 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Answer Type and Relation Prediction Task (SMART 2021)
Jan 10, 2022
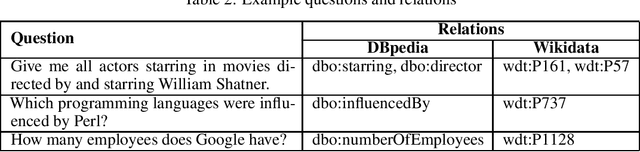
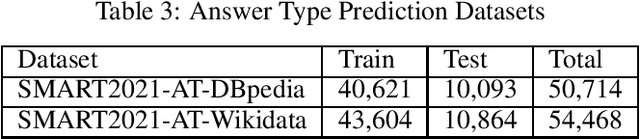
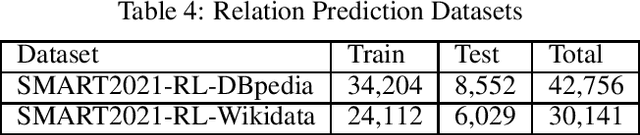
Each year the International Semantic Web Conference organizes a set of Semantic Web Challenges to establish competitions that will advance state-of-the-art solutions in some problem domains. The Semantic Answer Type and Relation Prediction Task (SMART) task is one of the ISWC 2021 Semantic Web challenges. This is the second year of the challenge after a successful SMART 2020 at ISWC 2020. This year's version focuses on two sub-tasks that are very important to Knowledge Base Question Answering (KBQA): Answer Type Prediction and Relation Prediction. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights about the expected answer that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the first task is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata. Similarly, the second task is to identify relations in the natural language query and link them to the relations in a target ontology. This paper discusses the task descriptions, benchmark datasets, and evaluation metrics. For more information, please visit https://smart-task.github.io/2021/.
Neural Class Expression Synthesis
Nov 18, 2021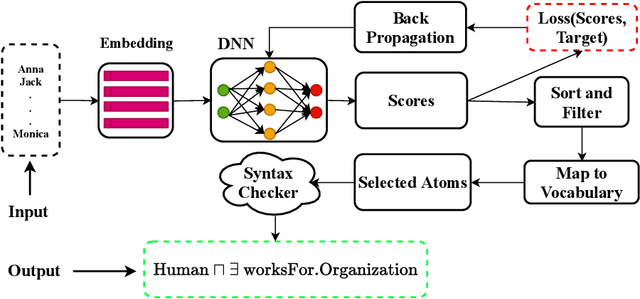

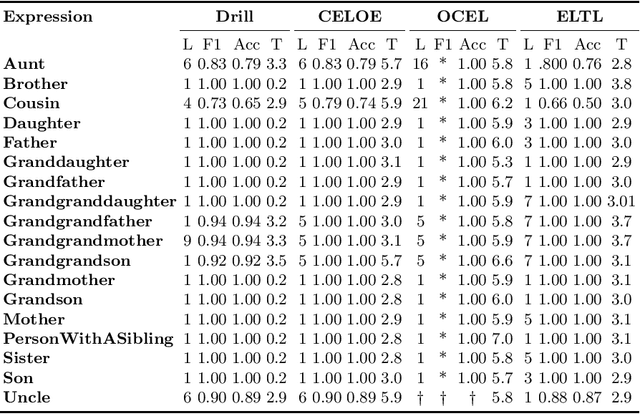
Class expression learning is a branch of explainable supervised machine learning of increasing importance. Most existing approaches for class expression learning in description logics are search algorithms or hard-rule-based. In particular, approaches based on refinement operators suffer from scalability issues as they rely on heuristic functions to explore a large search space for each learning problem. We propose a new family of approaches, which we dub synthesis approaches. Instances of this family compute class expressions directly from the examples provided. Consequently, they are not subject to the runtime limitations of search-based approaches nor the lack of flexibility of hard-rule-based approaches. We study three instances of this novel family of approaches that use lightweight neural network architectures to synthesize class expressions from