 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHESEIA: A community-based dataset for evaluating social biases in large language models, co-designed in real school settings in Latin America
May 30, 2025Most resources for evaluating social biases in Large Language Models are developed without co-design from the communities affected by these biases, and rarely involve participatory approaches. We introduce HESEIA, a dataset of 46,499 sentences created in a professional development course. The course involved 370 high-school teachers and 5,370 students from 189 Latin-American schools. Unlike existing benchmarks, HESEIA captures intersectional biases across multiple demographic axes and school subjects. It reflects local contexts through the lived experience and pedagogical expertise of educators. Teachers used minimal pairs to create sentences that express stereotypes relevant to their school subjects and communities. We show the dataset diversity in term of demographic axes represented and also in terms of the knowledge areas included. We demonstrate that the dataset contains more stereotypes unrecognized by current LLMs than previous datasets. HESEIA is available to support bias assessments grounded in educational communities.
A tool to overcome technical barriers for bias assessment in human language technologies
Jul 14, 2022
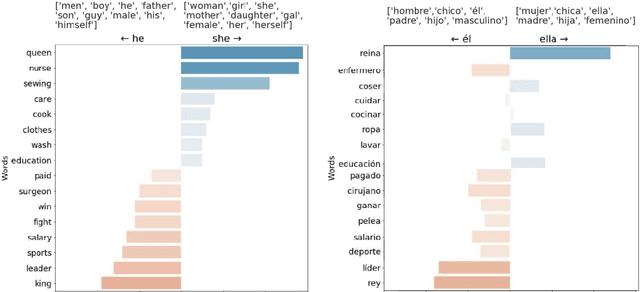

Automatic processing of language is becoming pervasive in our lives, often taking central roles in our decision making, like choosing the wording for our messages and mails, translating our readings, or even having full conversations with us. Word embeddings are a key component of modern natural language processing systems. They provide a representation of words that has boosted the performance of many applications, working as a semblance of meaning. Word embeddings seem to capture a semblance of the meaning of words from raw text, but, at the same time, they also distill stereotypes and societal biases which are subsequently relayed to the final applications. Such biases can be discriminatory. It is very important to detect and mitigate those biases, to prevent discriminatory behaviors of automated processes, which can be much more harmful than in the case of humans because their of their scale. There are currently many tools and techniques to detect and mitigate biases in word embeddings, but they present many barriers for the engagement of people without technical skills. As it happens, most of the experts in bias, either social scientists or people with deep knowledge of the context where bias is harmful, do not have such skills, and they cannot engage in the processes of bias detection because of the technical barriers. We have studied the barriers in existing tools and have explored their possibilities and limitations with different kinds of users. With this exploration, we propose to develop a tool that is specially aimed to lower the technical barriers and provide the exploration power to address the requirements of experts, scientists and people in general who are willing to audit these technologies.