 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Loss Curvature Perspective on Training Instability in Deep Learning
Oct 08, 2021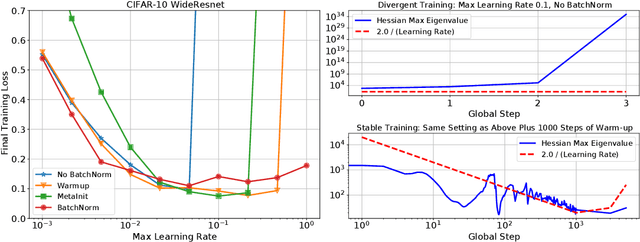

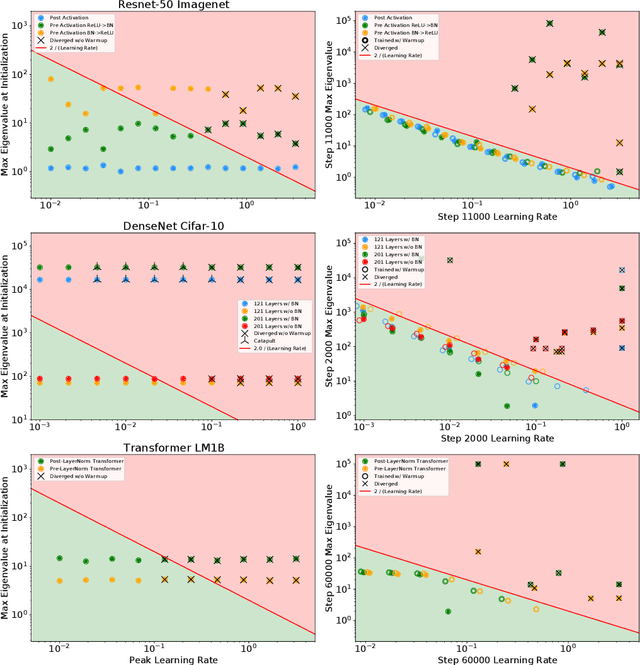

In this work, we study the evolution of the loss Hessian across many classification tasks in order to understand the effect the curvature of the loss has on the training dynamics. Whereas prior work has focused on how different learning rates affect the loss Hessian observed during training, we also analyze the effects of model initialization, architectural choices, and common training heuristics such as gradient clipping and learning rate warmup. Our results demonstrate that successful model and hyperparameter choices allow the early optimization trajectory to either avoid -- or navigate out of -- regions of high curvature and into flatter regions that tolerate a higher learning rate. Our results suggest a unifying perspective on how disparate mitigation strategies for training instability ultimately address the same underlying failure mode of neural network optimization, namely poor conditioning. Inspired by the conditioning perspective, we show that learning rate warmup can improve training stability just as much as batch normalization, layer normalization, MetaInit, GradInit, and Fixup initialization.
Scaling Laws for Neural Machine Translation
Sep 16, 2021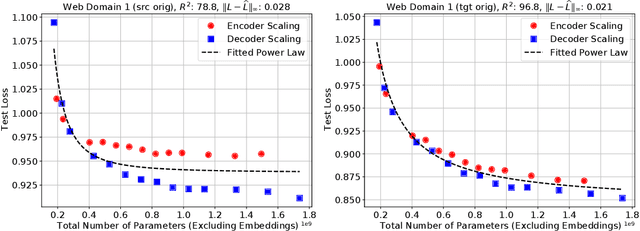
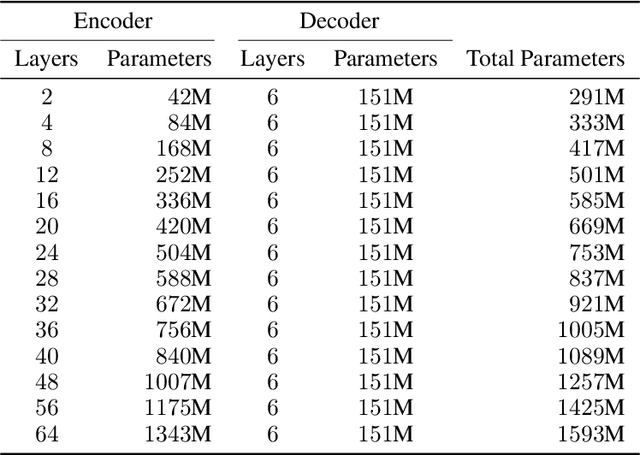
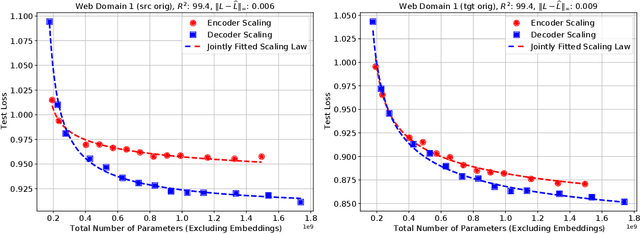
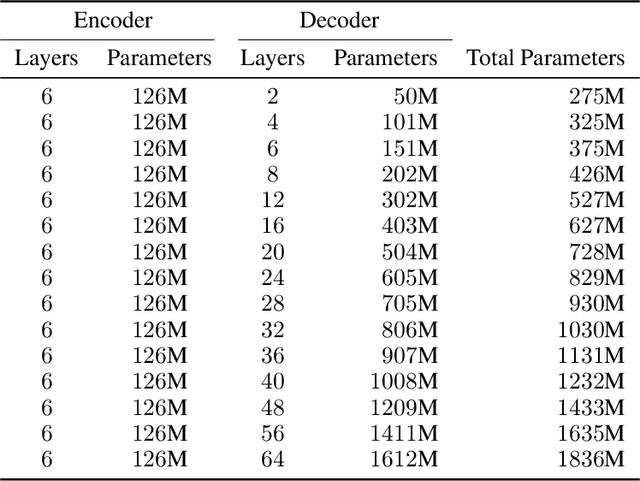
We present an empirical study of scaling properties of encoder-decoder Transformer models used in neural machine translation (NMT). We show that cross-entropy loss as a function of model size follows a certain scaling law. Specifically (i) We propose a formula which describes the scaling behavior of cross-entropy loss as a bivariate function of encoder and decoder size, and show that it gives accurate predictions under a variety of scaling approaches and languages; we show that the total number of parameters alone is not sufficient for such purposes. (ii) We observe different power law exponents when scaling the decoder vs scaling the encoder, and provide recommendations for optimal allocation of encoder/decoder capacity based on this observation. (iii) We also report that the scaling behavior of the model is acutely influenced by composition bias of the train/test sets, which we define as any deviation from naturally generated text (either via machine generated or human translated text). We observe that natural text on the target side enjoys scaling, which manifests as successful reduction of the cross-entropy loss. (iv) Finally, we investigate the relationship between the cross-entropy loss and the quality of the generated translations. We find two different behaviors, depending on the nature of the test data. For test sets which were originally translated from target language to source language, both loss and BLEU score improve as model size increases. In contrast, for test sets originally translated from source language to target language, the loss improves, but the BLEU score stops improving after a certain threshold. We release generated text from all models used in this study.
When Do Neural Networks Outperform Kernel Methods?
