 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayer Modeling using Behavioral Signals in Competitive Online Games
Nov 29, 2021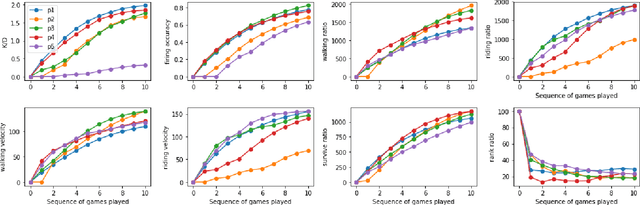
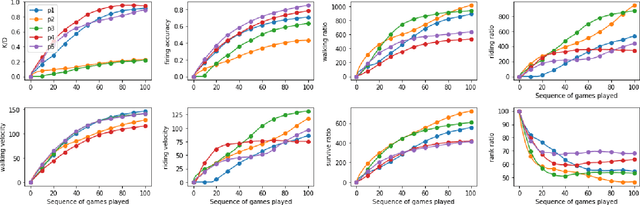

Competitive online games use rating systems to match players with similar skills to ensure a satisfying experience for players. In this paper, we focus on the importance of addressing different aspects of playing behavior when modeling players for creating match-ups. To this end, we engineer several behavioral features from a dataset of over 75,000 battle royale matches and create player models based on the retrieved features. We then use the created models to predict ranks for different groups of players in the data. The predicted ranks are compared to those of three popular rating systems. Our results show the superiority of simple behavioral models over mainstream rating systems. Some behavioral features provided accurate predictions for all groups of players while others proved useful for certain groups of players. The results of this study highlight the necessity of considering different aspects of the player's behavior such as goals, strategy, and expertise when making assignments.
How does the User's Knowledge of the Recommender Influence their Behavior?
Sep 02, 2021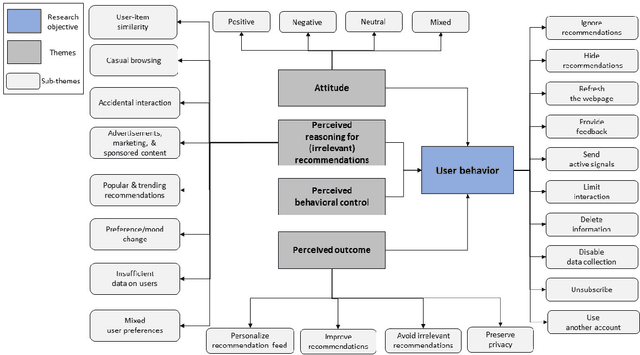
Recommender systems have become a ubiquitous part of modern web applications. They help users discover new and relevant items. Today's users, through years of interaction with these systems have developed an inherent understanding of how recommender systems function, what their objectives are, and how the user might manipulate them. We describe this understanding as the Theory of the Recommender. In this study, we conducted semi-structured interviews with forty recommender system users to empirically explore the relevant factors influencing user behavior. Our findings, based on a rigorous thematic analysis of the collected data, suggest that users possess an intuitive and sophisticated understanding of the recommender system's behavior. We also found that users, based upon their understanding, attitude, and intentions change their interactions to evoke desired recommender behavior. Finally, we discuss the potential implications of such user behavior on recommendation performance.