sets of positive examples. The results of their evaluation on four benchmark datasets suggest that they can effectively synthesize high-quality class expressions with respect to the input examples in under a second on average. Moreover, a comparison with the state-of-the-art approaches CELOE and ELTL suggests that we achieve significantly better F-measures on large ontologies. For reproducibility purposes, we provide our implementation as well as pre-trained models in the public GitHub repository at https://github.com/ConceptLengthLearner/NCES
EvoLearner: Learning Description Logics with Evolutionary Algorithms
Nov 08, 2021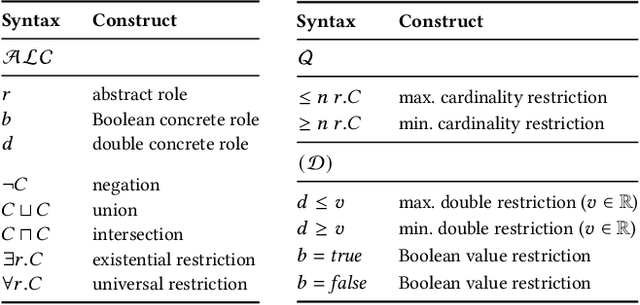
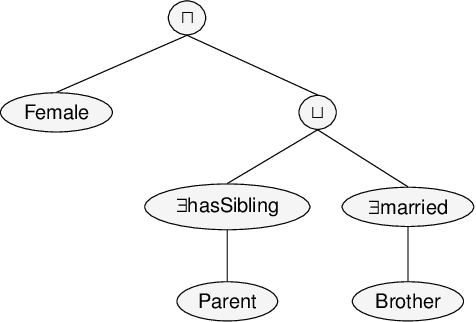
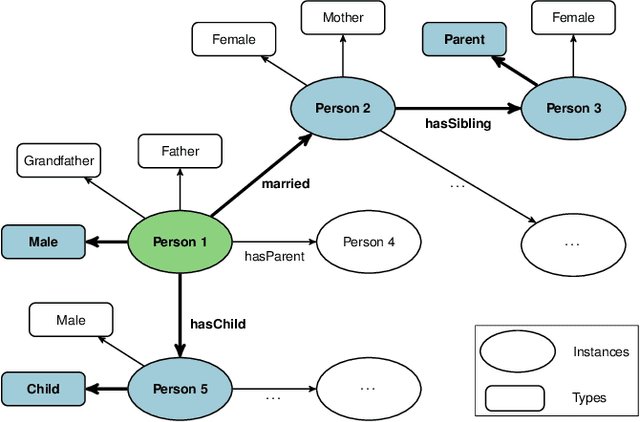
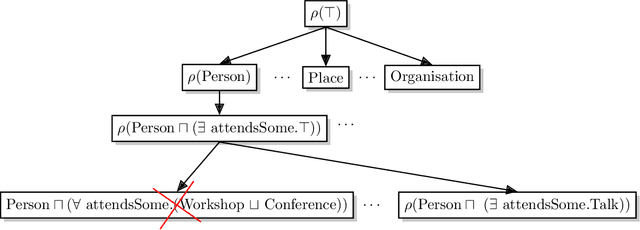
Classifying nodes in knowledge graphs is an important task, e.g., predicting missing types of entities, predicting which molecules cause cancer, or predicting which drugs are promising treatment candidates. While black-box models often achieve high predictive performance, they are only post-hoc and locally explainable and do not allow the learned model to be easily enriched with domain knowledge. Towards this end, learning description logic concepts from positive and negative examples has been proposed. However, learning such concepts often takes a long time and state-of-the-art approaches provide limited support for literal data values, although they are crucial for many applications. In this paper, we propose EvoLearner - an evolutionary approach to learn ALCQ(D), which is the attributive language with complement (ALC) paired with qualified cardinality restrictions (Q) and data properties (D). We contribute a novel initialization method for the initial population: starting from positive examples (nodes in the knowledge graph), we perform biased random walks and translate them to description logic concepts. Moreover, we improve support for data properties by maximizing information gain when deciding where to split the data. We show that our approach significantly outperforms the state of the art on the benchmarking framework SML-Bench for structured machine learning. Our ablation study confirms that this is due to our novel initialization method and support for data properties.
