 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairEnc: A Fair Vision-Language Model with Fair Vision and Text Encoders for Glaucoma Detection
May 06, 2026Automated glaucoma detection is critical for preventing irreversible vision loss and reducing the burden on healthcare systems. However, ensuring fairness across diverse patient populations remains a significant challenge. In this paper, we propose FairEnc, a fair pretraining method for vision-language models (VLMs) that enables simultaneous debiasing across multiple sensitive attributes. FairEnc jointly mitigates biases in both textual and visual modalities with respect to multiple sensitive attributes, including race, gender, ethnicity, and language. Specifically, for the textual encoder, we leverage a large language model to generate synthetic clinical descriptions with varied sensitive attributes while preserving disease semantics, and employ a contrastive alignment objective to encourage demographic-invariant representations. For the visual encoder, we propose a dual-level fairness strategy that combines mutual information regularization to reduce statistical dependence between learned features and demographic groups, with multi-discriminator adversarial debiasing. Comprehensive experiments on the publicly available Harvard-FairVLMed dataset demonstrate that FairEnc effectively reduces demographic disparity as measured by DPD and DEOdds while achieving strong diagnostic performance under both zero-shot and linear probing evaluations. Additional experiments on the private FairFundus dataset show that FairEnc consistently preserves fairness advantages under cross-domain and cross-modality settings and maintains diagnostic performance within a competitive range. These results highlight FairEnc's ability to generalize fairness under distribution shifts, supporting its potential for more equitable deployment in real-world clinical settings. Our codebase and synthetic clinical notes are available at https://github.com/Mohamed-Elhabebe/FairEnc
Autonomous Extraction of Gleason Patterns for Grading Prostate Cancer using Multi-Gigapixel Whole Slide Images
Nov 01, 2020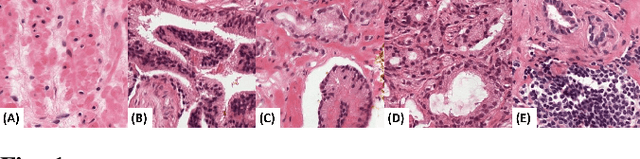
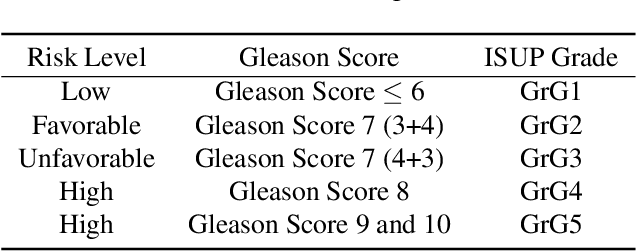
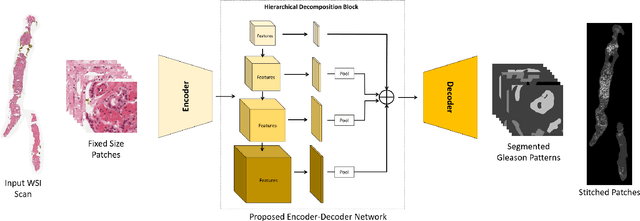
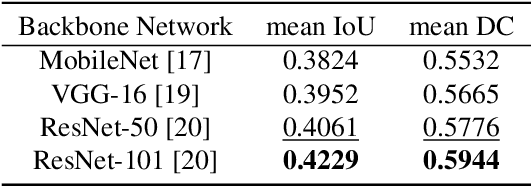
Prostate cancer (PCa) is the second deadliest form of cancer in males. The severity of PCa can be clinically graded through the Gleason scores obtained by examining the structural representation of Gleason cellular patterns. This paper presents an asymmetric encoder-decoder model that integrates a novel hierarchical decomposition block to exploit the feature representations pooled across various scales and then fuses them together to generate the Gleason cellular patterns using the whole slide images. Furthermore, the proposed network is penalized through a novel three-tiered hybrid loss function which ensures that the proposed model accurately recognizes the cluttered regions of the cancerous tissues despite having similar contextual and textural characteristics. We have rigorously tested the proposed network on 10,516 whole slide scans (containing around 71.7M patches), where the proposed model achieved 3.59\% improvement over state-of-the-art scene parsing, encoder-decoder, and fully convolutional networks in terms of intersection-over-union.