Unbiased Cascade Bandits: Mitigating Exposure Bias in Online Learning to Rank Recommendation
Aug 07, 2021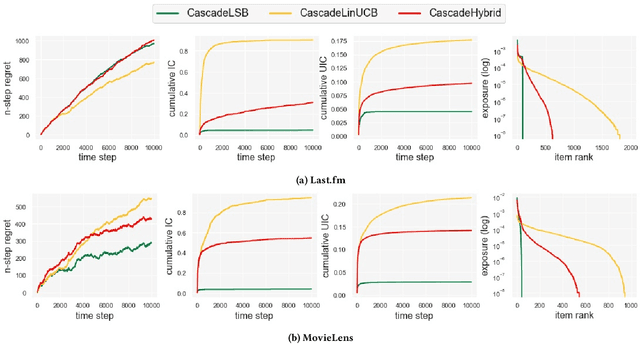
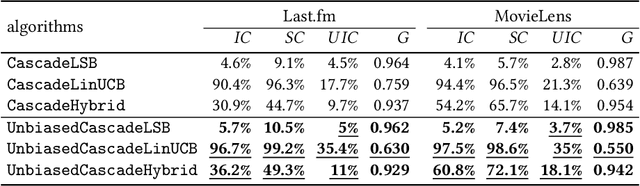
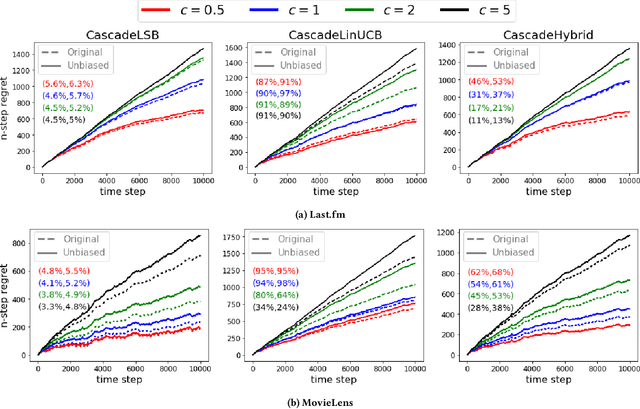
Exposure bias is a well-known issue in recommender systems where items and suppliers are not equally represented in the recommendation results. This is especially problematic when bias is amplified over time as a few popular items are repeatedly over-represented in recommendation lists. This phenomenon can be viewed as a recommendation feedback loop: the system repeatedly recommends certain items at different time points and interactions of users with those items will amplify bias towards those items over time. This issue has been extensively studied in the literature on model-based or neighborhood-based recommendation algorithms, but less work has been done on online recommendation models such as those based on multi-armed Bandit algorithms. In this paper, we study exposure bias in a class of well-known bandit algorithms known as Linear Cascade Bandits. We analyze these algorithms on their ability to handle exposure bias and provide a fair representation for items and suppliers in the recommendation results. Our analysis reveals that these algorithms fail to treat items and suppliers fairly and do not sufficiently explore the item space for each user. To mitigate this bias, we propose a discounting factor and incorporate it into these algorithms that controls the exposure of items at each time step. To show the effectiveness of the proposed discounting factor on mitigating exposure bias, we perform experiments on two datasets using three cascading bandit algorithms and our experimental results show that the proposed method improves the exposure fairness for items and suppliers.
A Graph-based Approach for Mitigating Multi-sided Exposure Bias in Recommender Systems
Jul 07, 2021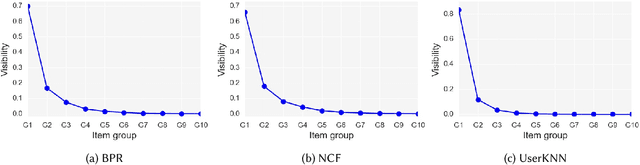
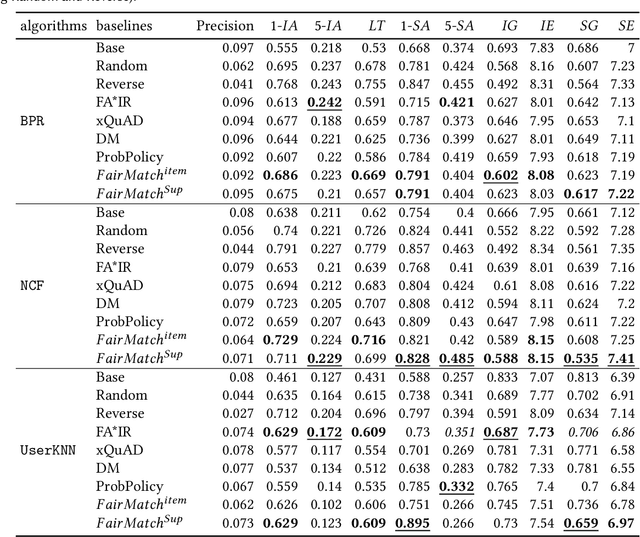
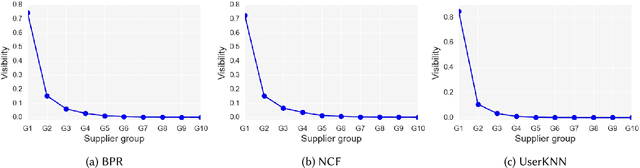
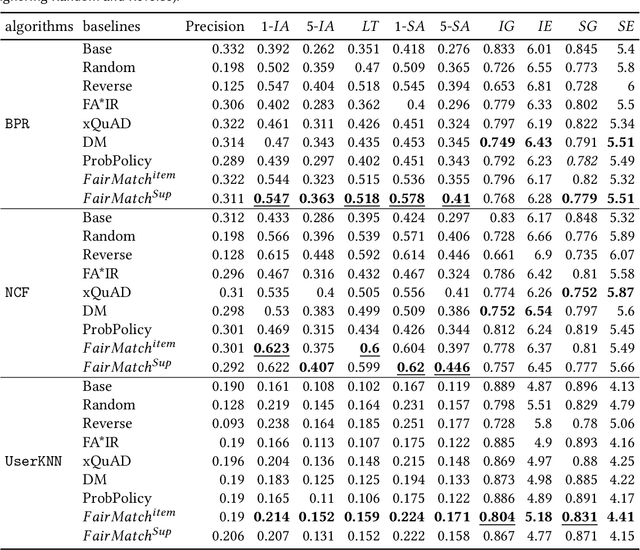
Fairness is a critical system-level objective in recommender systems that has been the subject of extensive recent research. A specific form of fairness is supplier exposure fairness where the objective is to ensure equitable coverage of items across all suppliers in recommendations provided to users. This is especially important in multistakeholder recommendation scenarios where it may be important to optimize utilities not just for the end-user, but also for other stakeholders such as