 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Enhances LLMs' Stability in Strategic Thinking
Feb 04, 2026Large Language Models (LLMs) often exhibit pronounced context-dependent variability that undermines predictable multi-agent behavior in tasks requiring strategic thinking. Focusing on models that range from 7 to 9 billion parameters in size engaged in a ten-round repeated Prisoner's Dilemma, we evaluate whether short, costless pre-play messages emulating the cheap-talk paradigm affect strategic stability. Our analysis uses simulation-level bootstrap resampling and nonparametric inference to compare cooperation trajectories fitted with LOWESS regression across both the messaging and the no-messaging condition. We demonstrate consistent reductions in trajectory noise across a majority of the model-context pairings being studied. The stabilizing effect persists across multiple prompt variants and decoding regimes, though its magnitude depends on model choice and contextual framing, with models displaying higher baseline volatility gaining the most. While communication rarely produces harmful instability, we document a few context-specific exceptions and identify the limited domains in which communication harms stability. These findings position cheap-talk style communication as a low-cost, practical tool for improving the predictability and reliability of strategic behavior in multi-agent LLM systems.
Resource Governance in Networked Systems via Integrated Variational Autoencoders and Reinforcement Learning
Oct 30, 2024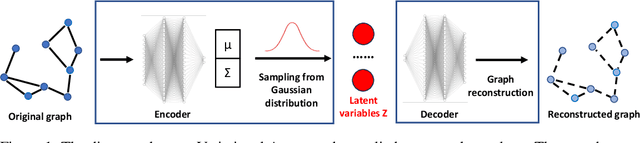
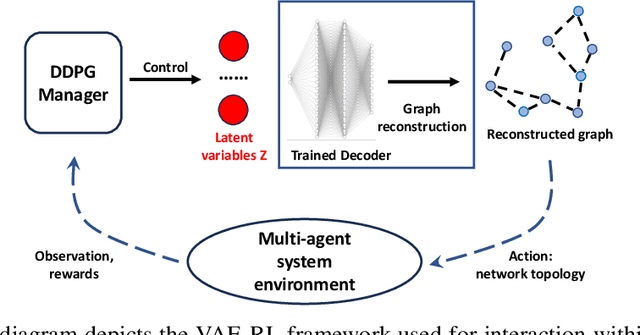
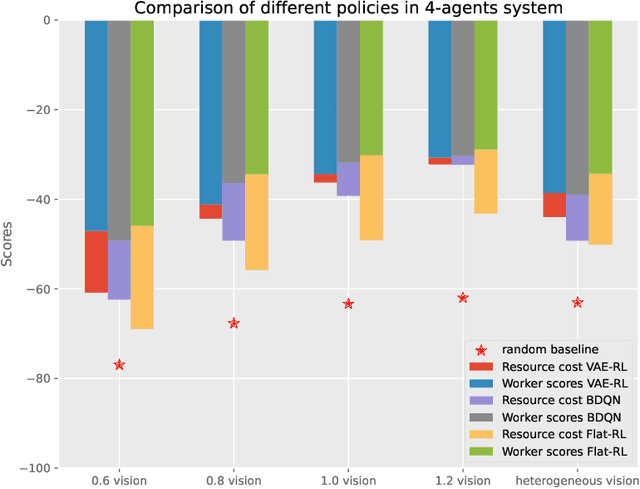
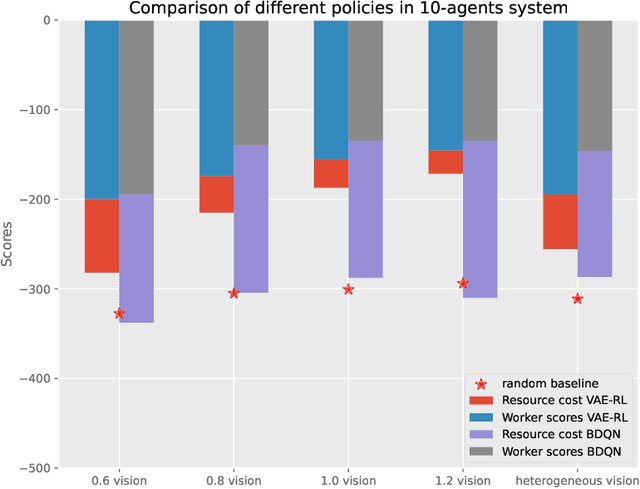
We introduce a framework that integrates variational autoencoders (VAE) with reinforcement learning (RL) to balance system performance and resource usage in multi-agent systems by dynamically adjusting network structures over time. A key innovation of this method is its capability to handle the vast action space of the network structure. This is achieved by combining Variational Auto-Encoder and Deep Reinforcement Learning to control the latent space encoded from the network structures. The proposed method, evaluated on the modified OpenAI particle environment under various scenarios, not only demonstrates superior performance compared to baselines but also reveals interesting strategies and insights through the learned behaviors.
