 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Data Embeddings effective in time series forecasting?
May 27, 2025



Time series forecasting plays a crucial role in many real-world applications, and numerous complex forecasting models have been proposed in recent years. Despite their architectural innovations, most state-of-the-art models report only marginal improvements -- typically just a few thousandths in standard error metrics. These models often incorporate complex data embedding layers to transform raw inputs into higher-dimensional representations to enhance accuracy. But are data embedding techniques actually effective in time series forecasting? Through extensive ablation studies across fifteen state-of-the-art models and four benchmark datasets, we find that removing data embedding layers from many state-of-the-art models does not degrade forecasting performance. In many cases, it improves both accuracy and computational efficiency. The gains from removing embedding layers often exceed the performance differences typically reported between competing models. Code available at: https://github.com/neuripsdataembedidng/DataEmbedding
Times2D: Multi-Period Decomposition and Derivative Mapping for General Time Series Forecasting
Mar 31, 2025



Time series forecasting is an important application in various domains such as energy management, traffic planning, financial markets, meteorology, and medicine. However, real-time series data often present intricate temporal variability and sharp fluctuations, which pose significant challenges for time series forecasting. Previous models that rely on 1D time series representations usually struggle with complex temporal variations. To address the limitations of 1D time series, this study introduces the Times2D method that transforms the 1D time series into 2D space. Times2D consists of three main parts: first, a Periodic Decomposition Block (PDB) that captures temporal variations within a period and between the same periods by converting the time series into a 2D tensor in the frequency domain. Second, the First and Second Derivative Heatmaps (FSDH) capture sharp changes and turning points, respectively. Finally, an Aggregation Forecasting Block (AFB) integrates the output tensors from PDB and FSDH for accurate forecasting. This 2D transformation enables the utilization of 2D convolutional operations to effectively capture long and short characteristics of the time series. Comprehensive experimental results across large-scale data in the literature demonstrate that the proposed Times2D model achieves state-of-the-art performance in both short-term and long-term forecasting. The code is available in this repository: https://github.com/Tims2D/Times2D.
GNN-Based Candidate Node Predictor for Influence Maximization in Temporal Graphs
Mar 31, 2025



In an age where information spreads rapidly across social media, effectively identifying influential nodes in dynamic networks is critical. Traditional influence maximization strategies often fail to keep up with rapidly evolving relationships and structures, leading to missed opportunities and inefficiencies. To address this, we propose a novel learning-based approach integrating Graph Neural Networks (GNNs) with Bidirectional Long Short-Term Memory (BiLSTM) models. This hybrid framework captures both structural and temporal dynamics, enabling accurate prediction of candidate nodes for seed set selection. The bidirectional nature of BiLSTM allows our model to analyze patterns from both past and future network states, ensuring adaptability to changes over time. By dynamically adapting to graph evolution at each time snapshot, our approach improves seed set calculation efficiency, achieving an average of 90% accuracy in predicting potential seed nodes across diverse networks. This significantly reduces computational overhead by optimizing the number of nodes evaluated for seed selection. Our method is particularly effective in fields like viral marketing and social network analysis, where understanding temporal dynamics is crucial.
SPDNet: Seasonal-Periodic Decomposition Network for Advanced Residential Demand Forecasting
Mar 28, 2025



Residential electricity demand forecasting is critical for efficient energy management and grid stability. Accurate predictions enable utility companies to optimize planning and operations. However, real-world residential electricity demand data often exhibit intricate temporal variability, including multiple seasonalities, periodicities, and abrupt fluctuations, which pose significant challenges for forecasting models. Previous models that rely on statistical methods, recurrent, convolutional neural networks, and transformers often struggle to capture these intricate temporal dynamics. To address these challenges, we propose the Seasonal-Periodic Decomposition Network (SPDNet), a novel deep learning framework consisting of two main modules. The first is the Seasonal-Trend Decomposition Module (STDM), which decomposes the input data into trend, seasonal, and residual components. The second is the Periodical Decomposition Module (PDM), which employs the Fast Fourier Transform to identify the dominant periods. For each dominant period, 1D input data is reshaped into a 2D tensor, where rows represent periods and columns correspond to frequencies. The 2D representations are then processed through three submodules: a 1D convolution to capture sharp fluctuations, a transformer-based encoder to model global patterns, and a 2D convolution to capture interactions between periods. Extensive experiments conducted on real-world residential electricity load data demonstrate that SPDNet outperforms traditional and advanced models in both forecasting accuracy and computational efficiency. The code is available in this repository: https://github.com/Tims2D/SPDNet.
Autoencoder-Based Domain Learning for Semantic Communication with Conceptual Spaces
Jan 29, 2024