item sellers or producers who desire a fair representation of their items. This type of supplier fairness is sometimes accomplished by attempting to increasing aggregate diversity in order to mitigate popularity bias and to improve the coverage of long-tail items in recommendations. In this paper, we introduce FairMatch, a general graph-based algorithm that works as a post processing approach after recommendation generation to improve exposure fairness for items and suppliers. The algorithm iteratively adds high quality items that have low visibility or items from suppliers with low exposure to the users' final recommendation lists. A comprehensive set of experiments on two datasets and comparison with state-of-the-art baselines show that FairMatch, while significantly improves exposure fairness and aggregate diversity, maintains an acceptable level of relevance of the recommendations.
Evaluating Team Skill Aggregation in Online Competitive Games
Jun 21, 2021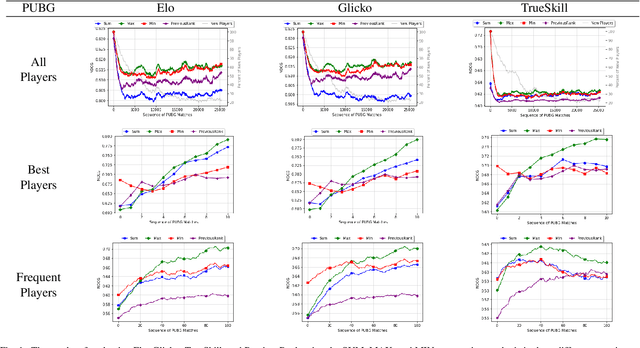
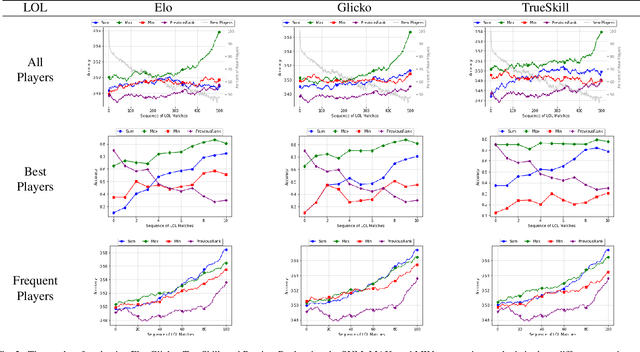
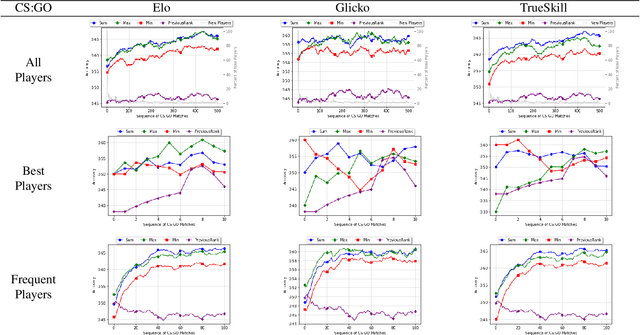
One of the main goals of online competitive games is increasing player engagement by ensuring fair matches. These games use rating systems for creating balanced match-ups. Rating systems leverage statistical estimation to rate players' skills and use skill ratings to predict rank before matching players. Skill ratings of individual players can be aggregated to compute the skill level of a team. While research often aims to improve the accuracy of skill estimation and fairness of match-ups, less attention has been given to how the skill level of a team is calculated from the skill level of its members. In this paper, we propose two new aggregation methods and compare them with a standard approach extensively used in the research literature. We present an exhaustive analysis of the impact of these methods on the predictive performance of rating systems. We perform our experiments using three popular rating systems, Elo, Glicko, and TrueSkill, on three real-world datasets including over 100,000 battle royale and head-to-head matches. Our evaluations show the superiority of the MAX method over the other two methods in the majority of the tested cases, implying that the overall performance of a team is best determined by the performance of its most skilled member. The results of this study highlight the necessity of devising more elaborated methods for calculating a team's performance -- methods covering different aspects of players' behavior such as skills, strategy, or goals.
