 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorralling a Band of Bandit Algorithms
Jun 06, 2017
We study the problem of combining multiple bandit algorithms (that is, online learning algorithms with partial feedback) with the goal of creating a master algorithm that performs almost as well as the best base algorithm if it were to be run on its own. The main challenge is that when run with a master, base algorithms unavoidably receive much less feedback and it is thus critical that the master not starve a base algorithm that might perform uncompetitively initially but would eventually outperform others if given enough feedback. We address this difficulty by devising a version of Online Mirror Descent with a special mirror map together with a sophisticated learning rate scheme. We show that this approach manages to achieve a more delicate balance between exploiting and exploring base algorithms than previous works yielding superior regret bounds. Our results are applicable to many settings, such as multi-armed bandits, contextual bandits, and convex bandits. As examples, we present two main applications. The first is to create an algorithm that enjoys worst-case robustness while at the same time performing much better when the environment is relatively easy. The second is to create an algorithm that works simultaneously under different assumptions of the environment, such as different priors or different loss structures.
Implicit Regularization in Matrix Factorization
May 25, 2017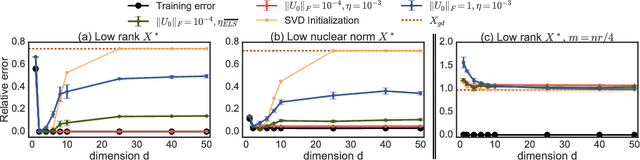
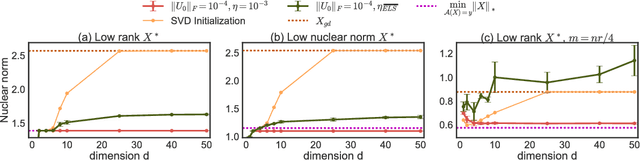


We study implicit regularization when optimizing an underdetermined quadratic objective over a matrix $X$ with gradient descent on a factorization of $X$. We conjecture and provide empirical and theoretical evidence that with small enough step sizes and initialization close enough to the origin, gradient descent on a full dimensional factorization converges to the minimum nuclear norm solution.
Geometry of Optimization and Implicit Regularization in Deep Learning
May 08, 2017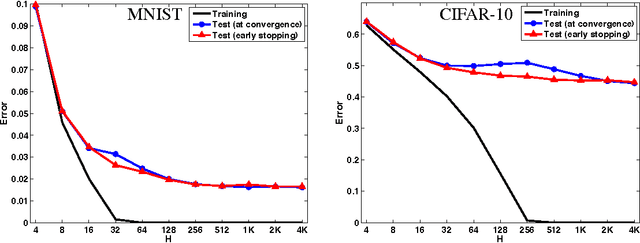
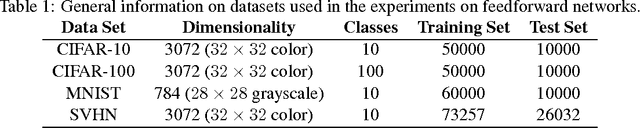
We argue that the optimization plays a crucial role in generalization of deep learning models through implicit regularization. We do this by demonstrating that generalization ability is not controlled by network size but rather by some other implicit control. We then demonstrate how changing the empirical optimization procedure can improve generalization, even if actual optimization quality is not affected. We do so by studying the geometry of the parameter space of deep networks, and devising an optimization algorithm attuned to this geometry.
