 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Data Removal from Machine Learning Models
Nov 11, 2019
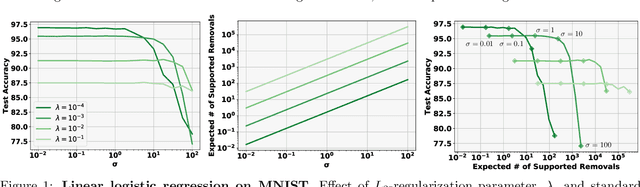
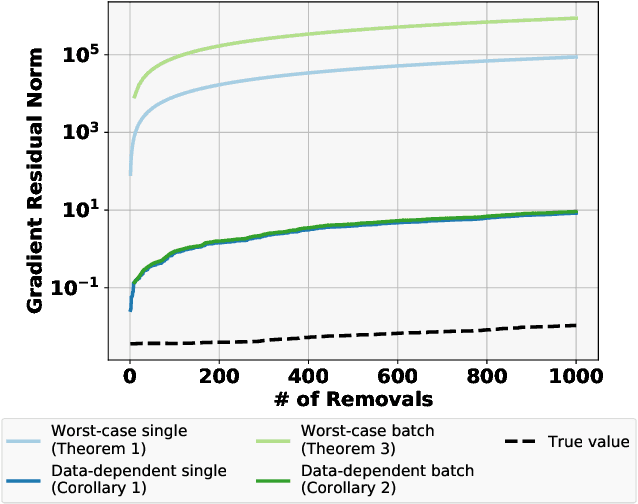

Good data stewardship requires removal of data at the request of the data's owner. This raises the question if and how a trained machine-learning model, which implicitly stores information about its training data, should be affected by such a removal request. Is it possible to "remove" data from a machine-learning model? We study this problem by defining certified removal: a very strong theoretical guarantee that a model from which data is removed cannot be distinguished from a model that never observed the data to begin with. We develop a certified-removal mechanism for linear classifiers and empirically study learning settings in which this mechanism is practical.
Lead2Gold: Towards exploiting the full potential of noisy transcriptions for speech recognition
Oct 16, 2019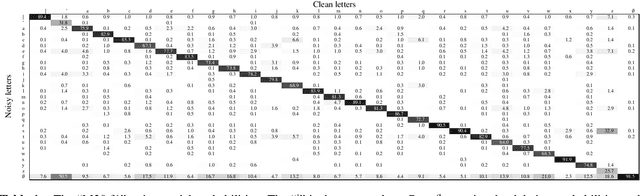
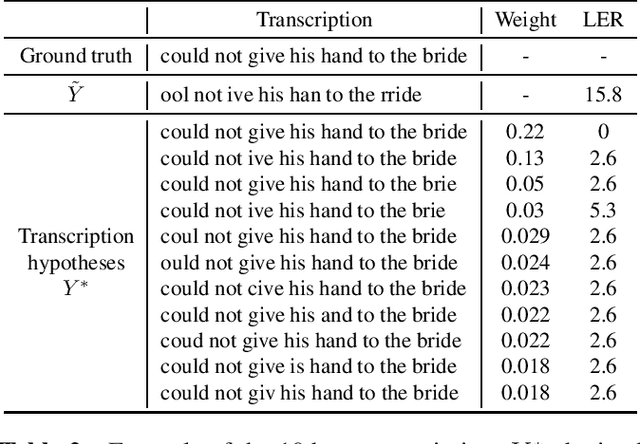
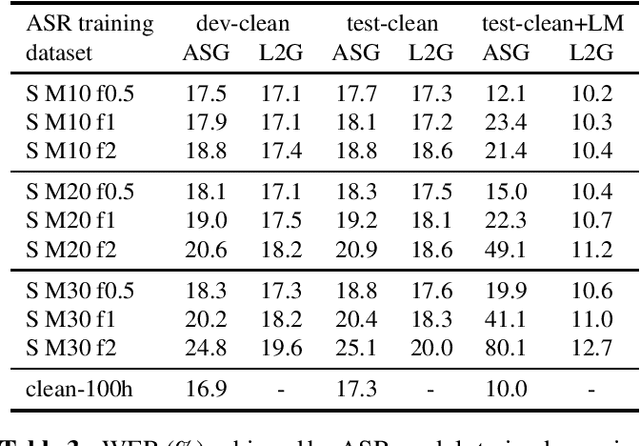
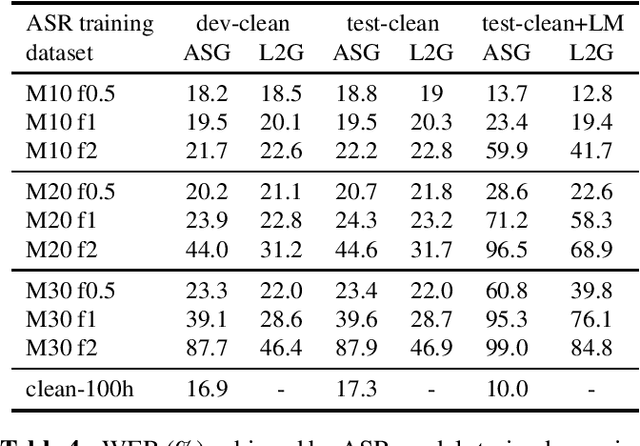
The transcriptions used to train an Automatic Speech Recognition (ASR) system may contain errors. Usually, either a quality control stage discards transcriptions with too many errors, or the noisy transcriptions are used as is. We introduce Lead2Gold, a method to train an ASR system that exploits the full potential of noisy transcriptions. Based on a noise model of transcription errors, Lead2Gold searches for better transcriptions of the training data with a beam search that takes this noise model into account. The beam search is differentiable and does not require a forced alignment step, thus