 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ubiquitous Sparse Matrix-Matrix Products
Aug 06, 2025Multiplication of a sparse matrix with another (dense or sparse) matrix is a fundamental operation that captures the computational patterns of many data science applications, including but not limited to graph algorithms, sparsely connected neural networks, graph neural networks, clustering, and many-to-many comparisons of biological sequencing data. In many application scenarios, the matrix multiplication takes places on an arbitrary algebraic semiring where the scalar operations are overloaded with user-defined functions with certain properties or a more general heterogenous algebra where even the domains of the input matrices can be different. Here, we provide a unifying treatment of the sparse matrix-matrix operation and its rich application space including machine learning, computational biology and chemistry, graph algorithms, and scientific computing.
A High-Throughput Solver for Marginalized Graph Kernels on GPU
Oct 16, 2019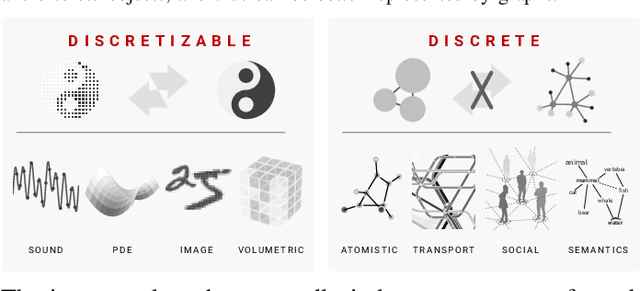
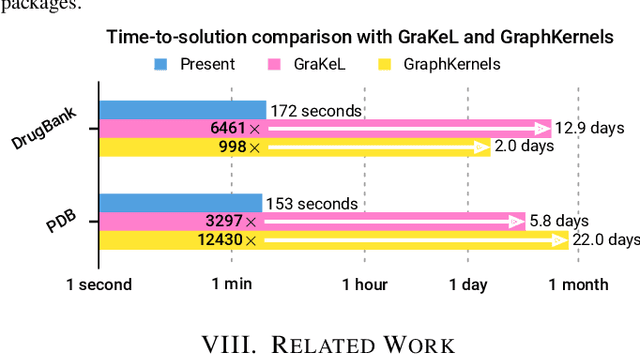
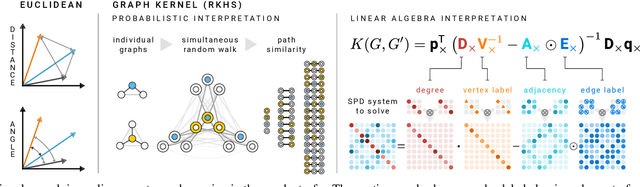
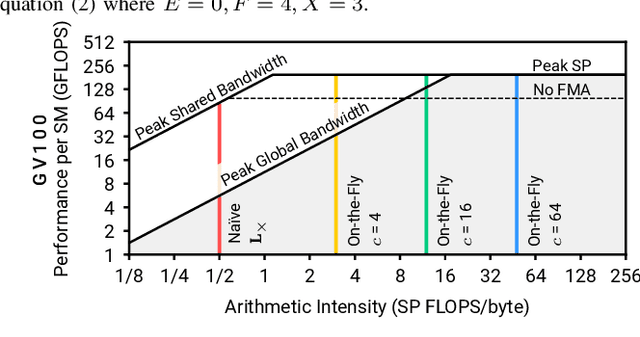
We present the design and optimization of a solver for efficient and high-throughput computation of the marginalized graph kernel on General Purpose GPUs. The graph kernel is computed using the conjugate gradient method to solve a generalized Laplacian of the tensor product between a pair of graphs. To cope with the large gap between the instruction throughput and the memory bandwidth of the GPUs, our solver forms the graph tensor product on-the-fly without storing it in memory. This is achieved by using threads in a warp cooperatively to stream the adjacency and edge label matrices of individual graphs by small square matrix blocks called tiles, which are then staged in registers and the shared memory for later reuse. Warps across a thread block can further share tiles via the shared memory to increase data reuse. We exploit the sparsity of the graphs hierarchically by storing only non-empty tiles using a coordinate format and nonzero elements within each tile using bitmaps. We propose a new partition-based reordering algorithm for aggregating nonzero elements of the graphs into fewer but denser tiles to further exploit sparsity. We carry out extensive theoretical analyses on the graph tensor product primitives for tiles of various density and evaluate their performance on synthetic and real-world datasets. Our solver delivers three to four orders of magnitude speedup over existing CPU-based solvers such as GraKeL and GraphKernels. The capability of the solver enables kernel-based learning tasks at unprecedented scales.