 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplacian-Former: Overcoming the Limitations of Vision Transformers in Local Texture Detection
Aug 31, 2023Vision Transformer (ViT) models have demonstrated a breakthrough in a wide range of computer vision tasks. However, compared to the Convolutional Neural Network (CNN) models, it has been observed that the ViT models struggle to capture high-frequency components of images, which can limit their ability to detect local textures and edge information. As abnormalities in human tissue, such as tumors and lesions, may greatly vary in structure, texture, and shape, high-frequency information such as texture is crucial for effective semantic segmentation tasks. To address this limitation in ViT models, we propose a new technique, Laplacian-Former, that enhances the self-attention map by adaptively re-calibrating the frequency information in a Laplacian pyramid. More specifically, our proposed method utilizes a dual attention mechanism via efficient attention and frequency attention while the efficient attention mechanism reduces the complexity of self-attention to linear while producing the same output, selectively intensifying the contribution of shape and texture features. Furthermore, we introduce a novel efficient enhancement multi-scale bridge that effectively transfers spatial information from the encoder to the decoder while preserving the fundamental features. We demonstrate the efficacy of Laplacian-former on multi-organ and skin lesion segmentation tasks with +1.87\% and +0.76\% dice scores compared to SOTA approaches, respectively. Our implementation is publically available at https://github.com/mindflow-institue/Laplacian-Former
Improving FHB Screening in Wheat Breeding Using an Efficient Transformer Model
Aug 07, 2023Fusarium head blight is a devastating disease that causes significant economic losses annually on small grains. Efficiency, accuracy, and timely detection of FHB in the resistance screening are critical for wheat and barley breeding programs. In recent years, various image processing techniques have been developed using supervised machine learning algorithms for the early detection of FHB. The state-of-the-art convolutional neural network-based methods, such as U-Net, employ a series of encoding