the whole system is trained end-to-end. Lead2Gold can be viewed as a new loss function that can be used on top of any sequence-to-sequence deep neural network. We conduct proof-of-concept experiments on noisy transcriptions generated from letter corruptions with different noise levels. We show that Lead2Gold obtains a better ASR accuracy than a competitive baseline which does not account for the (artificially-introduced) transcription noise.
Privacy-Preserving Contextual Bandits
Oct 14, 2019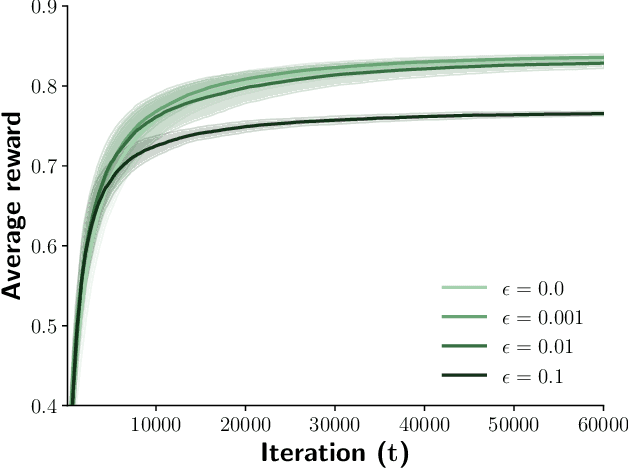
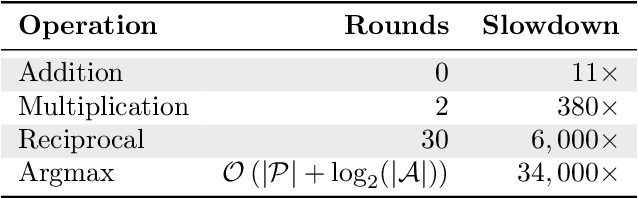
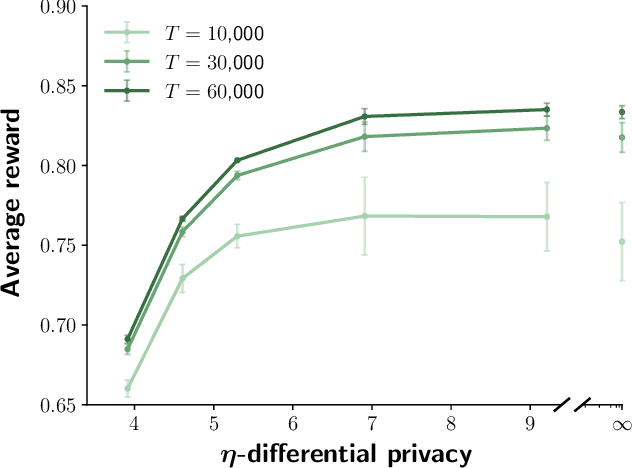
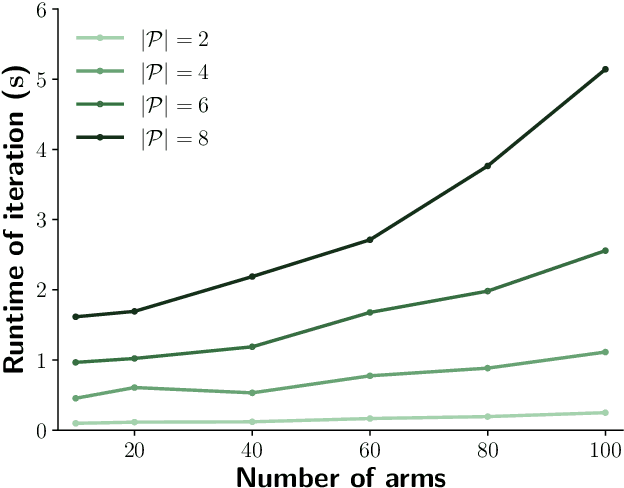
Contextual bandits are online learners that, given an input, select an arm and receive a reward for that arm. They use the reward as a learning signal and aim to maximize the total reward over the inputs. Contextual bandits are commonly used to solve recommendation or ranking problems. This paper considers a learning setting in which multiple parties aim to train a contextual bandit together in a private way: the parties aim to maximize the total reward but do not want to share any of the relevant information they possess with the other parties. Specifically, multiple parties have access to (different) features that may benefit the learner but that cannot be shared with other parties. One of the parties pulls the arm but other parties may not learn which arm was pulled. One party receives the reward but the other parties may not learn the reward value. This paper develops a privacy-preserving contextual bandit algorithm that combines secure multi-party computation with a differential private mechanism based on epsilon-greedy exploration in contextual bandits.
