 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Expressive Limits of Diagonal SSMs for State-Tracking
Mar 02, 2026State-Space Models (SSMs) have recently been shown to achieve strong empirical performance on a variety of long-range sequence modeling tasks while remaining efficient and highly-parallelizable. However, the theoretical understanding of their expressive power remains limited. In this work, we study the expressivity of input-Dependent Complex-valued Diagonal (DCD) SSMs on sequential state-tracking tasks. We show that single-layer DCD SSMs cannot express state-tracking of any non-Abelian group at finite precision. More generally, we show that $k$-layer DCD SSMs can express state-tracking of a group if and only if that group has a subnormal series of length $k$, with Abelian factors. That is, we identify the precise expressivity range of $k$-layer DCD SSMs within the solvable groups. Empirically, we find that multi-layer models often fail to learn state-tracking for non-Abelian groups, highlighting a gap between expressivity and learnability.
Parity Requires Unified Input Dependence and Negative Eigenvalues in SSMs
Aug 10, 2025Recent work has shown that LRNN models such as S4D, Mamba, and DeltaNet lack state-tracking capability due to either time-invariant transition matrices or restricted eigenvalue ranges. To address this, input-dependent transition matrices, particularly those that are complex or non-triangular, have been proposed to enhance SSM performance on such tasks. While existing theorems demonstrate that both input-independent and non-negative SSMs are incapable of solving simple state-tracking tasks, such as parity, regardless of depth, they do not explore whether combining these two types in a multilayer SSM could help. We investigate this question for efficient SSMs with diagonal transition matrices and show that such combinations still fail to solve parity. This implies that a recurrence layer must both be input-dependent and include negative eigenvalues. Our experiments support this conclusion by analyzing an SSM model that combines S4D and Mamba layers.
Lower and Upper Bounds on the VC-Dimension of Tensor Network Models
Jun 22, 2021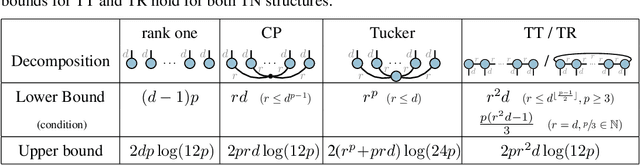
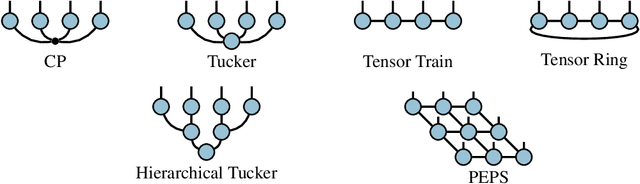
Tensor network methods have been a key ingredient of advances in condensed matter physics and have recently sparked interest in the machine learning community for their ability to compactly represent very high-dimensional objects. Tensor network methods can for example be used to efficiently learn linear models in exponentially large feature spaces [Stoudenmire and Schwab, 2016]. In this work, we derive upper and lower bounds on the VC dimension and pseudo-dimension of a large class of tensor network models for classification, regression and completion. Our upper bounds hold for linear models parameterized by arbitrary tensor network structures, and we derive lower bounds for common tensor decomposition models~(CP, Tensor Train, Tensor Ring and Tucker) showing the tightness of our general upper bound. These results are used to derive a generalization bound which can be applied to classification with low rank matrices as well as linear classifiers based on any of the commonly used tensor decomposition models. As a corollary of our results, we obtain a bound on the VC dimension of the matrix product state classifier introduced in [Stoudenmire and Schwab, 2016] as a function of the so-called bond dimension~(i.e. tensor train rank), which answers an open problem listed by Cirac, Garre-Rubio and P\'erez-Garc\'ia in [Cirac et al., 2019].