Adaptive Network Intervention for Complex Systems: A Hierarchical Graph Reinforcement Learning Approach
Oct 30, 2024Effective governance and steering of behavior in complex multi-agent systems (MAS) are essential for managing system-wide outcomes, particularly in environments where interactions are structured by dynamic networks. In many applications, the goal is to promote pro-social behavior among agents, where network structure plays a pivotal role in shaping these interactions. This paper introduces a Hierarchical Graph Reinforcement Learning (HGRL) framework that governs such systems through targeted interventions in the network structure. Operating within the constraints of limited managerial authority, the HGRL framework demonstrates superior performance across a range of environmental conditions, outperforming established baseline methods. Our findings highlight the critical influence of agent-to-agent learning (social learning) on system behavior: under low social learning, the HGRL manager preserves cooperation, forming robust core-periphery networks dominated by cooperators. In contrast, high social learning accelerates defection, leading to sparser, chain-like networks. Additionally, the study underscores the importance of the system manager's authority level in preventing system-wide failures, such as agent rebellion or collapse, positioning HGRL as a powerful tool for dynamic network-based governance.
Instigating Cooperation among LLM Agents Using Adaptive Information Modulation
Sep 16, 2024This paper introduces a novel framework combining LLM agents as proxies for human strategic behavior with reinforcement learning (RL) to engage these agents in evolving strategic interactions within team environments. Our approach extends traditional agent-based simulations by using strategic LLM agents (SLA) and introducing dynamic and adaptive governance through a pro-social promoting RL agent (PPA) that modulates information access across agents in a network, optimizing social welfare and promoting pro-social behavior. Through validation in iterative games, including the prisoner dilemma, we demonstrate that SLA agents exhibit nuanced strategic adaptations. The PPA agent effectively learns to adjust information transparency, resulting in enhanced cooperation rates. This framework offers significant insights into AI-mediated social dynamics, contributing to the deployment of AI in real-world team settings.
Large Model Strategic Thinking, Small Model Efficiency: Transferring Theory of Mind in Large Language Models
Aug 13, 2024



As the performance of larger, newer Large Language Models continues to improve for strategic Theory of Mind (ToM) tasks, the demand for these state of the art models increases commensurately. However, their deployment is costly both in terms of processing power and time. In this paper, we investigate the feasibility of creating smaller, simulation-ready agents by way of fine-tuning. To do this, we present a large pre-trained model with 20 unique scenarios that combine a social context with a social dilemma, recording its answers, and using them for Q\&A fine-tuning on a smaller model of the same family. Our focus is on in-context game-theoretic decision-making, the same domain within which human interaction occurs and that requires both a theory of mind (or a semblance thereof) and an understanding of social dynamics. We find that the fine-tuned smaller language model exhibited significant performance closer to that of its larger relative, and that their improvements extended in areas and contexts beyond the ones provided in the training examples. On average for all games, through fine-tuning, the smaller model showed a \%46 improvement in aligning with the behavior of the larger model, with \%100 representing complete alignment. This suggests that our pipeline represents an efficient method to transmit some form of theory of mind to smaller models, creating improved and cheaply deployable algorithms in the process. Despite their simplicity and their associated shortcomings and limitations, our findings represent a stepping stone in the pursuit and training of specialized models for strategic and social decision making.
Strategic Behavior of Large Language Models: Game Structure vs. Contextual Framing
Sep 12, 2023



This paper investigates the strategic decision-making capabilities of three Large Language Models (LLMs): GPT-3.5, GPT-4, and LLaMa-2, within the framework of game theory. Utilizing four canonical two-player games -- Prisoner's Dilemma, Stag Hunt, Snowdrift, and Prisoner's Delight -- we explore how these models navigate social dilemmas, situations where players can either cooperate for a collective benefit or defect for individual gain. Crucially, we extend our analysis to examine the role of contextual framing, such as diplomatic relations or casual friendships, in shaping the models' decisions. Our findings reveal a complex landscape: while GPT-3.5 is highly sensitive to contextual framing, it shows limited ability to engage in abstract strategic reasoning. Both GPT-4 and LLaMa-2 adjust their strategies based on game structure and context, but LLaMa-2 exhibits a more nuanced understanding of the games' underlying mechanics. These results highlight the current limitations and varied proficiencies of LLMs in strategic decision-making, cautioning against their unqualified use in tasks requiring complex strategic reasoning.