 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Guided Agentic Floor Plan Parsing for Accessible Indoor Navigation of Blind and Low-Vision People
Apr 27, 2026Indoor navigation remains a critical accessibility challenge for the blind and low-vision (BLV) individuals, as existing solutions rely on costly per-building infrastructure. We present an agentic framework that converts a single floor plan image into a structured, retrievable knowledge base to generate safe, accessible navigation instructions with lightweight infrastructure. The system has two phases: a multi-agent module that parses the floor plan into a spatial knowledge graph through a self-correcting pipeline with iterative retry loops and corrective feedback; and a Path Planner that generates accessible navigation instructions, with a Safety Evaluator agent assessing potential hazards along each route. We evaluate the system on the real-world UMBC Math and Psychology building (floors MP-1 and MP-3) and on the CVC-FP benchmark. On MP-1, we achieve success rates of 92.31%, 76.92%, and 61.54% for short, medium, and long routes, outperforming the strongest single-call baseline (Claude 3.7 Sonnet) at 84.62%, 69.23%, and 53.85%. On MP-3, we reach 76.92%, 61.54%, and 38.46%, compared to the best baseline at 61.54%, 46.15%, and 23.08%. These results show consistent gains over single-call LLM baselines and demonstrate that our workflow is a scalable solution for accessible indoor navigation for BLV individuals.
WildfireVLM: AI-powered Analysis for Early Wildfire Detection and Risk Assessment Using Satellite Imagery
Feb 09, 2026Wildfires are a growing threat to ecosystems, human lives, and infrastructure, with their frequency and intensity rising due to climate change and human activities. Early detection is critical, yet satellite-based monitoring remains challenging due to faint smoke signals, dynamic weather conditions, and the need for real-time analysis over large areas. We introduce WildfireVLM, an AI framework that combines satellite imagery wildfire detection with language-driven risk assessment. We construct a labeled wildfire and smoke dataset using imagery from Landsat-8/9, GOES-16, and other publicly available Earth observation sources, including harmonized products with aligned spectral bands. WildfireVLM employs YOLOv12 to detect fire zones and smoke plumes, leveraging its ability to detect small, complex patterns in satellite imagery. We integrate Multimodal Large Language Models (MLLMs) that convert detection outputs into contextualized risk assessments and prioritized response recommendations for disaster management. We validate the quality of risk reasoning using an LLM-as-judge evaluation with a shared rubric. The system is deployed using a service-oriented architecture that supports real-time processing, visual risk dashboards, and long-term wildfire tracking, demonstrating the value of combining computer vision with language-based reasoning for scalable wildfire monitoring.
Floorplan2Guide: LLM-Guided Floorplan Parsing for BLV Indoor Navigation