The Evaluation of Rating Systems in Team-based Battle Royale Games
May 28, 2021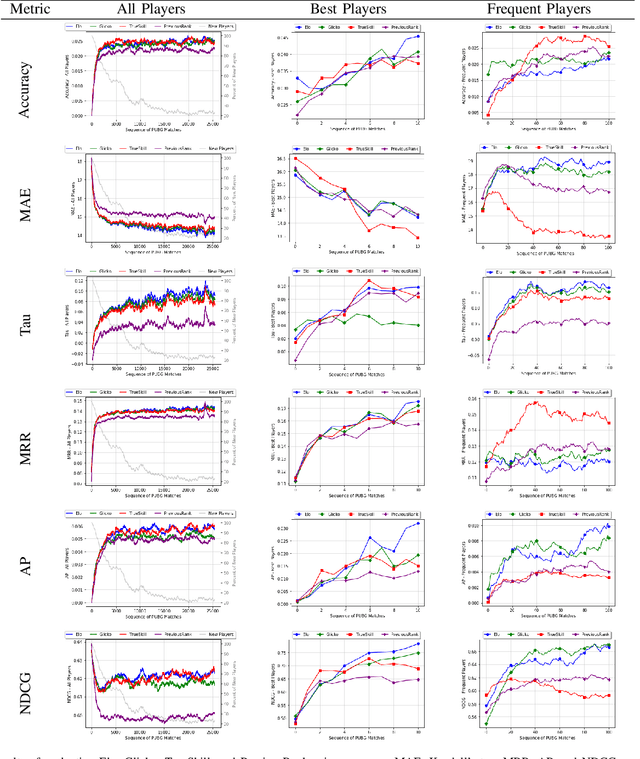
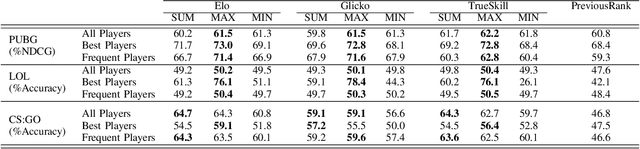
Online competitive games have become a mainstream entertainment platform. To create a fair and exciting experience, these games use rating systems to match players with similar skills. While there has been an increasing amount of research on improving the performance of these systems, less attention has been paid to how their performance is evaluated. In this paper, we explore the utility of several metrics for evaluating three popular rating systems on a real-world dataset of over 25,000 team battle royale matches. Our results suggest considerable differences in their evaluation patterns. Some metrics were highly impacted by the inclusion of new players. Many could not capture the real differences between certain groups of players. Among all metrics studied, normalized discounted cumulative gain (NDCG) demonstrated more reliable performance and more flexibility. It alleviated most of the challenges faced by the other metrics while adding the freedom to adjust the focus of the evaluations on different groups of players.