Jun 24, 2020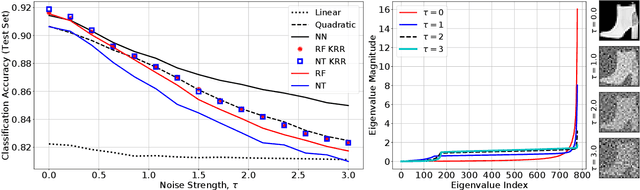

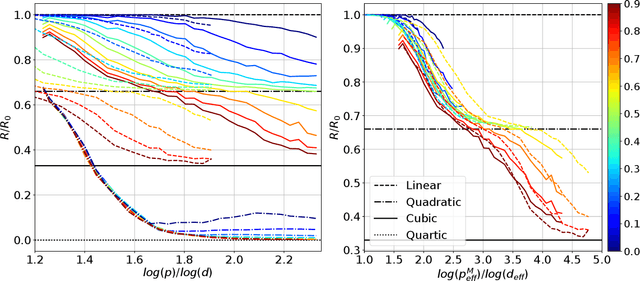
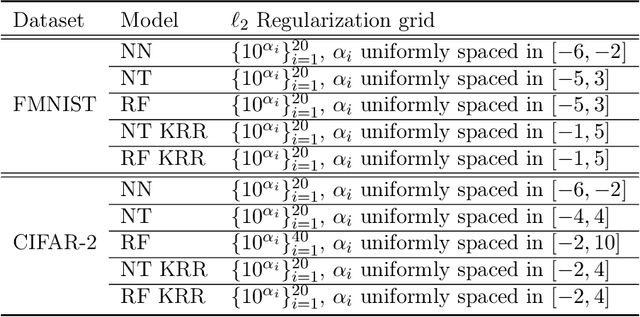
For a certain scaling of the initialization of stochastic gradient descent (SGD), wide neural networks (NN) have been shown to be well approximated by reproducing kernel Hilbert space (RKHS) methods. Recent empirical work showed that, for some classification tasks, RKHS methods can replace NNs without a large loss in performance. On the other hand, two-layers NNs are known to encode richer smoothness classes than RKHS and we know of special examples for which SGD-trained NN provably outperform RKHS. This is true even in the wide network limit, for a different scaling of the initialization. How can we reconcile the above claims? For which tasks do NNs outperform RKHS? If feature vectors are nearly isotropic, RKHS methods suffer from the curse of dimensionality, while NNs can overcome it by learning the best low-dimensional representation. Here we show that this curse of dimensionality becomes milder if the feature vectors display the same low-dimensional structure as the target function, and we precisely characterize this tradeoff. Building on these results, we present a model that can capture in a unified framework both behaviors observed in earlier work. We hypothesize that such a latent low-dimensional structure is present in image classification. We test numerically this hypothesis by showing that specific perturbations of the training distribution degrade the performances of RKHS methods much more significantly than NNs.
Limitations of Lazy Training of Two-layers Neural Networks
Jun 21, 2019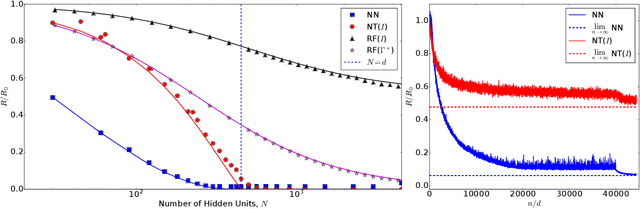
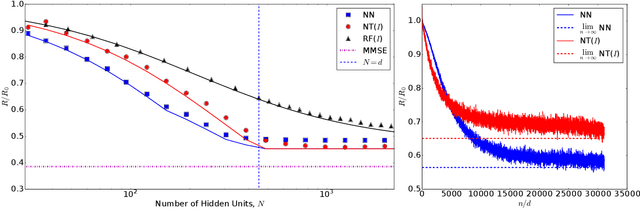
We study the supervised learning problem under either of the following two models: (1) Feature vectors ${\boldsymbol x}_i$ are $d$-dimensional Gaussians and responses are $y_i = f_*({\boldsymbol x}_i)$ for $f_*$ an unknown quadratic function; (2) Feature vectors ${\boldsymbol x}_i$ are distributed as a mixture of two $d$-dimensional centered Gaussians, and $y_i$'s are the corresponding class labels. We use two-layers neural networks with quadratic activations, and compare three different learning regimes: the random features (RF) regime in which we only train the second-layer weights; the neural tangent (NT) regime in which we train a linearization of the neural network around its initialization; the fully trained neural network (NN) regime in which we train all the weights in the network. We prove that, even for the simple quadratic model of point (1), there is a potentially unbounded gap between the prediction risk achieved in these three training regimes, when the number of neurons is smaller than the ambient dimension. When the number of neurons is larger than the number of dimensions, the problem is significantly easier and both NT and NN learning achieve zero risk.