blocks to create a local representation and a series of decoding blocks to capture the semantic relations. However, these methods are not often capable of long-range modeling dependencies inside the input data, and their ability to model multi-scale objects with significant variations in texture and shape is limited. Vision transformers as alternative architectures with innate global self-attention mechanisms for sequence-to-sequence prediction, due to insufficient low-level details, may also limit localization capabilities. To overcome these limitations, a new Context Bridge is proposed to integrate the local representation capability of the U-Net network in the transformer model. In addition, the standard attention mechanism of the original transformer is replaced with Efficient Self-attention, which is less complicated than other state-of-the-art methods. To train the proposed network, 12,000 wheat images from an FHB-inoculated wheat field at the SDSU research farm in Volga, SD, were captured. In addition to healthy and unhealthy plants, these images encompass various stages of the disease. A team of expert pathologists annotated the images for training and evaluating the developed model. As a result, the effectiveness of the transformer-based method for FHB-disease detection, through extensive experiments across typical tasks for plant image segmentation, is demonstrated.
* 10 pages, 5 figures, 1 table. Presented at the 2023 ASABE Annual International Meeting conference in Omaha, Nebraska. Also available at https://elibrary.asabe.org/abstract.asp?aid=54149
Classifiers fusion method to recognize handwritten persian numerals
Aug 15, 2014
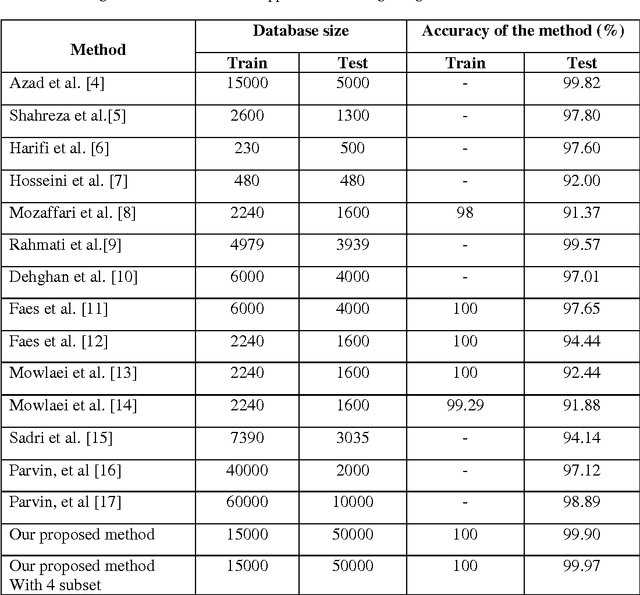
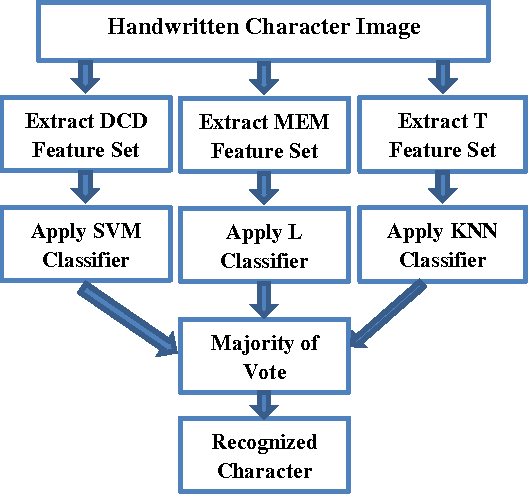
Recognition of Persian handwritten characters has been considered as a significant field of research for the last few years under pattern analysing technique. In this paper, a new approach for robust handwritten Persian numerals recognition using strong feature set and a classifier fusion method is scrutinized to increase the recognition percentage. For implementing the classifier fusion technique, we have considered k nearest neighbour (KNN), linear classifier (LC) and support vector machine (SVM) classifiers. The innovation of this tactic is to attain