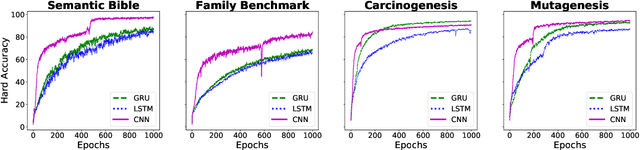
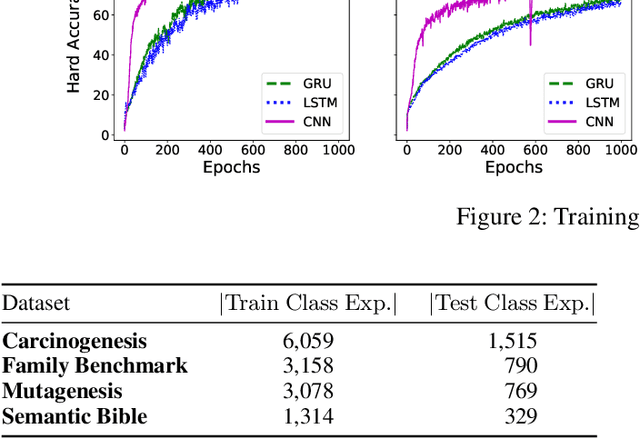
Prediction of concept lengths for fast concept learning in description logics
Jul 10, 2021
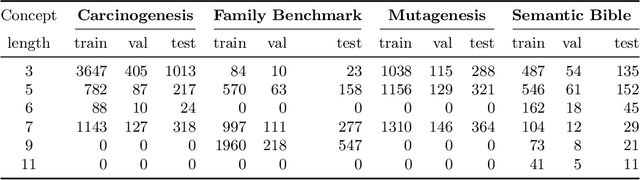
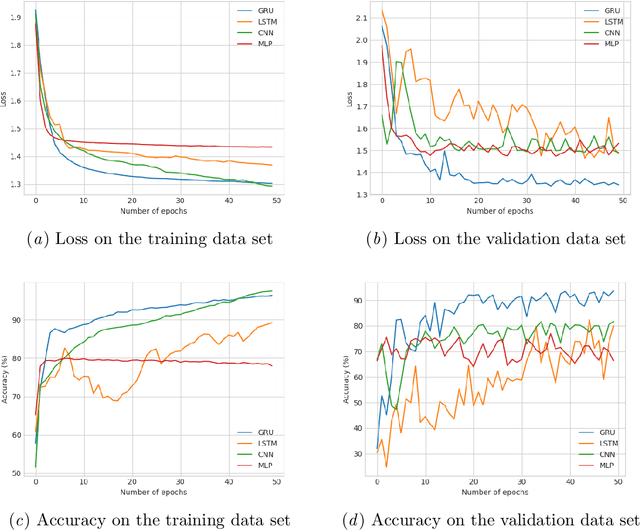
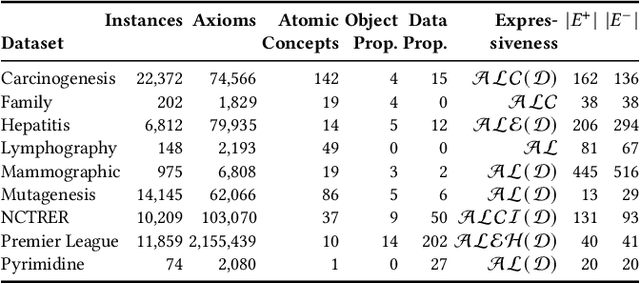
Concept learning approaches based on refinement operators explore partially ordered solution spaces to compute concepts, which are used as binary classification models for individuals. However, the refinement trees spanned by these approaches can easily grow to millions of nodes for complex learning problems. This leads to refinement-based approaches often failing to detect optimal concepts efficiently. In this paper, we propose a supervised machine learning approach for learning concept lengths, which allows predicting the length of the target concept and therefore facilitates the reduction of the search space during concept learning. To achieve this goal, we compare four neural architectures and evaluate them on four benchmark knowledge graphs--Carcinogenesis, Mutagenesis, Semantic Bible, Family Benchmark. Our evaluation results suggest that recurrent neural network architectures perform best at concept length prediction with an F-measure of up to 92%. We show that integrating our concept length predictor into the CELOE (Class Expression Learner for Ontology Engineering) algorithm improves CELOE's runtime by a factor of up to 13.4 without any significant changes to the quality of the results it generates. For reproducibility, we provide our implementation in the public GitHub repository at https://github.com/ConceptLengthLearner/ReproducibilityRepo
