 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Method for Cross-Lingual-based Semantic Role Labeling
Aug 28, 2024



Semantic role labeling is a crucial task in natural language processing, enabling better comprehension of natural language. However, the lack of annotated data in multiple languages has posed a challenge for researchers. To address this, a deep learning algorithm based on model transfer has been proposed. The algorithm utilizes a dataset consisting of the English portion of CoNLL2009 and a corpus of semantic roles in Persian. To optimize the efficiency of training, only ten percent of the educational data from each language is used. The results of the proposed model demonstrate significant improvements compared to Niksirt et al.'s model. In monolingual mode, the proposed model achieved a 2.05 percent improvement on F1-score, while in cross-lingual mode, the improvement was even more substantial, reaching 6.23 percent. Worth noting is that the compared model only trained two of the four stages of semantic role labeling and employed golden data for the remaining two stages. This suggests that the actual superiority of the proposed model surpasses the reported numbers by a significant margin. The development of cross-lingual methods for semantic role labeling holds promise, particularly in addressing the scarcity of annotated data for various languages. These advancements pave the way for further research in understanding and processing natural language across different linguistic contexts.
A Strategy for Implementing description Temporal Dynamic Algorithms in Dynamic Knowledge Graphs by SPIN
Jan 20, 2024



Planning and reasoning about actions and processes, in addition to reasoning about propositions, are important issues in recent logical and computer science studies. The widespread use of actions in everyday life such as IoT, semantic web services, etc., and the limitations and issues in the action formalisms are two factors that lead us to study how actions are represented. Since 2007, there have been some ideas to integrate Description Logic (DL) and action formalisms for representing both static and dynamic knowledge. Meanwhile, time is an important factor in dynamic situations, and actions change states over time. In this study, on the one hand, we examined related logical structures such as extensions of description logics (DLs), temporal formalisms, and action formalisms. On the other hand, we analyzed possible tools for designing and developing the Knowledge and Action Base (KAB). For representation and reasoning about actions, we embedded actions into DLs (such as Dynamic-ALC and its extensions). We propose a terminable algorithm for action projection, planning, checking the satisfiability, consistency, realizability, and executability, and also querying from KAB. Actions in this framework were modeled with SPIN and added to state space. This framework has also been implemented as a plugin for the Prot\'eg\'e ontology editor. During the last two decades, various algorithms have been presented, but due to the high computational complexity, we face many problems in implementing dynamic ontologies. In addition, an algorithm to detect the inconsistency of actions' effects was not explicitly stated. In the proposed strategy, the interactions of actions with other parts of modeled knowledge, and a method to check consistency between the effects of actions are presented. With this framework, the ramification problem can be well handled in future works.
PersianLLaMA: Towards Building First Persian Large Language Model
Dec 25, 2023Despite the widespread use of the Persian language by millions globally, limited efforts have been made in natural language processing for this language. The use of large language models as effective tools in various natural language processing tasks typically requires extensive textual data and robust hardware resources. Consequently, the scarcity of Persian textual data and the unavailability of powerful hardware resources have hindered the development of large language models for Persian. This paper introduces the first large Persian language model, named PersianLLaMA, trained on a collection of Persian texts and datasets. This foundational model comes in two versions, with 7 and 13 billion parameters, trained on formal and colloquial Persian texts using two different approaches. PersianLLaMA has been evaluated for natural language generation tasks based on the latest evaluation methods, namely using larger language models, and for natural language understanding tasks based on automated machine metrics. The results indicate that PersianLLaMA significantly outperforms its competitors in both understanding and generating Persian text. PersianLLaMA marks an important step in the development of Persian natural language processing and can be a valuable resource for the Persian-speaking community. This large language model can be used for various natural language processing tasks, especially text generation like chatbots, question-answering, machine translation, and text summarization
Persian Semantic Role Labeling Using Transfer Learning and BERT-Based Models
Jun 17, 2023