Global Optimality of Local Search for Low Rank Matrix Recovery
May 27, 2016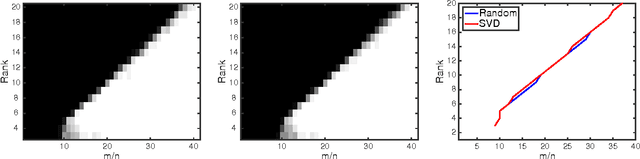
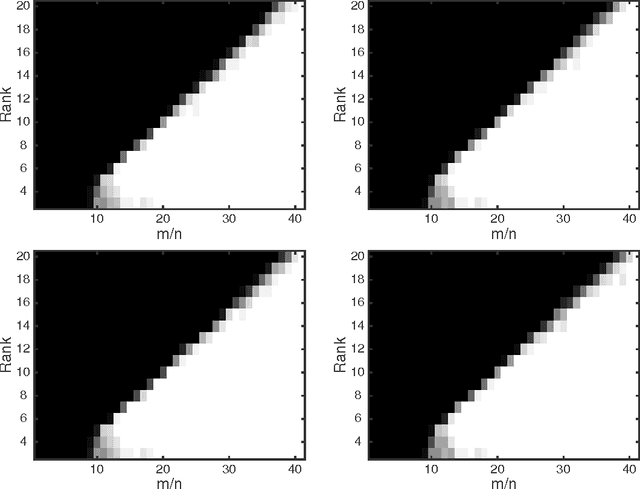
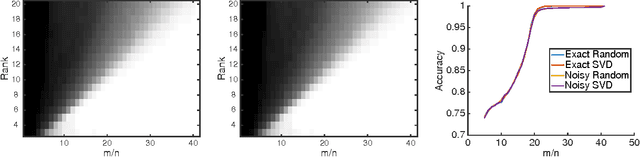
We show that there are no spurious local minima in the non-convex factorized parametrization of low-rank matrix recovery from incoherent linear measurements. With noisy measurements we show all local minima are very close to a global optimum. Together with a curvature bound at saddle points, this yields a polynomial time global convergence guarantee for stochastic gradient descent {\em from random initialization}.
Path-Normalized Optimization of Recurrent Neural Networks with ReLU Activations
May 23, 2016
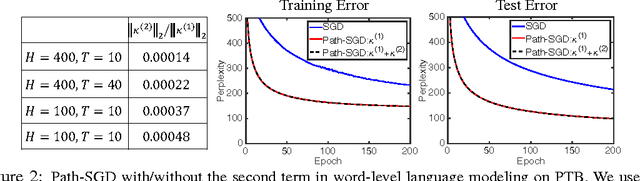
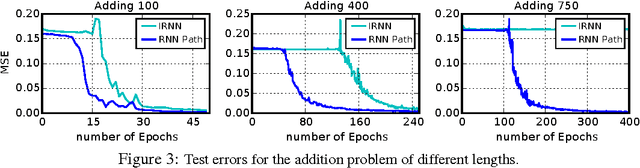
We investigate the parameter-space geometry of recurrent neural networks (RNNs), and develop an adaptation of path-SGD optimization method, attuned to this geometry, that can learn plain RNNs with ReLU activations. On several datasets that require capturing long-term dependency structure, we show that path-SGD can significantly improve trainability of ReLU RNNs compared to RNNs trained with SGD, even with various recently suggested initialization schemes.
Data-Dependent Path Normalization in Neural Networks
Jan 19, 2016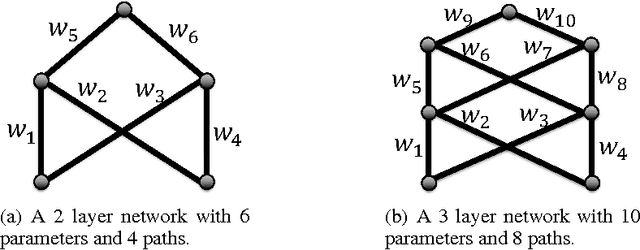
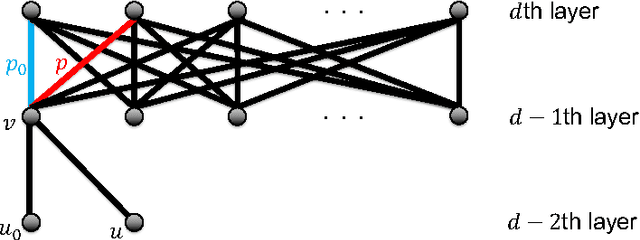
We propose a unified framework for neural net normalization, regularization and optimization, which includes Path-SGD and Batch-Normalization and interpolates between them across two different dimensions. Through this framework we investigate issue of invariance of the optimization, data dependence and the connection with natural gradients.