Toward the Next Generation of News Recommender Systems
Mar 11, 2021
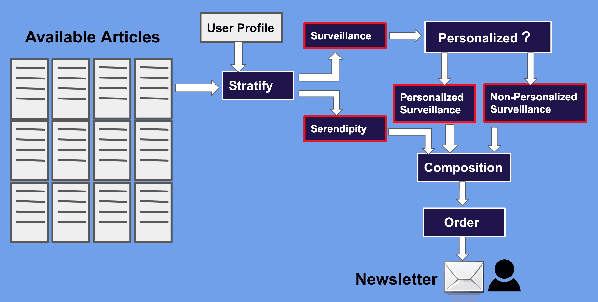
This paper proposes a vision and research agenda for the next generation of news recommender systems (RS), called the table d'hote approach. A table d'hote (translates as host's table) meal is a sequence of courses that create a balanced and enjoyable dining experience for a guest. Likewise, we believe news RS should strive to create a similar experience for the users by satisfying the news-diet needs of a user. While extant news RS considers criteria such as diversity and serendipity, and RS bundles have been studied for other contexts such as tourism, table d'hote goes further by ensuring the recommended articles satisfy a diverse set of user needs in the right proportions and in a specific order. In table d'hote, available articles need to be stratified based on the different ways that news can create value for the reader, building from theories and empirical research in journalism and user engagement. Using theories and empirical research from communication on the uses and gratifications (U&G) consumers derive from media, we define two main strata in a table d'hote news RS, each with its own substrata: 1) surveillance, which consists of information the user needs to know, and 2) serendipity, which are the articles offering unexpected surprises. The diversity of the articles according to the defined strata and the order of the articles within the list of recommendations are also two important aspects of the table d'hote in order to give the users the most effective reading experience. We propose our vision, link it to the existing concepts in the RS literature, and identify challenges for future research.
User-centered Evaluation of Popularity Bias in Recommender Systems
Mar 10, 2021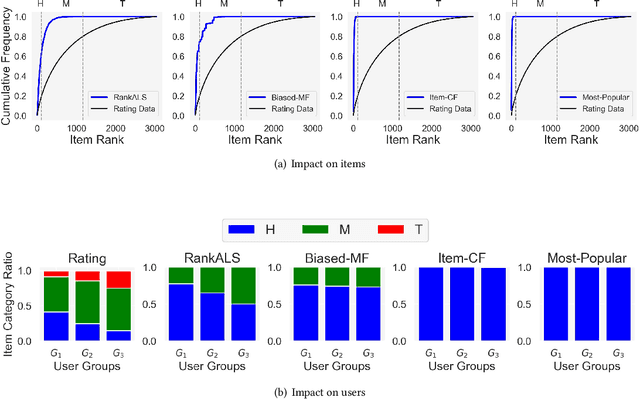
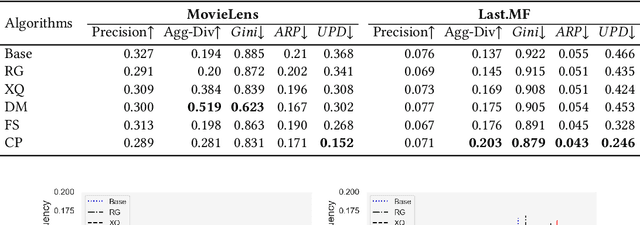
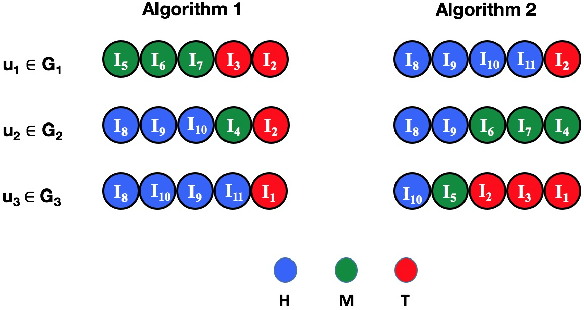
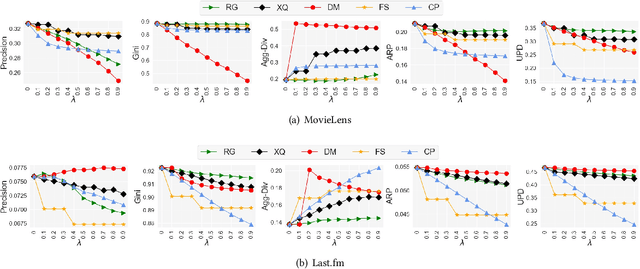
Recommendation and ranking systems are known to suffer from popularity bias; the tendency of the algorithm to favor a few popular items while under-representing the majority of other items. Prior research has examined various approaches for mitigating popularity bias and enhancing the recommendation of long-tail, less popular, items. The effectiveness of these approaches is often assessed using different metrics to evaluate the extent to which over-concentration on popular items is reduced. However, not much attention has been given to the user-centered evaluation of this bias; how different users with different levels of interest towards popular items are affected by such algorithms. In this paper, we show the limitations of the existing metrics to evaluate popularity bias mitigation when we want to assess these algorithms from the users' perspective and we propose a new metric that can address these limitations. In addition, we present an effective approach that mitigates popularity bias from the user-centered point of view. Finally, we investigate several state-of-the-art approaches proposed in recent years to mitigate popularity bias and evaluate their performances using the existing metrics and also from the users' perspective. Our experimental results using two publicly-available datasets show that existing popularity bias mitigation techniques ignore the users' tolerance towards popular items. Our proposed user-centered method can tackle popularity bias effectively for different users while also improving the existing metrics.
