 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalous Samples for Few-Shot Anomaly Detection
Jul 31, 2025



Several anomaly detection and classification methods rely on large amounts of non-anomalous or "normal" samples under the assump- tion that anomalous data is typically harder to acquire. This hypothesis becomes questionable in Few-Shot settings, where as little as one anno- tated sample can make a significant difference. In this paper, we tackle the question of utilizing anomalous samples in training a model for bi- nary anomaly classification. We propose a methodology that incorporates anomalous samples in a multi-score anomaly detection score leveraging recent Zero-Shot and memory-based techniques. We compare the utility of anomalous samples to that of regular samples and study the benefits and limitations of each. In addition, we propose an augmentation-based validation technique to optimize the aggregation of the different anomaly scores and demonstrate its effectiveness on popular industrial anomaly detection datasets.
Object-Centric Cropping for Visual Few-Shot Classification
Jul 31, 2025In the domain of Few-Shot Image Classification, operating with as little as one example per class, the presence of image ambiguities stemming from multiple objects or complex backgrounds can significantly deteriorate performance. Our research demonstrates that incorporating additional information about the local positioning of an object within its image markedly enhances classification across established benchmarks. More importantly, we show that a significant fraction of the improvement can be achieved through the use of the Segment Anything Model, requiring only a pixel of the object of interest to be pointed out, or by employing fully unsupervised foreground object extraction methods.
Active Few-Shot Classification: a New Paradigm for Data-Scarce Learning Settings
Sep 23, 2022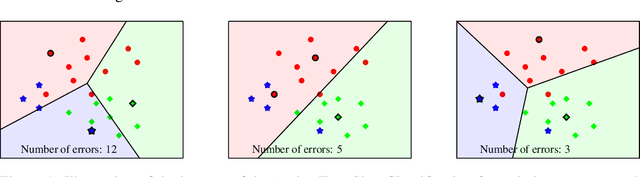
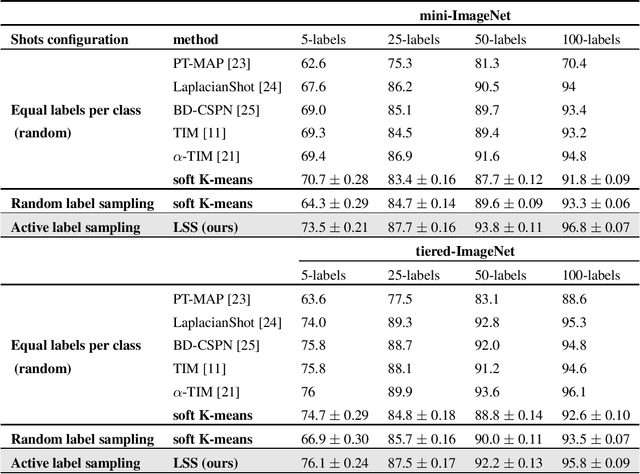

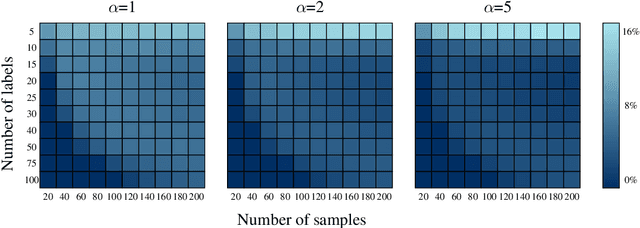
We consider a novel formulation of the problem of Active Few-Shot Classification (AFSC) where the objective is to classify a small, initially unlabeled, dataset given a very restrained labeling budget. This problem can be seen as a rival paradigm to classical Transductive Few-Shot Classification (TFSC), as both these approaches are applicable in similar conditions. We first propose a methodology that combines statistical inference, and an original two-tier active learning strategy that fits well into this framework. We then adapt several standard vision benchmarks from the field of TFSC. Our experiments show the potential benefits of AFSC can be substantial, with gains in average weighted accuracy of up to 10% compared to state-of-the-art TFSC methods for the same labeling budget. We believe this new paradigm could lead to new developments and standards in data-scarce learning settings.