Communication with the goal of accurately conveying meaning, rather than accurately transmitting symbols, has become an area of growing interest. This paradigm, termed semantic communication, typically leverages modern developments in artificial intelligence and machine learning to improve the efficiency and robustness of communication systems. However, a standard model for capturing and quantifying the details of "meaning" is lacking, with many leading approaches to semantic communication adopting a black-box framework with little understanding of what exactly the model is learning. One solution is to utilize the conceptual spaces framework, which models meaning explicitly in a geometric manner. Though prior work studying semantic communication with conceptual spaces has shown promising results, these previous attempts involve hand-crafting a conceptual space model, severely limiting the scalability and practicality of the approach. In this work, we develop a framework for learning a domain of a conceptual space model using only the raw data with high-level property labels. In experiments using the MNIST and CelebA datasets, we show that the domains learned using the framework maintain semantic similarity relations and possess interpretable dimensions.
Active Foundational Models for Fault Diagnosis of Electrical Motors
Nov 27, 2023



Fault detection and diagnosis of electrical motors are of utmost importance in ensuring the safe and reliable operation of several industrial systems. Detection and diagnosis of faults at the incipient stage allows corrective actions to be taken in order to reduce the severity of faults. The existing data-driven deep learning approaches for machine fault diagnosis rely extensively on huge amounts of labeled samples, where annotations are expensive and time-consuming. However, a major portion of unlabeled condition monitoring data is not exploited in the training process. To overcome this limitation, we propose a foundational model-based Active Learning framework that utilizes less amount of labeled samples, which are most informative and harnesses a large amount of available unlabeled data by effectively combining Active Learning and Contrastive Self-Supervised Learning techniques. It consists of a transformer network-based backbone model trained using an advanced nearest-neighbor contrastive self-supervised learning method. This approach empowers the backbone to learn improved representations of samples derived from raw, unlabeled vibration data. Subsequently, the backbone can undergo fine-tuning to address a range of downstream tasks, both within the same machines and across different machines. The effectiveness of the proposed methodology has been assessed through the fine-tuning of the backbone for multiple target tasks using three distinct machine-bearing fault datasets. The experimental evaluation demonstrates a superior performance as compared to existing state-of-the-art fault diagnosis methods with less amount of labeled data.
Foundational Models for Fault Diagnosis of Electrical Motors
Jul 31, 2023



A majority of recent advancements related to the fault diagnosis of electrical motors are based on the assumption that training and testing data are drawn from the same distribution. However, the data distribution can vary across different operating conditions during real-world operating scenarios of electrical motors. Consequently, this assumption limits the practical implementation of existing studies for fault diagnosis, as they rely on fully labelled training data spanning all operating conditions and assume a consistent distribution. This is because obtaining a large number of labelled samples for several machines across different fault cases and operating scenarios may be unfeasible. In order to overcome the aforementioned limitations, this work proposes a framework to develop a foundational model for fault diagnosis of electrical motors. It involves building a neural network-based backbone to learn high-level features using self-supervised learning, and then fine-tuning the backbone to achieve specific objectives. The primary advantage of such an approach is that the backbone can be fine-tuned to achieve a wide variety of target tasks using very less amount of training data as compared to traditional supervised learning methodologies. The empirical evaluation demonstrates the effectiveness of the proposed approach by obtaining more than 90\% classification accuracy by fine-tuning the backbone not only across different types of fault scenarios or operating conditions, but also across different machines. This illustrates the promising potential of the proposed approach for cross-machine fault diagnosis tasks in real-world applications.
Knowledge-Driven Semantic Communication Enabled by the Geometry of Meaning
Jun 05, 2023