Using Stable Matching to Optimize the Balance between Accuracy and Diversity in Recommendation
Jun 05, 2020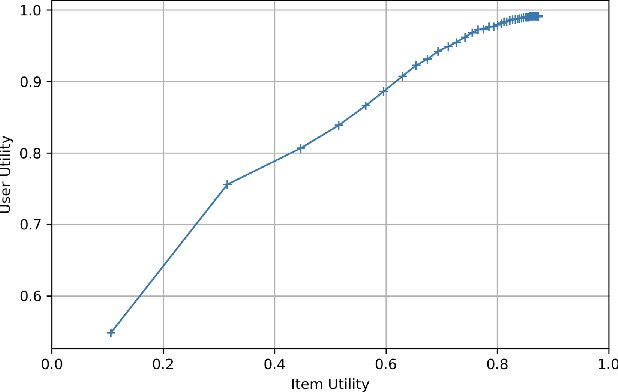
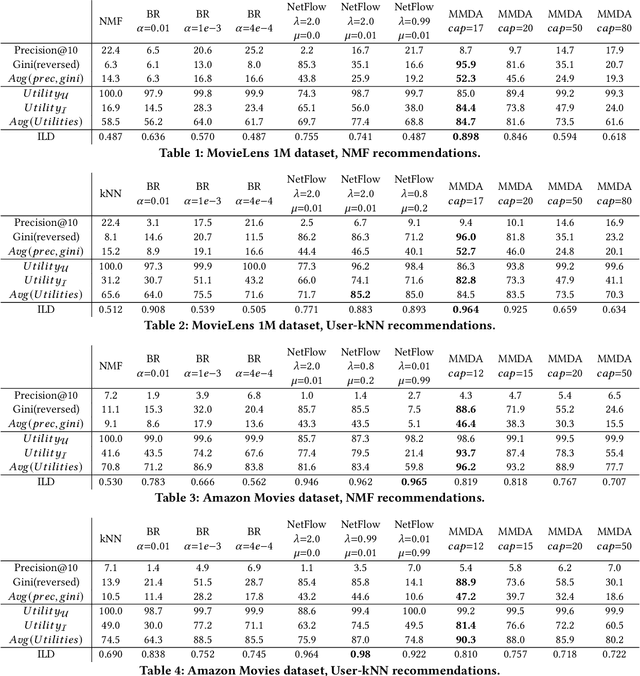
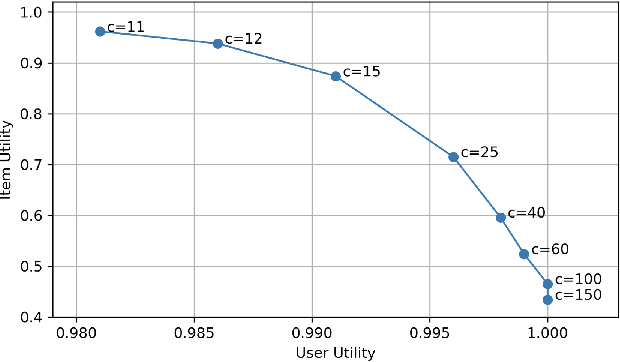
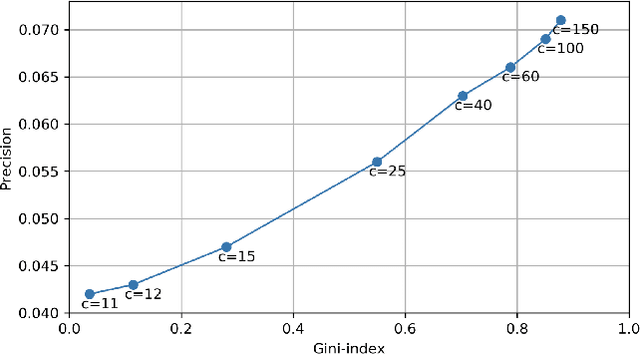
Increasing aggregate diversity (or catalog coverage) is an important system-level objective in many recommendation domains where it may be desirable to mitigate the popularity bias and to improve the coverage of long-tail items in recommendations given to users. This is especially important in multistakeholder recommendation scenarios where it may be important to optimize utilities not just for the end user, but also for other stakeholders such as item sellers or producers who desire a fair representation of their items across recommendation lists produced by the system. Unfortunately, attempts to increase aggregate diversity often result in lower recommendation accuracy for end users. Thus, addressing this problem requires an approach that can effectively manage the trade-offs between accuracy and aggregate diversity. In this work, we propose a two-sided post-processing approach in which both user and item utilities are considered. Our goal is to maximize aggregate diversity while minimizing loss in recommendation accuracy. Our solution is a generalization of the Deferred Acceptance algorithm which was proposed as an efficient algorithm to solve the well-known stable matching problem. We prove that our algorithm results in a unique user-optimal stable match between items and users. Using three recommendation datasets, we empirically