On Symmetric and Asymmetric LSHs for Inner Product Search
Jun 08, 2015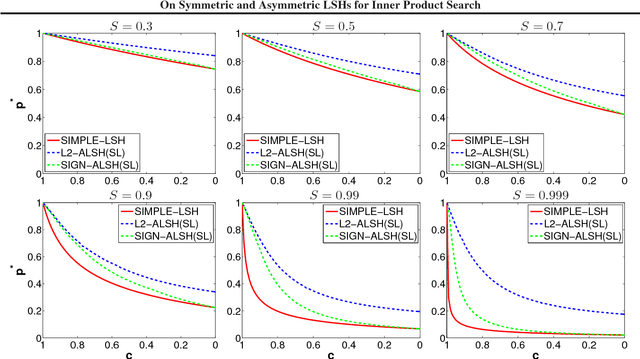
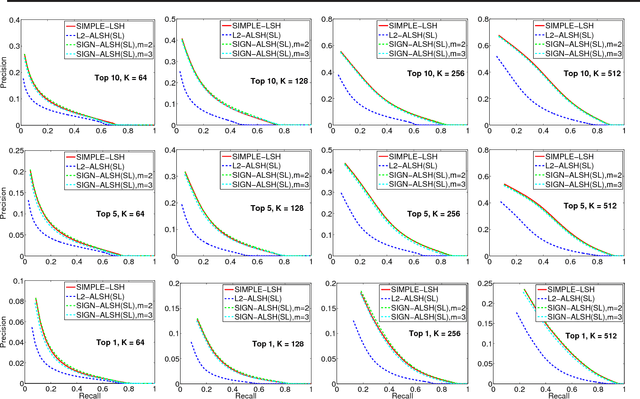
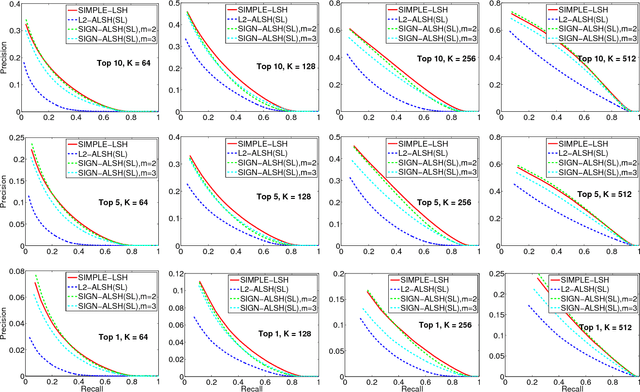
We consider the problem of designing locality sensitive hashes (LSH) for inner product similarity, and of the power of asymmetric hashes in this context. Shrivastava and Li argue that there is no symmetric LSH for the problem and propose an asymmetric LSH based on different mappings for query and database points. However, we show there does exist a simple symmetric LSH that enjoys stronger guarantees and better empirical performance than the asymmetric LSH they suggest. We also show a variant of the settings where asymmetry is in-fact needed, but there a different asymmetric LSH is required.
