
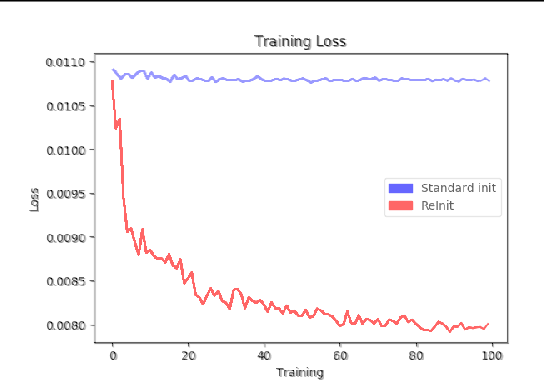
Graph classification receives a great deal of attention from the non-Euclidean machine learning community. Recent advances in graph coarsening have enabled the training of deeper networks and produced new state-of-the-art results in many benchmark tasks. We examine how these architectures train and find that performance is highly-sensitive to initialisation and depends strongly on jumping-knowledge structures. We then show that, despite the great complexity of these models, competitive performance is achieved by the simplest of models -- structure-blind MLP, single-layer GCN and fixed-weight GCN -- and propose these be included as baselines in future.
Clique pooling for graph classification
Apr 09, 2019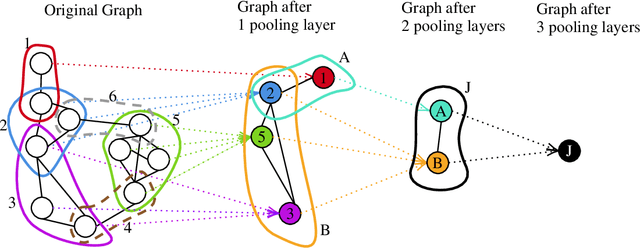
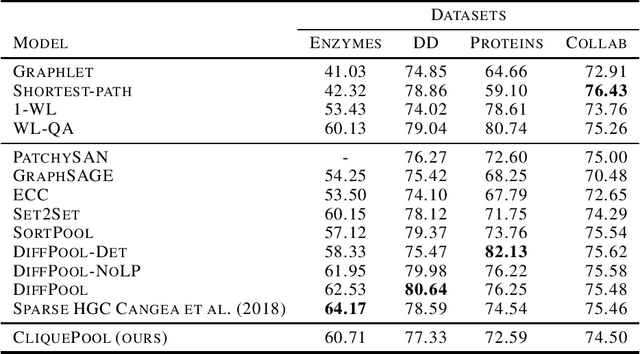
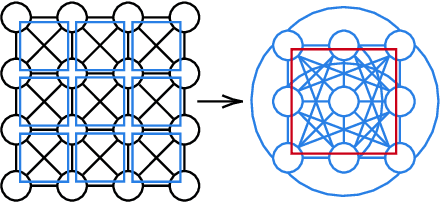
We propose a novel graph pooling operation using cliques as the unit pool. As this approach is purely topological, rather than featural, it is more readily interpretable, a better analogue to image coarsening than filtering or pruning techniques, and entirely nonparametric. The operation is implemented within graph convolution network (GCN) and GraphSAGE architectures and tested against standard graph classification benchmarks. In addition, we explore the backwards compatibility of the pooling to regular graphs, demonstrating competitive performance when replacing two-by-two pooling in standard convolutional neural networks (CNNs) with our mechanism.
Introducing Curvature to the Label Space
Oct 22, 2018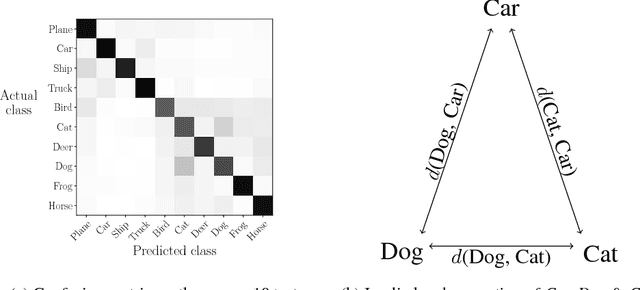
One-hot encoding is a labelling system that embeds classes as standard basis vectors in a label space. Despite seeing near-universal use in supervised categorical classification tasks, the scheme is problematic in its geometric implication that, as all classes are equally distant, all classes are equally different. This is inconsistent with most, if not all, real-world tasks due to the prevalence of ancestral and convergent relationships generating a varying degree of morphological similarity across classes. We address this issue by introducing curvature to the label-space using a metric tensor as a self-regulating method that better represents these relationships as a bolt-on, learning-algorithm agnostic solution. We propose both general constraints and specific statistical parameterizations of the metric and identify a direction for future research using autoencoder-based parameterizations.