better precision with few features using classifier fusion method. For evaluation of the proposed method we considered a Persian numerals database with 20,000 handwritten samples. Spending 15,000 samples for training stage, we verified our technique on other 5,000 samples, and the correct recognition ratio achieved approximately 99.90%. Additional, we got 99.97% exactness using four-fold cross validation procedure on 20,000 databases.
* This paper has been withdrawn by the author due to a crucial sign error in equation 5 and 6, and some mistake in Table 1 information. please let me for changing this information and updating this paper
Real-Time and Robust Method for Hand Gesture Recognition System Based on Cross-Correlation Coefficient
Aug 08, 2014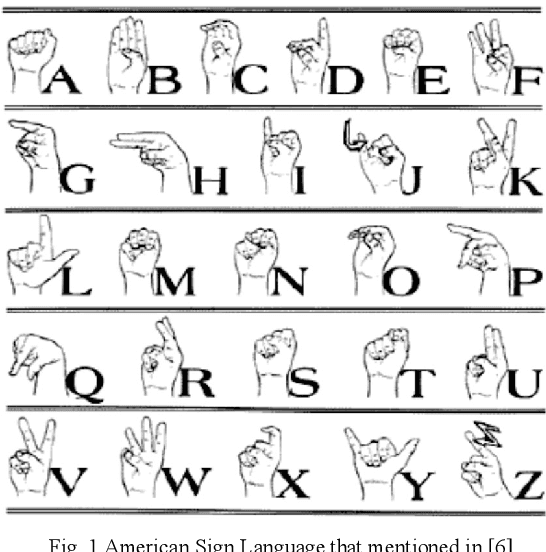
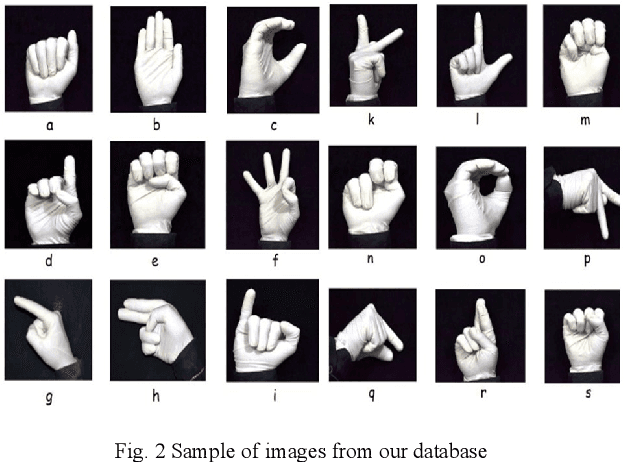
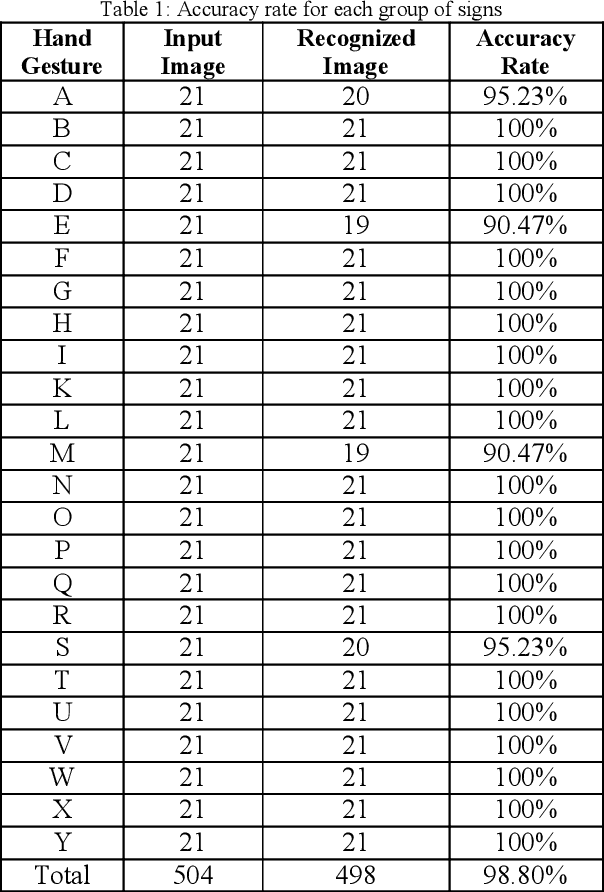

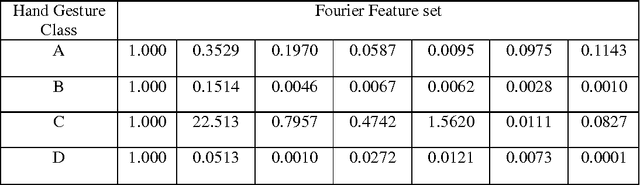
Hand gesture recognition possesses extensive applications in virtual reality, sign language recognition, and computer games. The direct interface of hand gestures provides us a new way for communicating with the virtual environment. In this paper a novel and real-time approach for hand gesture recognition system is presented. In the suggested method, first, the hand gesture is extracted from the main image by the image segmentation and morphological operation and then is sent to feature extraction stage. In feature extraction stage the Cross-correlation coefficient is applied on the gesture to recognize it. In the result part, the proposed approach is applied on American Sign Language (ASL) database and the accuracy rate obtained 98.34%.
* arXiv admin note: substantial text overlap with http://dx.doi.org/10.1109/ICCCA.2012.6179213 by other author
Real-Time Human-Computer Interaction Based on Face and Hand Gesture Recognition
Aug 07, 2014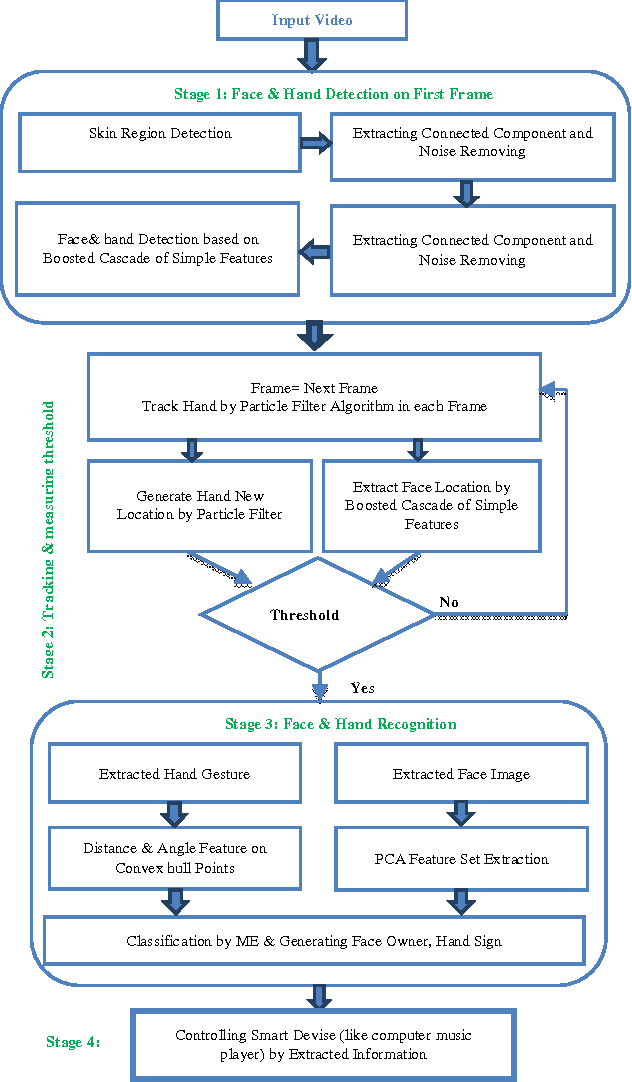

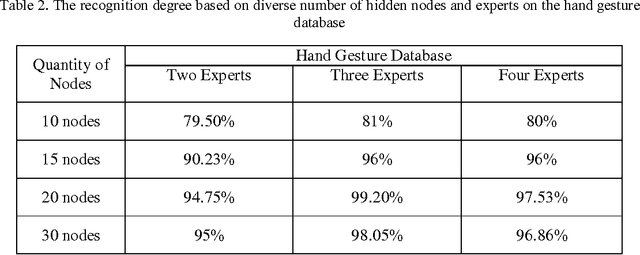
At the present time, hand gestures recognition system could be used as a more expected and useable approach for human computer interaction. Automatic hand gesture recognition system provides us a new tactic for interactive with the virtual environment. In this paper, a face and hand gesture recognition system which is able to control computer media