Dec 13, 2025Indoor navigation remains a critical challenge for people with visual impairments. The current solutions mainly rely on infrastructure-based systems, which limit their ability to navigate safely in dynamic environments. We propose a novel navigation approach that utilizes a foundation model to transform floor plans into navigable knowledge graphs and generate human-readable navigation instructions. Floorplan2Guide integrates a large language model (LLM) to extract spatial information from architectural layouts, reducing the manual preprocessing required by earlier floorplan parsing methods. Experimental results indicate that few-shot learning improves navigation accuracy in comparison to zero-shot learning on simulated and real-world evaluations. Claude 3.7 Sonnet achieves the highest accuracy among the evaluated models, with 92.31%, 76.92%, and 61.54% on the short, medium, and long routes, respectively, under 5-shot prompting of the MP-1 floor plan. The success rate of graph-based spatial structure is 15.4% higher than that of direct visual reasoning among all models, which confirms that graphical representation and in-context learning enhance navigation performance and make our solution more precise for indoor navigation of Blind and Low Vision (BLV) users.
Representation Learning using Graph Autoencoders with Residual Connections
May 03, 2021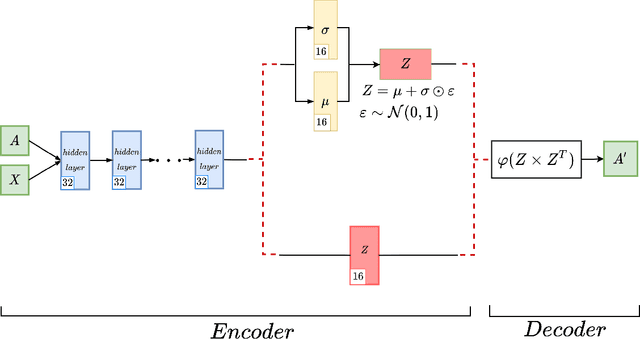
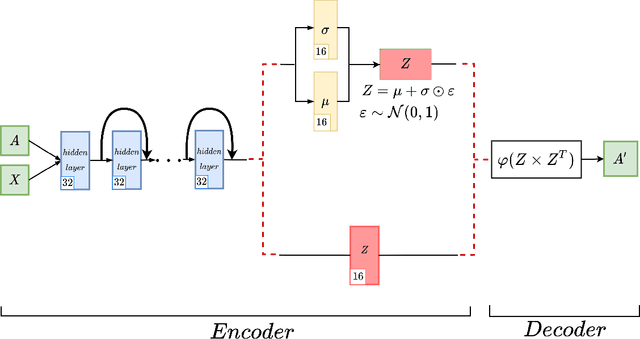
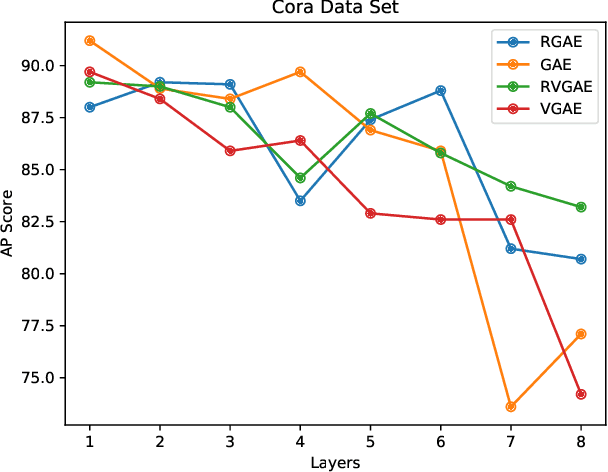
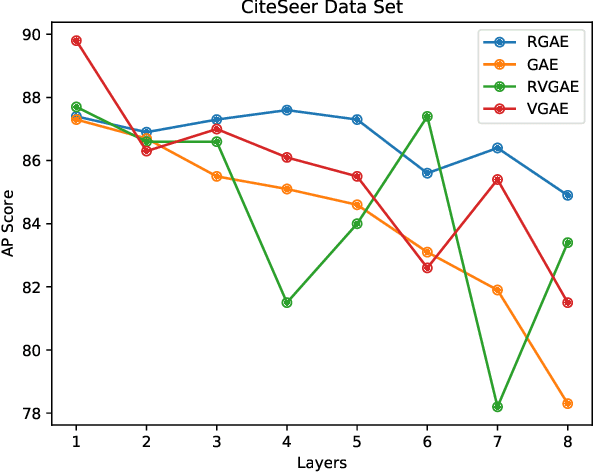
Graph autoencoders are very efficient at embedding graph-based complex data sets. However, most of the autoencoders have shallow depths and their efficiency tends to decrease with the increase of layer depth. In this paper, we study the effect of adding residual connections to shallow and deep graph variational and vanilla autoencoders. We show that residual connections improve the accuracy of the deep graph-based autoencoders. Furthermore, we propose Res-VGAE, a graph variational autoencoder with different residual connections. Our experiments show that our model achieves superior results when compared with other autoencoder-based models for the link prediction task.
PURSUhInT: In Search of Informative Hint Points Based on Layer Clustering for Knowledge Distillation
Feb 26, 2021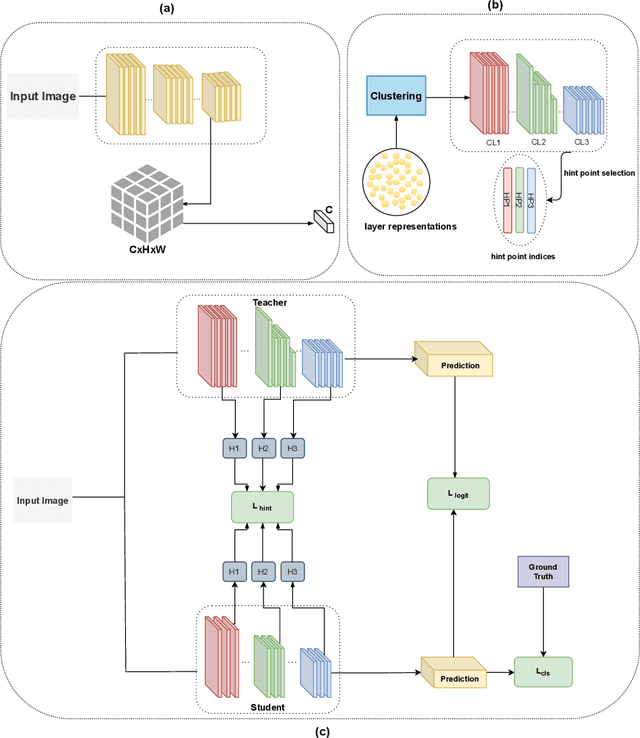
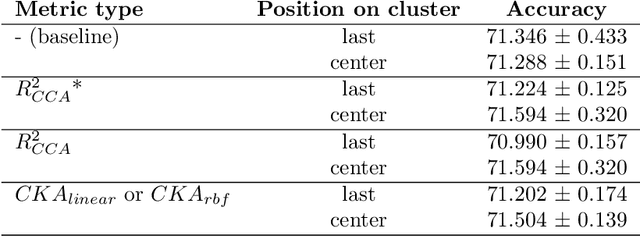
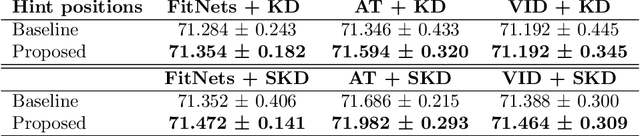
We propose a novel knowledge distillation methodology for compressing deep neural networks. One of the most efficient methods for knowledge distillation is hint distillation, where the student model is injected with information (hints) from several different layers of the teacher model. Although the selection of hint points can drastically alter the compression performance, there is no systematic approach for selecting them, other than brute-force hyper-parameter search. We propose a clustering based hint selection methodology, where the layers of teacher model are clustered with respect to several metrics and the cluster centers are used as the hint points. The proposed approach is validated in CIFAR-100 dataset, where ResNet-110 network was used as the teacher model. Our results show that hint points selected by our algorithm results in superior compression performance with respect to state-of-the-art knowledge distillation algorithms on the same student models and datasets.
Gaussian Three-Dimensional kernel SVM for Edge Detection Applications
Sep 30, 2017
This paper presents a novel and uniform algorithm for edge detection based on SVM (support vector machine) with Three-dimensional Gaussian radial basis function with kernel. Because of disadvantages in traditional edge detection such as inaccurate edge location, rough edge and careless on detect soft edge. The experimental results indicate how the SVM can detect edge in efficient way. The performance of the proposed algorithm is compared with existing methods, including Sobel and canny detectors. The results show that this method is better than classical algorithm such as canny and Sobel detector.