Linearized two-layers neural networks in high dimension
Apr 27, 2019We consider the problem of learning an unknown function $f_{\star}$ on the $d$-dimensional sphere with respect to the square loss, given i.i.d. samples $\{(y_i,{\boldsymbol x}_i)\}_{i\le n}$ where ${\boldsymbol x}_i$ is a feature vector uniformly distributed on the sphere and $y_i=f_{\star}({\boldsymbol x}_i)$. We study two popular classes of models that can be regarded as linearizations of two-layers neural networks around a random initialization: (RF) The random feature model of Rahimi-Recht; (NT) The neural tangent kernel model of Jacot-Gabriel-Hongler. Both these approaches can also be regarded as randomized approximations of kernel ridge regression (with respect to different kernels), and hence enjoy universal approximation properties when the number of neurons $N$ diverges, for a fixed dimension $d$. We prove that, if both $d$ and $N$ are large, the behavior of these models is instead remarkably simpler. If $N = o(d^2)$, then RF performs no better than linear regression with respect to the raw features ${\boldsymbol x}_i$, and NT performs no better than linear regression with respect to degree-one and two monomials in the ${\boldsymbol x}_i$. More generally, if $N= o(d^{\ell+1})$ then RF fits at most a degree-$\ell$ polynomial in the raw features, and NT fits at most a degree-$(\ell+1)$ polynomial.
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density
Jan 29, 2019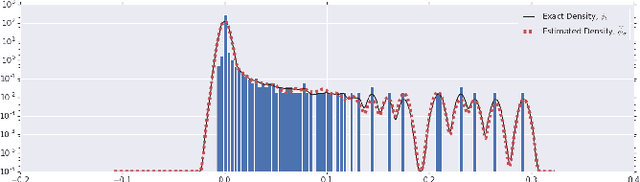
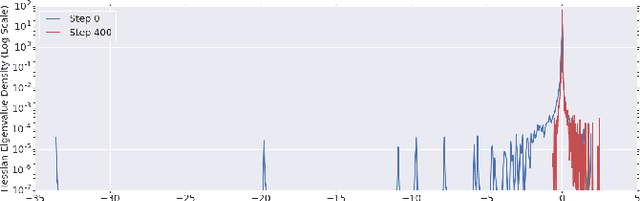
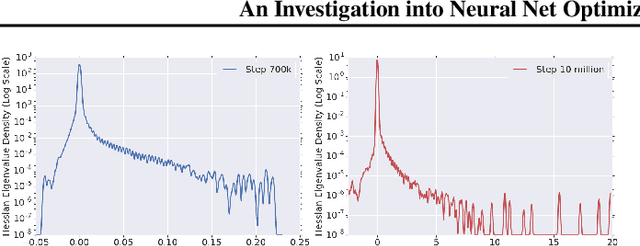
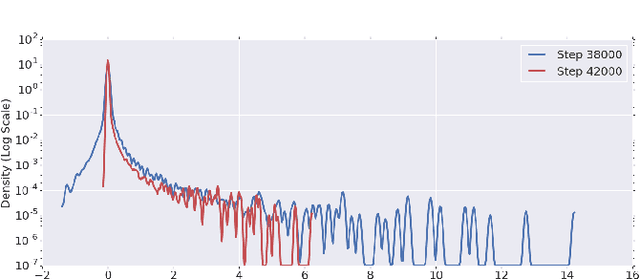
To understand the dynamics of optimization in deep neural networks, we develop a tool to study the evolution of the entire Hessian spectrum throughout the optimization process. Using this, we study a number of hypotheses concerning smoothness, curvature, and sharpness in the deep learning literature. We then thoroughly analyze a crucial structural feature of the spectra: in non-batch normalized networks, we observe the rapid appearance of large isolated eigenvalues in the spectrum, along with a surprising concentration of the gradient in the corresponding eigenspaces. In batch normalized networks, these two effects are almost absent. We characterize these effects, and explain how they affect optimization speed through both theory and experiments. As part of this work, we adapt advanced tools from numerical linear algebra that allow scalable and accurate estimation of the entire Hessian spectrum of ImageNet-scale neural networks; this technique may be of independent interest in other applications.