demonstrate the effectiveness of our approach in comparison to several baselines. In particular, our results show that the proposed solution is quite effective in increasing aggregate diversity and item-side utility while optimizing recommendation accuracy for end users.
Opportunistic Multi-aspect Fairness through Personalized Re-ranking
May 21, 2020
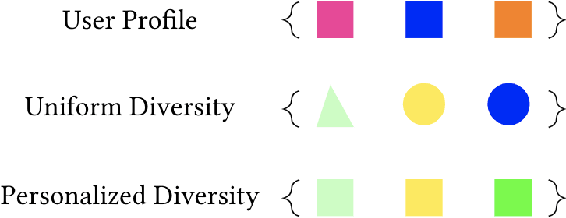
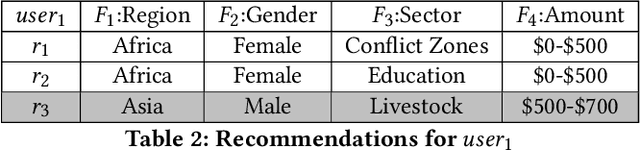
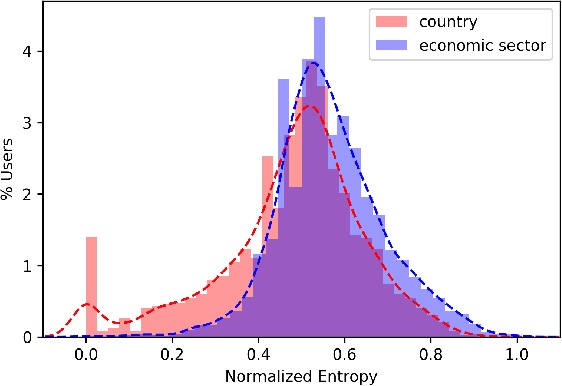
As recommender systems have become more widespread and moved into areas with greater social impact, such as employment and housing, researchers have begun to seek ways to ensure fairness in the results that such systems produce. This work has primarily focused on developing recommendation approaches in which fairness metrics are jointly optimized along with recommendation accuracy. However, the previous work had largely ignored how individual preferences may limit the ability of an algorithm to produce fair recommendations. Furthermore, with few exceptions, researchers have only considered scenarios in which fairness is measured relative to a single sensitive feature or attribute (such as race or gender). In this paper, we present a re-ranking approach to fairness-aware recommendation that learns individual preferences across multiple fairness dimensions and uses them to enhance provider fairness in recommendation results. Specifically, we show that our opportunistic and metric-agnostic approach achieves a better trade-off between accuracy and fairness than prior re-ranking approaches and does so across multiple fairness dimensions.