player is offered. Hand gesture and human face are the key element to interact with the smart system. We used the face recognition scheme for viewer verification and the hand gesture recognition in mechanism of computer media player, for instance, volume down/up, next music and etc. In the proposed technique, first, the hand gesture and face location is extracted from the main image by combination of skin and cascade detector and then is sent to recognition stage. In recognition stage, first, the threshold condition is inspected then the extracted face and gesture will be recognized. In the result stage, the proposed technique is applied on the video dataset and the high precision ratio acquired. Additional the recommended hand gesture recognition method is applied on static American Sign Language (ASL) database and the correctness rate achieved nearby 99.40%. also the planned method could be used in gesture based computer games and virtual reality.
Real-Time and Efficient Method for Accuracy Enhancement of Edge Based License Plate Recognition System
Jul 24, 2014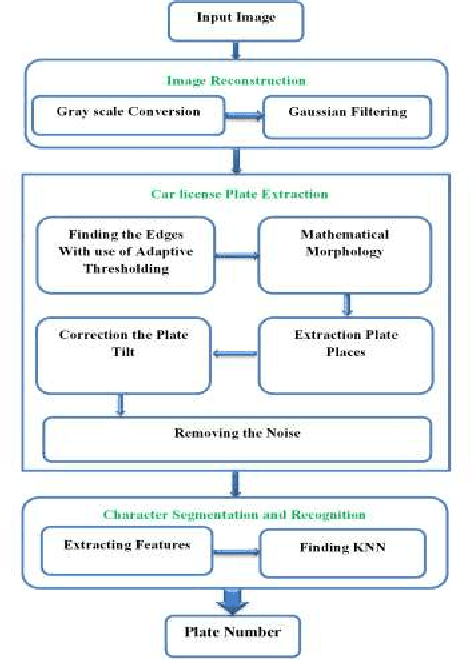

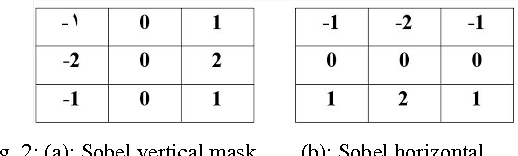

License Plate Recognition plays an important role on the traffic monitoring and parking management. Administration and restriction of those transportation tools for their better service becomes very essential. In this paper, a fast and real time method has an appropriate application to find plates that the plat has tilt and the picture quality is poor. In the proposed method, at the beginning, the image is converted into binary mode with use of adaptive threshold. And with use of edge detection and morphology operation, plate number location has been specified and if the plat has tilt; its tilt is removed away. Then its characters are distinguished using image processing techniques. Finally, K Nearest Neighbour (KNN) classifier was used for character recognition. This method has been tested on available data set that has different images of the background, considering distance, and angel of view so that the correct extraction rate of plate reached at 98% and character recognition rate achieved at 99.12%. Further we tested our character recognition stage on Persian vehicle data set and we achieved 99% correct recognition rate.