Alzheimer's Disease Diagnostics by a Deeply Supervised Adaptable 3D Convolutional Network
Jul 02, 2016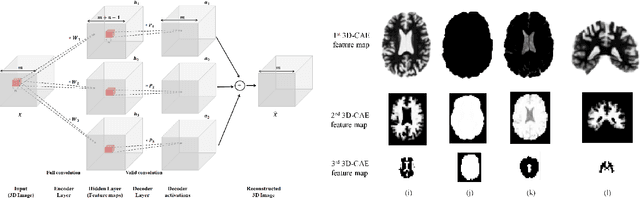
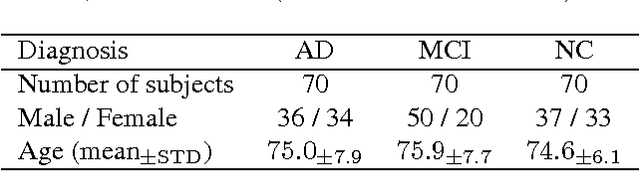
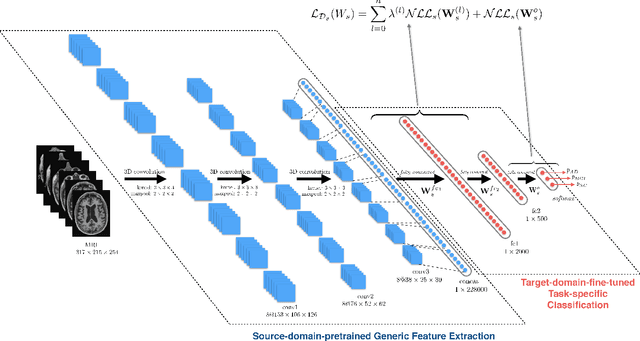

Early diagnosis, playing an important role in preventing progress and treating the Alzheimer's disease (AD), is based on classification of features extracted from brain images. The features have to accurately capture main AD-related variations of anatomical brain structures, such as, e.g., ventricles size, hippocampus shape, cortical thickness, and brain volume. This paper proposes to predict the AD with a deep 3D convolutional neural network (3D-CNN), which can learn generic features capturing AD biomarkers and adapt to different domain datasets. The 3D-CNN is built upon a 3D convolutional autoencoder, which is pre-trained to capture anatomical shape variations in structural brain MRI scans. Fully connected upper layers of the 3D-CNN are then fine-tuned for each task-specific AD classification. Experiments on the \emph{ADNI} MRI dataset with no skull-stripping preprocessing have shown our 3D-CNN outperforms several conventional classifiers by accuracy and robustness. Abilities of the 3D-CNN to generalize the features learnt and adapt to other domains have been validated on the \emph{CADDementia} dataset.
Alzheimer's Disease Diagnostics by Adaptation of 3D Convolutional Network
Jul 02, 2016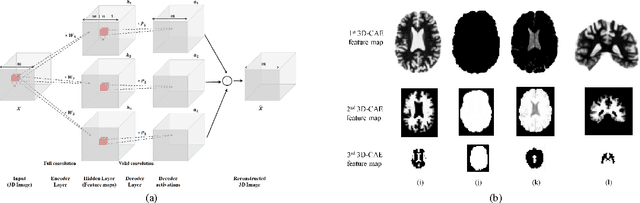
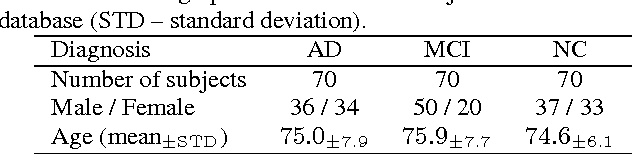
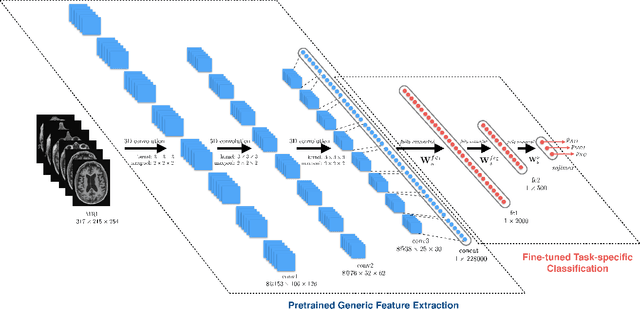
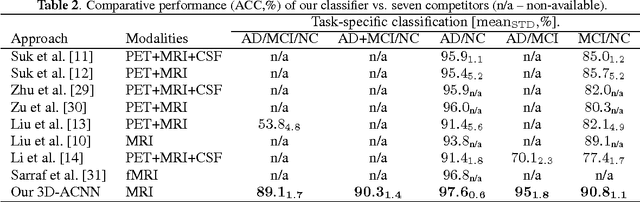
Early diagnosis, playing an important role in preventing progress and treating the Alzheimer\{'}s disease (AD), is based on classification of features extracted from brain images. The features have to accurately capture main AD-related variations of anatomical brain structures, such as, e.g., ventricles size, hippocampus shape, cortical thickness, and brain volume. This paper proposed to predict the AD with a deep 3D convolutional neural network (3D-CNN), which can learn generic features capturing AD biomarkers and adapt to different domain datasets. The 3D-CNN is built upon a 3D convolutional autoencoder, which is pre-trained to capture anatomical shape variations in structural brain MRI scans. Fully connected upper layers of the 3D-CNN are then fine-tuned for each task-specific AD classification. Experiments on the CADDementia MRI dataset with no skull-stripping preprocessing have shown our 3D-CNN outperforms several conventional classifiers by accuracy. Abilities of the 3D-CNN to generalize the features learnt and adapt to other domains have been validated on the ADNI dataset.