 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Knee X-ray Report Generation
May 22, 2021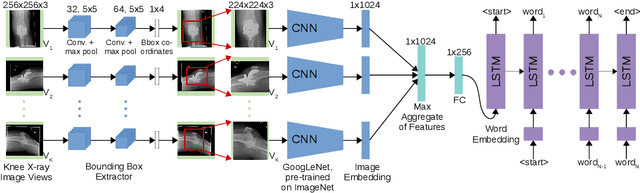

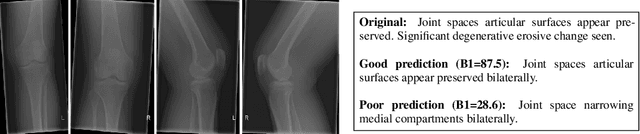
Gathering manually annotated images for the purpose of training a predictive model is far more challenging in the medical domain than for natural images as it requires the expertise of qualified radiologists. We therefore propose to take advantage of past radiological exams (specifically, knee X-ray examinations) and formulate a framework capable of learning the correspondence between the images and reports, and hence be capable of generating diagnostic reports for a given X-ray examination consisting of an arbitrary number of image views. We demonstrate how aggregating the image features of individual exams and using them as conditional inputs when training a language generation model results in auto-generated exam reports that correlate well with radiologist-generated reports.
Automated Enriched Medical Concept Generation for Chest X-ray Images
Oct 07, 2019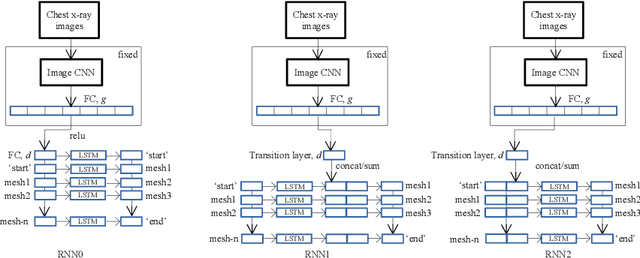
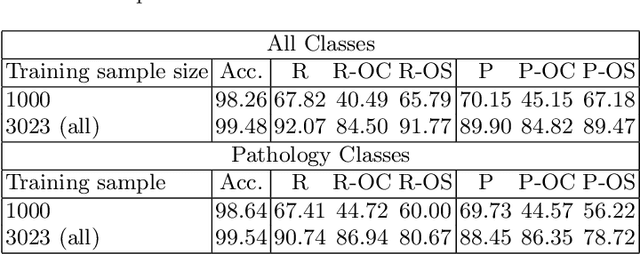
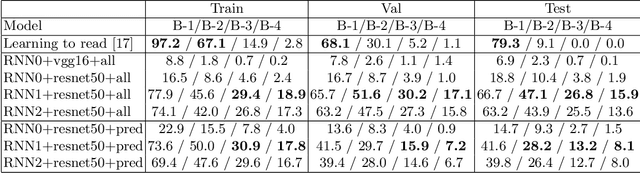
Decision support tools that rely on supervised learning require large amounts of expert annotations. Using past radiological reports obtained from hospital archiving systems has many advantages as training data above manual single-class labels: they are expert annotations available in large quantities, covering a population-representative variety of pathologies, and they provide additional context to pathology diagnoses, such as anatomical location and severity. Learning to auto-generate such reports from images present many challenges such as the difficulty in representing and generating long, unstructured textual information, accounting for spelling errors and repetition/redundancy, and the inconsistency across different annotators. We therefore propose to first learn visually-informative medical concepts from raw reports, and, using the concept predictions as image annotations, learn to auto-generate structured reports directly from images. We validate our approach on the OpenI [2] chest x-ray dataset, which consists of frontal and lateral views of chest x-ray images, their corresponding raw textual reports and manual medical subject heading (MeSH ) annotations made by radiologists.