DRILL-- Deep Reinforcement Learning for Refinement Operators in $\mathcal{ALC}$
Jun 29, 2021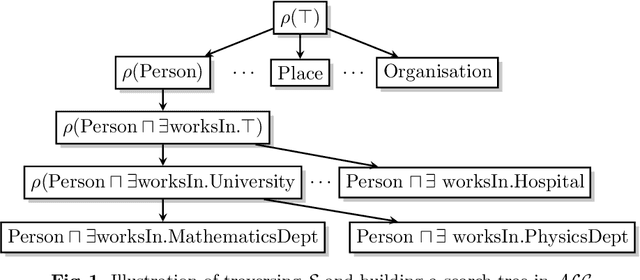


Approaches based on refinement operators have been successfully applied to class expression learning on RDF knowledge graphs. These approaches often need to explore a large number of concepts to find adequate hypotheses. This need arguably stems from current approaches relying on myopic heuristic functions to guide their search through an infinite concept space. In turn, deep reinforcement learning provides effective means to address myopia by estimating how much discounted cumulated future reward states promise. In this work, we leverage deep reinforcement learning to accelerate the learning of concepts in $\mathcal{ALC}$ by proposing DRILL -- a novel class expression learning approach that uses a convolutional deep Q-learning model to steer its search. By virtue of its architecture, DRILL is able to compute the expected discounted cumulated future reward of more than $10^3$ class expressions in a second on standard hardware. We evaluate DRILL on four benchmark datasets against state-of-the-art approaches. Our results suggest that DRILL converges to goal states at least 2.7$\times$ faster than state-of-the-art models on all benchmark datasets. We provide an open-source implementation of our approach, including training and evaluation scripts as well as pre-trained models.
Convolutional Hypercomplex Embeddings for Link Prediction
Jun 29, 2021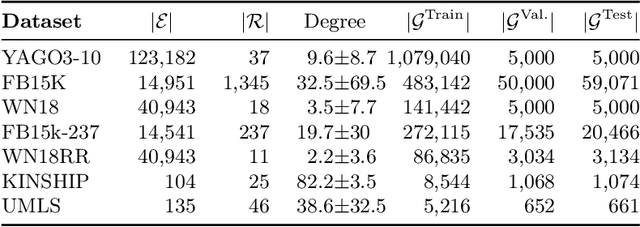
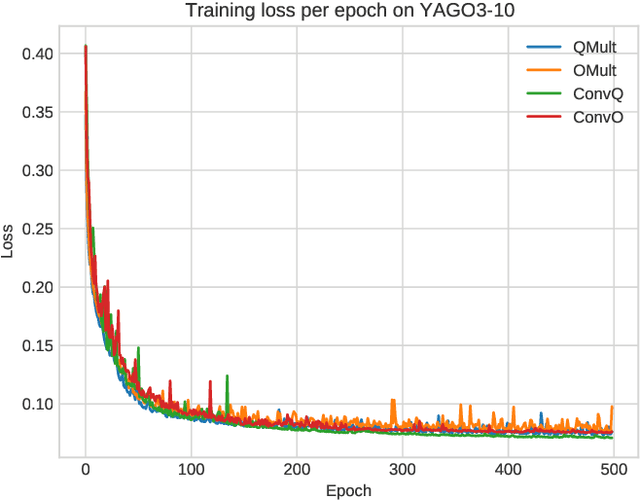
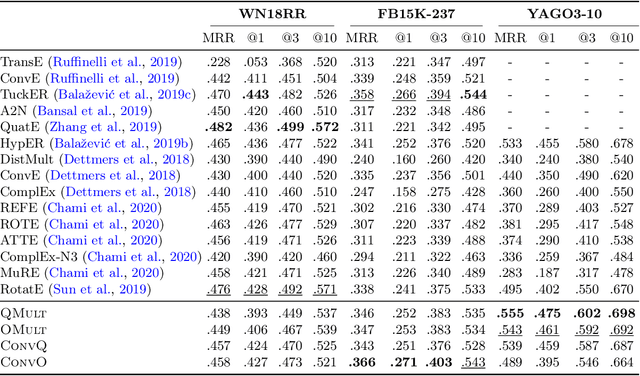
