 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Knowledge with Ensemble Learning for Online Distillation
Dec 18, 2023Offline distillation is a two-stage pipeline that requires expensive resources to train a teacher network and then distill the knowledge to a student for deployment. Online knowledge distillation, on the other hand, is a one-stage strategy that alleviates the requirement with mutual learning and collaborative learning. Recent peer collaborative learning (PCL) integrates online ensemble, collaboration of base networks and temporal mean teacher to construct effective knowledge. However, the model collapses occasionally in PCL due to high homogenization between the student and the teacher. In this paper, the cause of the high homogenization is analyzed and the solution is presented. A decoupled knowledge for online knowledge distillation is generated by an independent teacher, separate from the student. Such design can increase the diversity between the networks and reduce the possibility of model collapse. To obtain early decoupled knowledge, an initialization scheme for the teacher is devised, and a 2D geometry-based analysis experiment is conducted under ideal conditions to showcase the effectiveness of this scheme. Moreover, to improve the teacher's supervisory resilience, a decaying ensemble scheme is devised. It assembles the knowledge of the teacher to which a dynamic weight which is large at the start of the training and gradually decreases with the training process is assigned. The assembled knowledge serves as a strong teacher during the early training and the decreased-weight-assembled knowledge can eliminate the distribution deviation under the potentially overfitted teacher's supervision. A Monte Carlo-based simulation is conducted to evaluate the convergence. Extensive experiments on CIFAR-10, CIFAR-100 and TinyImageNet show the superiority of our method. Ablation studies and further analysis demonstrate the effectiveness.
Multi-granularity for knowledge distillation
Aug 15, 2021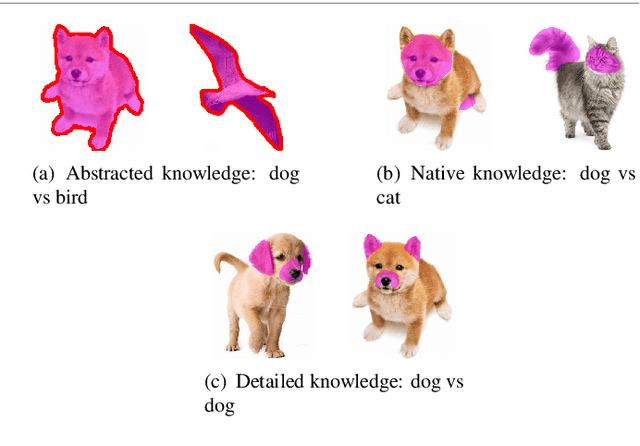
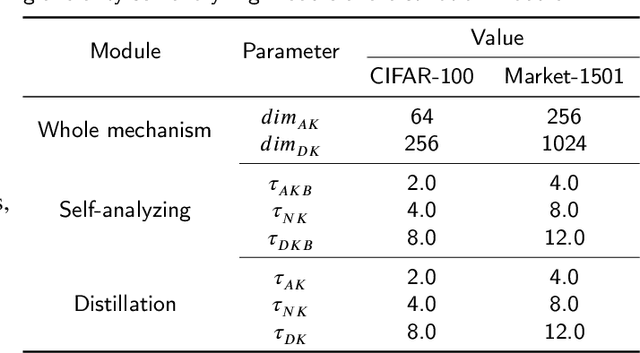
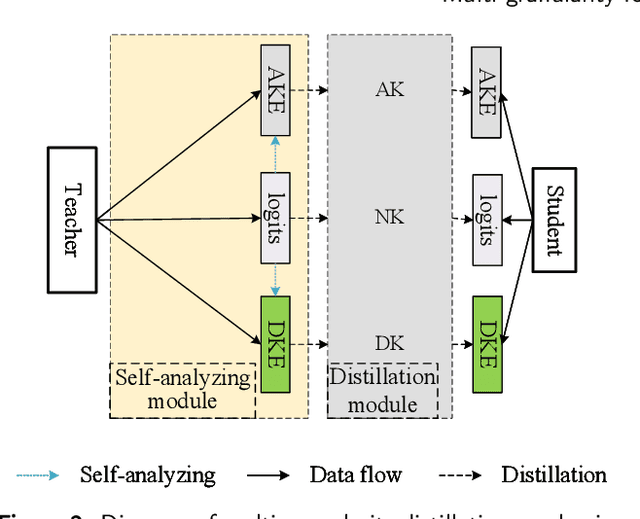
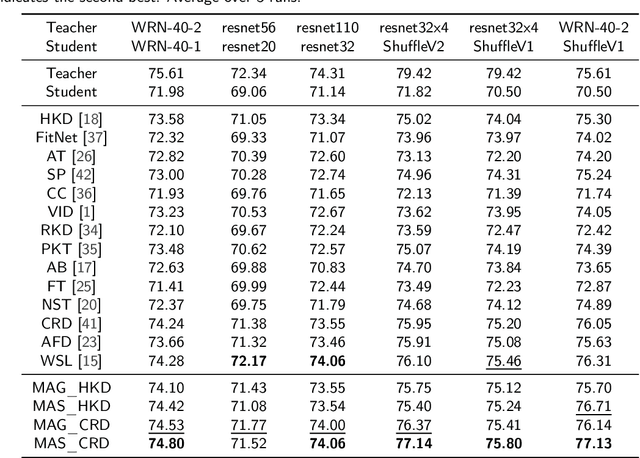
Considering the fact that students have different abilities to understand the knowledge imparted by teachers, a multi-granularity distillation mechanism is proposed for transferring more understandable knowledge for student networks. A multi-granularity self-analyzing module of the teacher network is designed, which enables the student network to learn knowledge from different teaching patterns. Furthermore, a stable excitation scheme is proposed for robust supervision for the student training. The proposed distillation mechanism can be embedded into different distillation frameworks, which are taken as baselines. Experiments show the mechanism improves the accuracy by 0.58% on average and by 1.08% in the best over the baselines, which makes its performance superior to the state-of-the-arts. It is also exploited that the student's ability of fine-tuning and robustness to noisy inputs can be improved via the proposed mechanism. The code is available at https://github.com/shaoeric/multi-granularity-distillation.