An Instability in Variational Inference for Topic Models
Feb 02, 2018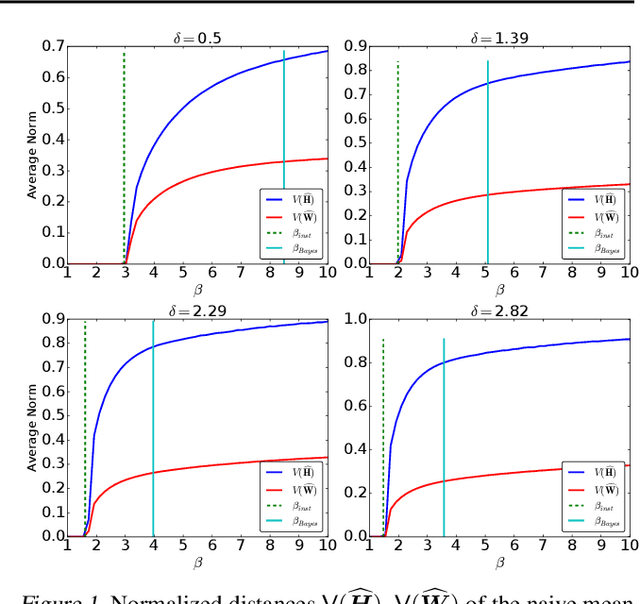
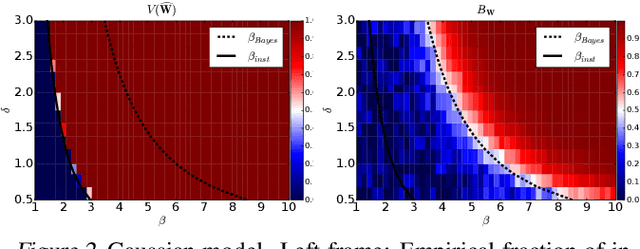
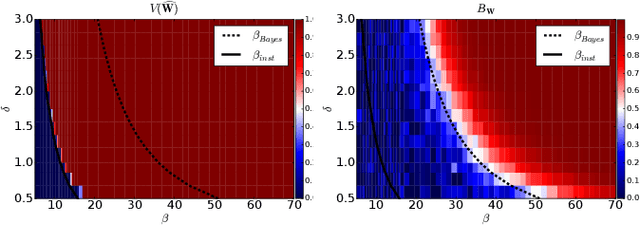
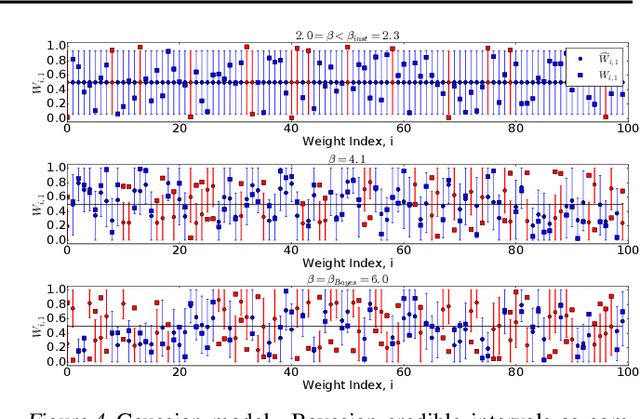
Topic models are Bayesian models that are frequently used to capture the latent structure of certain corpora of documents or images. Each data element in such a corpus (for instance each item in a collection of scientific articles) is regarded as a convex combination of a small number of vectors corresponding to `topics' or `components'. The weights are assumed to have a Dirichlet prior distribution. The standard approach towards approximating the posterior is to use variational inference algorithms, and in particular a mean field approximation. We show that this approach suffers from an instability that can produce misleading conclusions. Namely, for certain regimes of the model parameters, variational inference outputs a non-trivial decomposition into topics. However --for the same parameter values-- the data contain no actual information about the true decomposition, and hence the output of the algorithm is uncorrelated with the true topic decomposition. Among other consequences, the estimated posterior mean is significantly wrong, and estimated Bayesian credible regions do not achieve the nominal coverage. We discuss how this instability is remedied by more accurate mean field approximations.