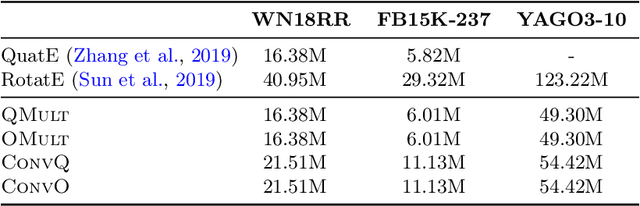
Knowledge graph embedding research has mainly focused on the two smallest normed division algebras, $\mathbb{R}$ and $\mathbb{C}$. Recent results suggest that trilinear products of quaternion-valued embeddings can be a more effective means to tackle link prediction. In addition, models based on convolutions on real-valued embeddings often yield state-of-the-art results for link prediction. In this paper, we investigate a composition of convolution operations with hypercomplex multiplications. We propose the four approaches QMult, OMult, ConvQ and ConvO to tackle the link prediction problem. QMult and OMult can be considered as quaternion and octonion extensions of previous state-of-the-art approaches, including DistMult and ComplEx. ConvQ and ConvO build upon QMult and OMult by including convolution operations in a way inspired by the residual learning framework. We evaluated our approaches on seven link prediction datasets including WN18RR, FB15K-237 and YAGO3-10. Experimental results suggest that the benefits of learning hypercomplex-valued vector representations become more apparent as the size and complexity of the knowledge graph grows. ConvO outperforms state-of-the-art approaches on FB15K-237 in MRR, Hit@1 and Hit@3, while QMult, OMult, ConvQ and ConvO outperform state-of-the-approaches on YAGO3-10 in all metrics. Results also suggest that link prediction performances can be further improved via prediction averaging. To foster reproducible research, we provide an open-source implementation of approaches, including training and evaluation scripts as well as pretrained models.