Semantic role labeling (SRL) is the process of detecting the predicate-argument structure of each predicate in a sentence. SRL plays a crucial role as a pre-processing step in many NLP applications such as topic and concept extraction, question answering, summarization, machine translation, sentiment analysis, and text mining. Recently, in many languages, unified SRL dragged lots of attention due to its outstanding performance, which is the result of overcoming the error propagation problem. However, regarding the Persian language, all previous works have focused on traditional methods of SRL leading to a drop in accuracy and imposing expensive feature extraction steps in terms of financial resources, time and energy consumption. In this work, we present an end-to-end SRL method that not only eliminates the need for feature extraction but also outperforms existing methods in facing new samples in practical situations. The proposed method does not employ any auxiliary features and shows more than 16 (83.16) percent improvement in accuracy against previous methods in similar circumstances.
PESTS: Persian_English Cross Lingual Corpus for Semantic Textual Similarity
May 13, 2023One of the components of natural language processing that has received a lot of investigation recently is semantic textual similarity. In computational linguistics and natural language processing, assessing the semantic similarity of words, phrases, paragraphs, and texts is crucial. Calculating the degree of semantic resemblance between two textual pieces, paragraphs, or phrases provided in both monolingual and cross-lingual versions is known as semantic similarity. Cross lingual semantic similarity requires corpora in which there are sentence pairs in both the source and target languages with a degree of semantic similarity between them. Many existing cross lingual semantic similarity models use a machine translation due to the unavailability of cross lingual semantic similarity dataset, which the propagation of the machine translation error reduces the accuracy of the model. On the other hand, when we want to use semantic similarity features for machine translation the same machine translations should not be used for semantic similarity. For Persian, which is one of the low resource languages, no effort has been made in this regard and the need for a model that can understand the context of two languages is felt more than ever. In this article, the corpus of semantic textual similarity between sentences in Persian and English languages has been produced for the first time by using linguistic experts. We named this dataset PESTS (Persian English Semantic Textual Similarity). This corpus contains 5375 sentence pairs. Also, different models based on transformers have been fine-tuned using this dataset. The results show that using the PESTS dataset, the Pearson correlation of the XLM ROBERTa model increases from 85.87% to 95.62%.
Wisdom of Crowds cluster ensemble
May 13, 2016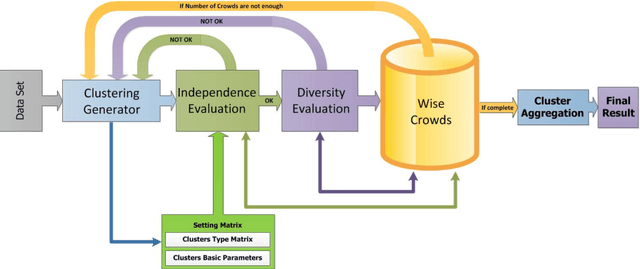

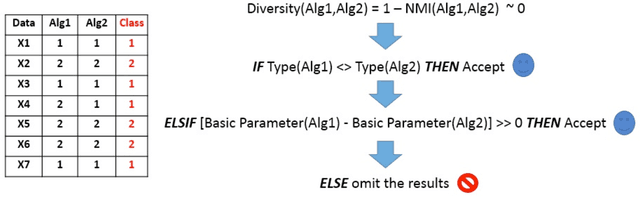
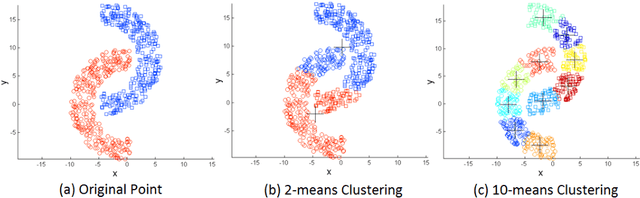
The Wisdom of Crowds is a phenomenon described in social science that suggests four criteria applicable to groups of people. It is claimed that, if these criteria are satisfied, then the aggregate decisions made by a group will often be better than those of its individual members. Inspired by this concept, we present a novel feedback framework for the cluster ensemble problem, which we call Wisdom of Crowds Cluster Ensemble (WOCCE). Although many conventional cluster ensemble methods focusing on diversity have recently been proposed, WOCCE analyzes the conditions necessary for a crowd to exhibit this collective wisdom. These include decentralization criteria for generating primary results, independence criteria for the base algorithms, and diversity criteria for the ensemble members. We suggest appropriate procedures for evaluating these measures, and propose a new measure to assess the diversity. We evaluate the performance of WOCCE against some other traditional base algorithms as well as state-of-the-art ensemble methods. The results demonstrate the efficiency of WOCCE's aggregate decision-making compared to other algorithms.