Optimized Method for Iranian Road Signs Detection and recognition system
Jul 20, 2014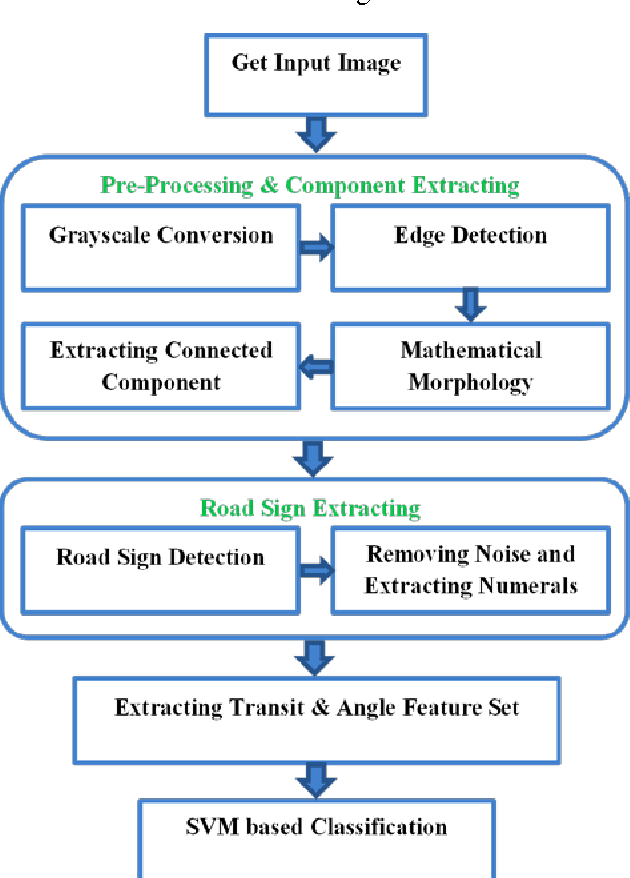
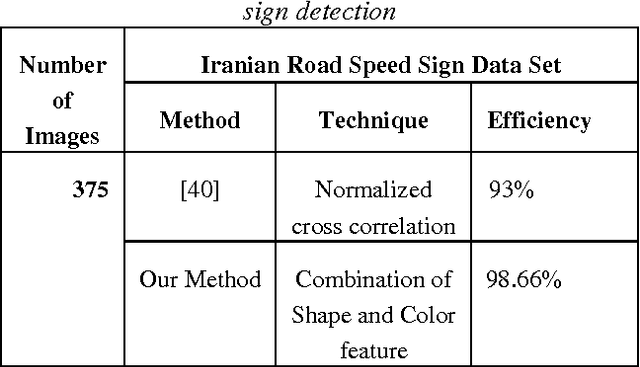

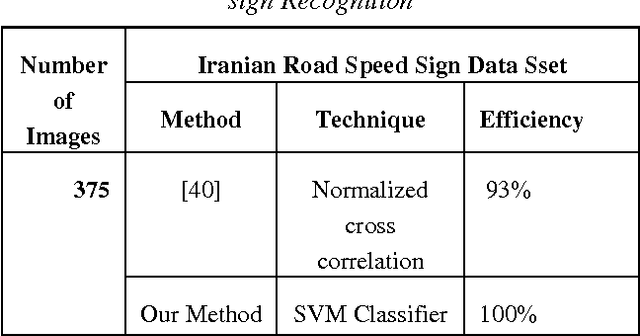
Road sign recognition is one of the core technologies in Intelligent Transport Systems. In the current study, a robust and real-time method is presented to identify and detect the roads speed signs in road image in different situations. In our proposed method, first, the connected components are created in the main image using the edge detection and mathematical morphology and the location of the road signs extracted by the geometric and color data; then the letters are segmented and recognized by Multiclass Support Vector Machine (SVMs) classifiers. Regarding that the geometric and color features ate properly used in detection the location of the road signs, so it is not sensitive to the distance and noise and has higher speed and efficiency. In the result part, the proposed approach is applied on Iranian road speed sign database and the detection and recognition accuracy rate achieved 98.66% and 100% respectively.