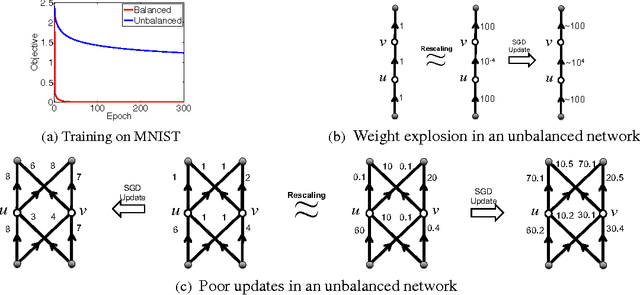
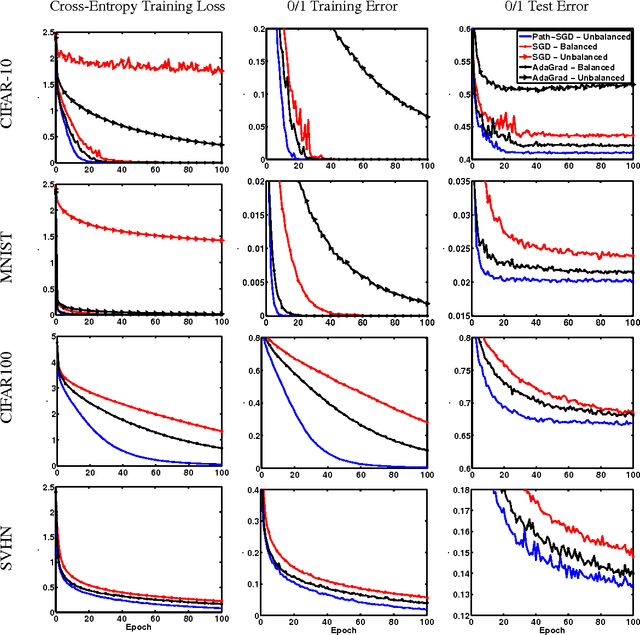
Path-SGD: Path-Normalized Optimization in Deep Neural Networks
Jun 08, 2015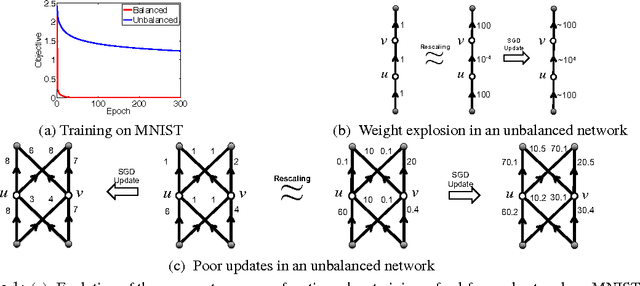
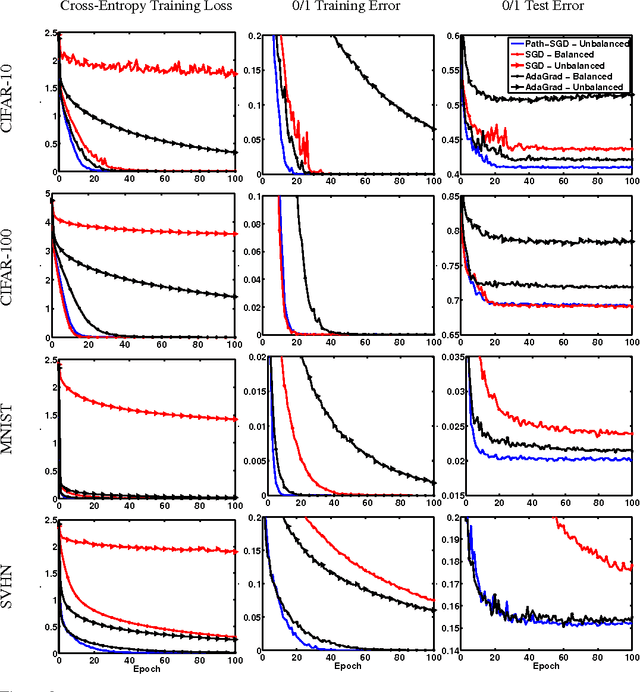
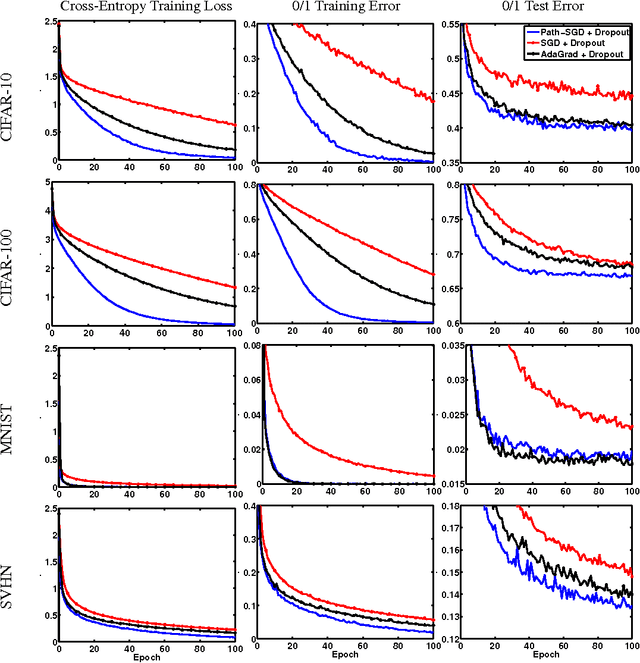
We revisit the choice of SGD for training deep neural networks by reconsidering the appropriate geometry in which to optimize the weights. We argue for a geometry invariant to rescaling of weights that does not affect the output of the network, and suggest Path-SGD, which is an approximate steepest descent method with respect to a path-wise regularizer related to max-norm regularization. Path-SGD is easy and efficient to implement and leads to empirical gains over SGD and AdaGrad.