As our world grows increasingly connected and new technologies arise, global demands for data traffic continue to rise exponentially. Limited by the fundamental results of information theory, to meet these demands we are forced to either increase power or bandwidth usage. But what if there was a way to use these resources more efficiently? This question is the main driver behind the recent surge of interest in semantic communication, which seeks to leverage increased intelligence to move beyond the Shannon limit of technical communication. In this paper we expound a method of achieving semantic communication which utilizes the conceptual space model of knowledge representation. In contrast to other popular methods of semantic communication, our approach is intuitive, interpretable and efficient. We derive some preliminary results bounding the probability of semantic error under our framework, and show how our approach can serve as the underlying knowledge-driven foundation to higher-level intelligent systems. Taking inspiration from a metaverse application, we perform simulations to draw important insights about the proposed method and demonstrate how it can be used to achieve semantic communication with a 99.9% reduction in rate as compared to a more traditional setup.
A General Framework for Uncertainty Quantification via Neural SDE-RNN
Jun 01, 2023



Uncertainty quantification is a critical yet unsolved challenge for deep learning, especially for the time series imputation with irregularly sampled measurements. To tackle this problem, we propose a novel framework based on the principles of recurrent neural networks and neural stochastic differential equations for reconciling irregularly sampled measurements. We impute measurements at any arbitrary timescale and quantify the uncertainty in the imputations in a principled manner. Specifically, we derive analytical expressions for quantifying and propagating the epistemic and aleatoric uncertainty across time instants. Our experiments on the IEEE 37 bus test distribution system reveal that our framework can outperform state-of-the-art uncertainty quantification approaches for time-series data imputations.
Semantic Communication with Conceptual Spaces
Oct 04, 2022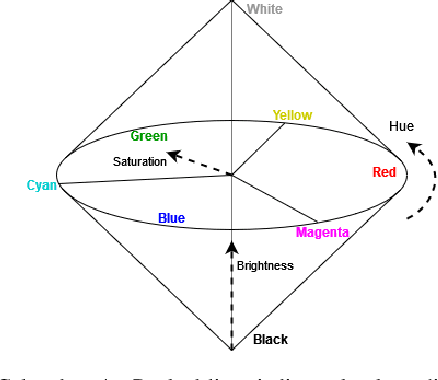
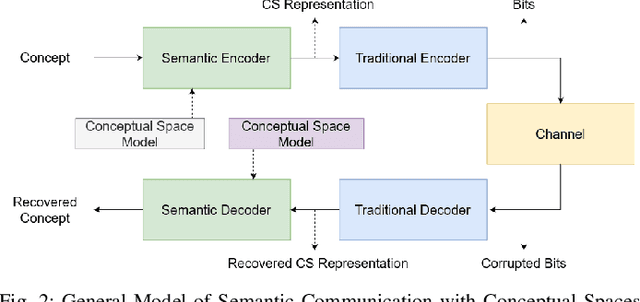
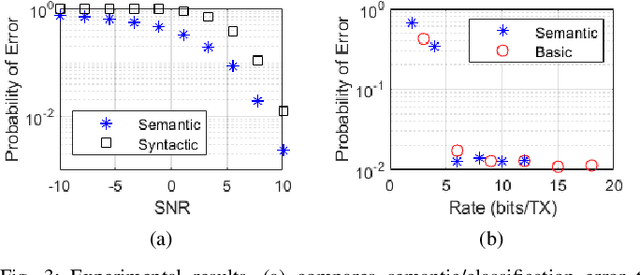
Despite the fact that Shannon and Weaver's Mathematical Theory of Communication was published over 70 years ago, all communication systems continue to operate at the first of three levels defined in this theory: the technical level. In this letter, we argue that a transition to the semantic level embodies a natural, important step in the evolution of communication technologies. Furthermore, we propose a novel approach to engineering semantic communication using conceptual spaces and functional compression. We introduce a model of semantic communication utilizing this approach, and present quantitative simulation results demonstrating performance gains on the order of 3dB.