Out-of-Vocabulary Entities in Link Prediction
May 26, 2021
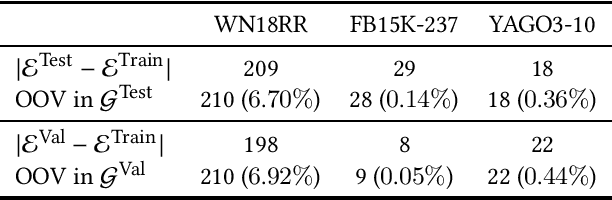
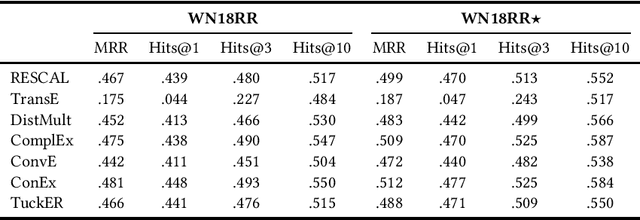
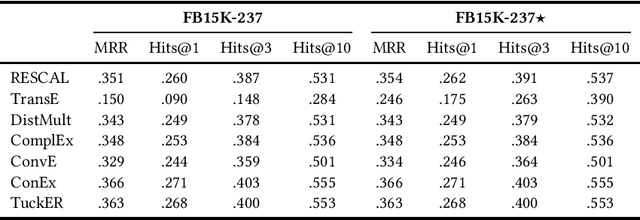
Knowledge graph embedding techniques are key to making knowledge graphs amenable to the plethora of machine learning approaches based on vector representations. Link prediction is often used as a proxy to evaluate the quality of these embeddings. Given that the creation of benchmarks for link prediction is a time-consuming endeavor, most work on the subject matter uses only a few benchmarks. As benchmarks are crucial for the fair comparison of algorithms, ensuring their quality is tantamount to providing a solid ground for developing better solutions to link prediction and ipso facto embedding knowledge graphs. First studies of benchmarks pointed to limitations pertaining to information leaking from the development to the test fragments of some benchmark datasets. We spotted a further common limitation of three of the benchmarks commonly used for evaluating link prediction approaches: out-of-vocabulary entities in the test and validation sets. We provide an implementation of an approach for spotting and removing such entities and provide corrected versions of the datasets WN18RR, FB15K-237, and YAGO3-10. Our experiments on the corrected versions of WN18RR, FB15K-237, and YAGO3-10 suggest that the measured performance of state-of-the-art approaches is altered significantly with p-values <1%, <1.4%, and <1%, respectively. Overall, state-of-the-art approaches gain on average absolute $3.29 \pm 0.24\%$ in all metrics on WN18RR. This means that some of the conclusions achieved in previous works might need to be revisited. We provide an open-source implementation of our experiments and corrected datasets at at https://github.com/dice-group/OOV-In-Link-Prediction.
An Empirical Evaluation of Cost-based Federated SPARQL Query Processing Engines
Apr 02, 2021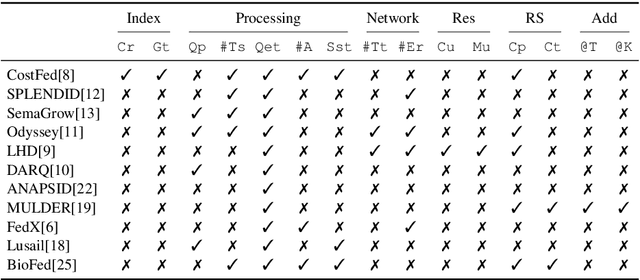
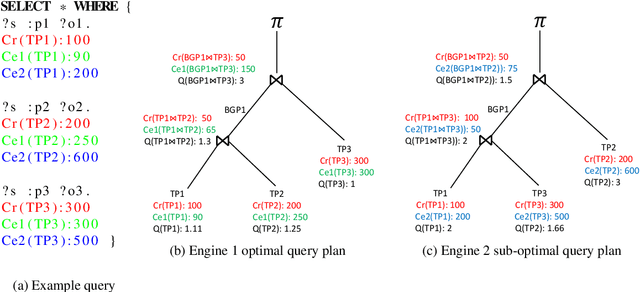
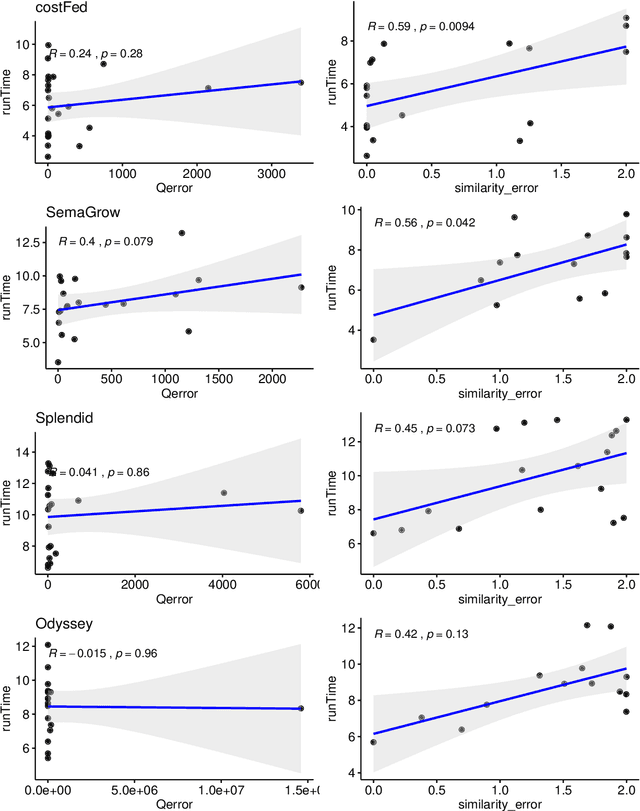
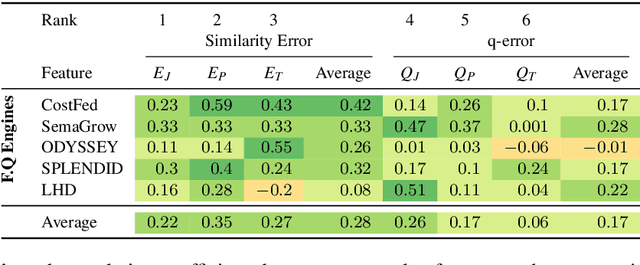