In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning
Apr 16, 2015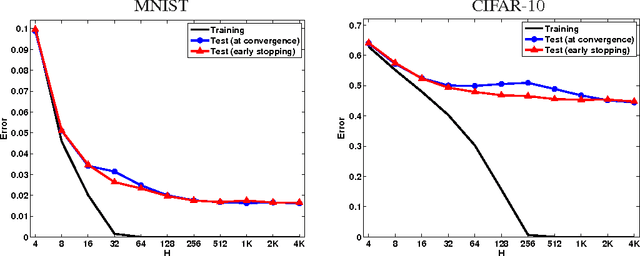
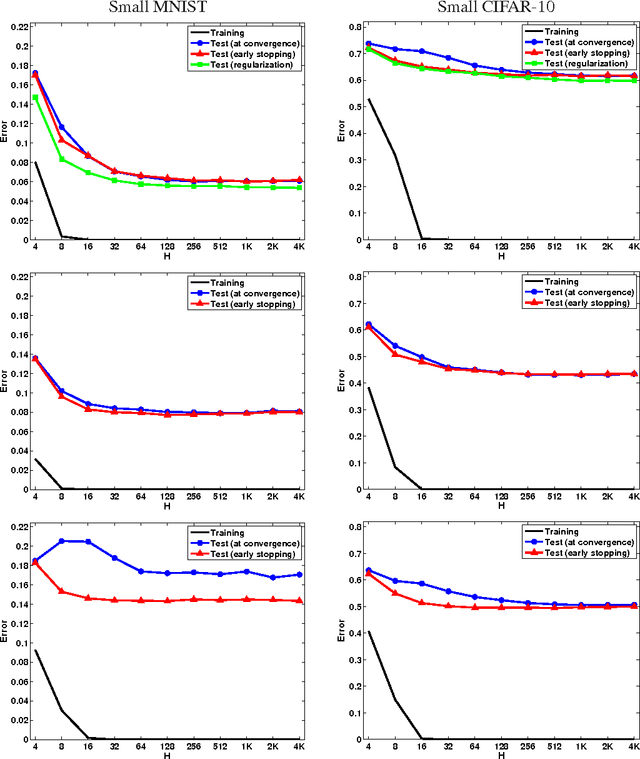
We present experiments demonstrating that some other form of capacity control, different from network size, plays a central role in learning multilayer feed-forward networks. We argue, partially through analogy to matrix factorization, that this is an inductive bias that can help shed light on deep learning.
Norm-Based Capacity Control in Neural Networks
Apr 14, 2015We investigate the capacity, convexity and characterization of a general family of norm-constrained feed-forward networks.