Storing non-uniformly distributed messages in networks of neural cliques
Jul 24, 2013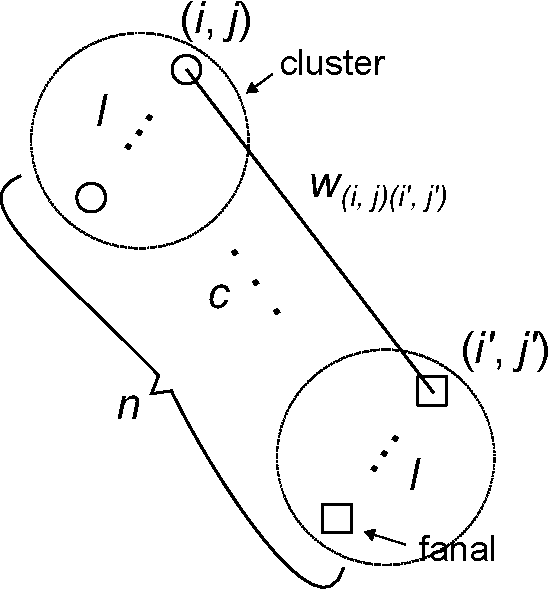
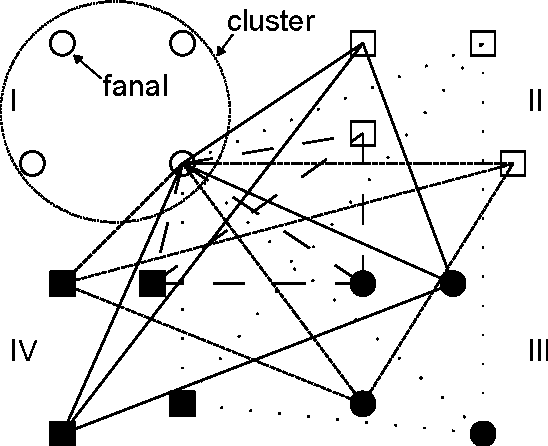
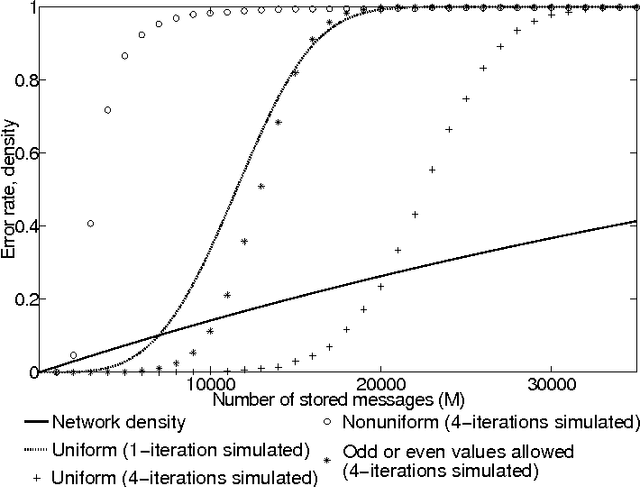
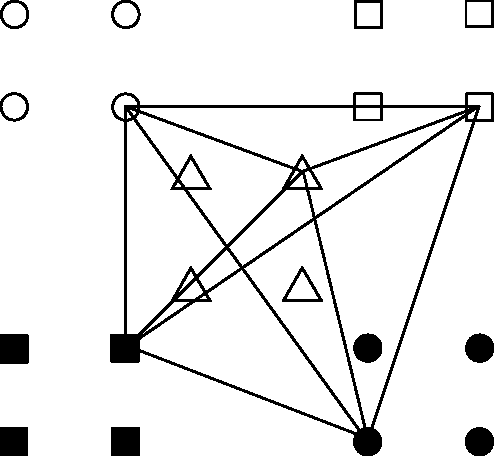
Associative memories are data structures that allow retrieval of stored messages from part of their content. They thus behave similarly to human brain that is capable for instance of retrieving the end of a song given its beginning. Among different families of associative memories, sparse ones are known to provide the best efficiency (ratio of the number of bits stored to that of bits used). Nevertheless, it is well known that non-uniformity of the stored messages can lead to dramatic decrease in performance. We introduce several strategies to allow efficient storage of non-uniform messages in recently introduced sparse associative memories. We analyse and discuss the methods introduced. We also present a practical application example.