Finding a good query plan is key to the optimization of query runtime. This holds in particular for cost-based federation engines, which make use of cardinality estimations to achieve this goal. A number of studies compare SPARQL federation engines across different performance metrics, including query runtime, result set completeness and correctness, number of sources selected and number of requests sent. Albeit informative, these metrics are generic and unable to quantify and evaluate the accuracy of the cardinality estimators of cost-based federation engines. To thoroughly evaluate cost-based federation engines, the effect of estimated cardinality errors on the overall query runtime performance must be measured. In this paper, we address this challenge by presenting novel evaluation metrics targeted at a fine-grained benchmarking of cost-based federated SPARQL query engines. We evaluate five cost-based federated SPARQL query engines using existing as well as novel evaluation metrics by using LargeRDFBench queries. Our results provide a detailed analysis of the experimental outcomes that reveal novel insights, useful for the development of future cost-based federated SPARQL query processing engines.
* 24 pages, Semantic Web, 2020, #article
Knowledge Graph Question Answering using Graph-Pattern Isomorphism
Mar 11, 2021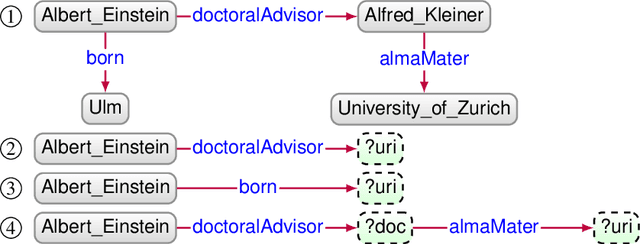

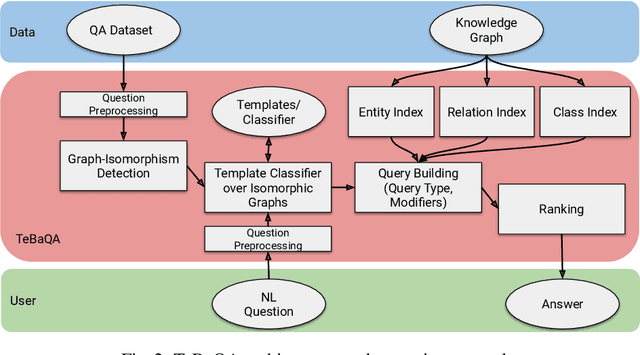

Knowledge Graph Question Answering (KGQA) systems are based on machine learning algorithms, requiring thousands of question-answer pairs as training examples or natural language processing pipelines that need module fine-tuning. In this paper, we present a novel QA approach, dubbed TeBaQA. Our approach learns to answer questions based on graph isomorphisms from basic graph patterns of SPARQL queries. Learning basic graph patterns is efficient due to the small number of possible patterns. This novel paradigm reduces the amount of training data necessary to achieve state-of-the-art performance. TeBaQA also speeds up the domain adaption process by transforming the QA system development task into a much smaller and easier data compilation task. In our evaluation, TeBaQA achieves state-of-the-art performance on QALD-8 and delivers comparable results on QALD-9 and LC-QuAD v1. Additionally, we performed a fine-grained evaluation on complex queries that deal with aggregation and superlative questions as well as an ablation study, highlighting future research challenges.
A shallow neural model for relation prediction
Jan 22, 2021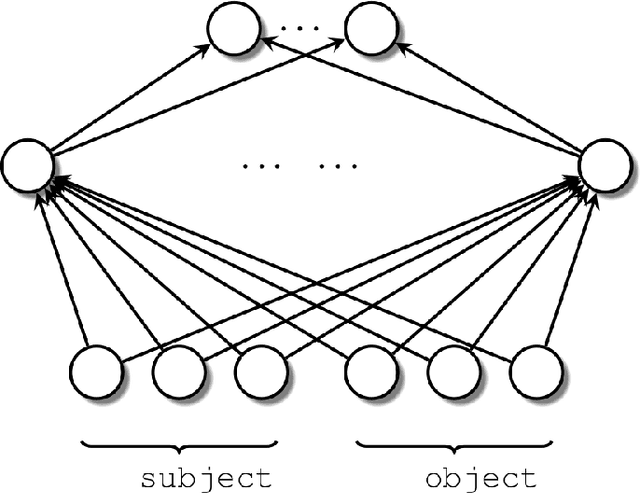
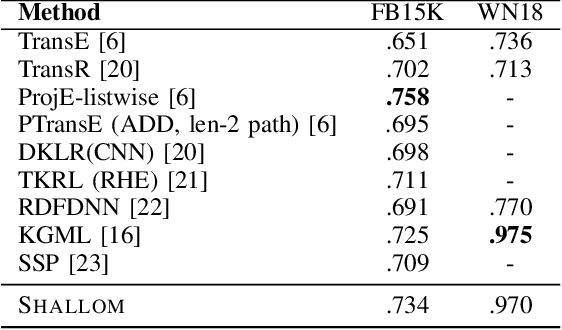
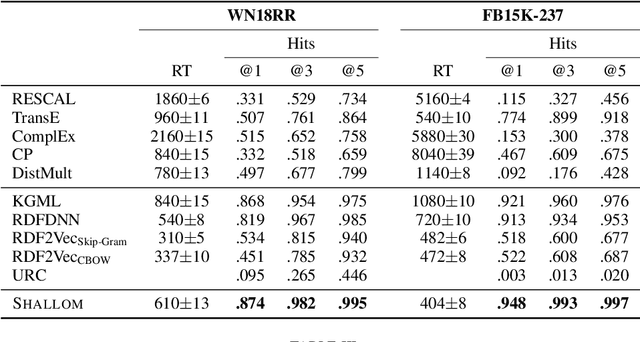

Knowledge graph completion refers to predicting missing triples. Most approaches achieve this goal by predicting entities, given an entity and a relation. We predict missing triples via the relation prediction. To this end, we frame the relation prediction problem as a multi-label classification problem and propose a shallow neural model (SHALLOM) that accurately infers missing relations from entities. SHALLOM is analogous to C-BOW as both approaches predict a central token (p) given surrounding tokens ((s,o)). Our experiments indicate that SHALLOM outperforms state-of-the-art approaches on the FB15K-237 and WN18RR with margins of up to $3\%$ and $8\%$ (absolute), respectively, while requiring a maximum training time of 8 minutes on these datasets. We ensure the reproducibility of our results by providing an open-source implementation including training and evaluation scripts at {\url{https://github.com/dice-group/Shallom}.}