Self-Training for End-to-End Speech Recognition
Sep 19, 2019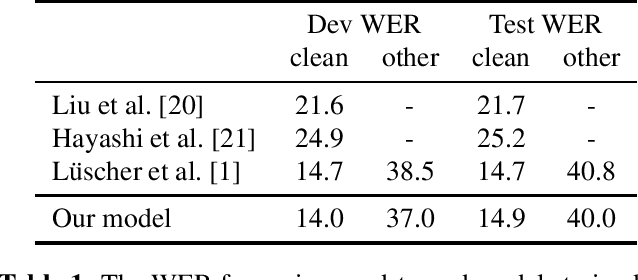
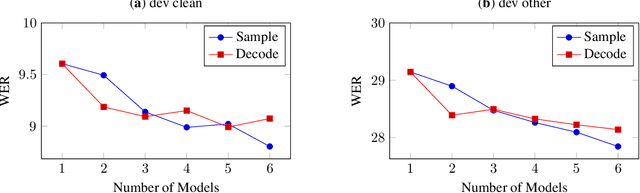
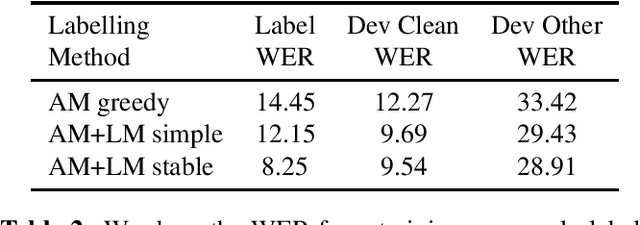
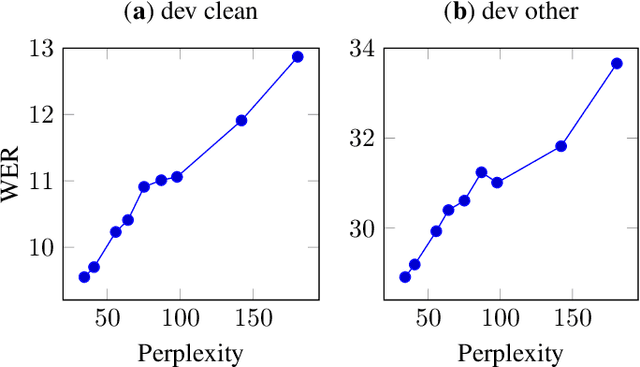
We revisit self-training in the context of end-to-end speech recognition. We demonstrate that training with pseudo-labels can substantially improve the accuracy of a baseline model by leveraging unlabelled data. Key to our approach are a strong baseline acoustic and language model used to generate the pseudo-labels, a robust and stable beam-search decoder, and a novel ensemble approach used to increase pseudo-label diversity. Experiments on the LibriSpeech corpus show that self-training with a single model can yield a 21% relative WER improvement on clean data over a baseline trained on 100 hours of labelled data. We also evaluate label filtering approaches to increase pseudo-label quality. With an ensemble of six models in conjunction with label filtering, self-training yields a 26% relative improvement and bridges 55.6% of the gap between the baseline and an oracle model trained with all of the labels.
Word-level Speech Recognition with a Dynamic Lexicon
Jun 10, 2019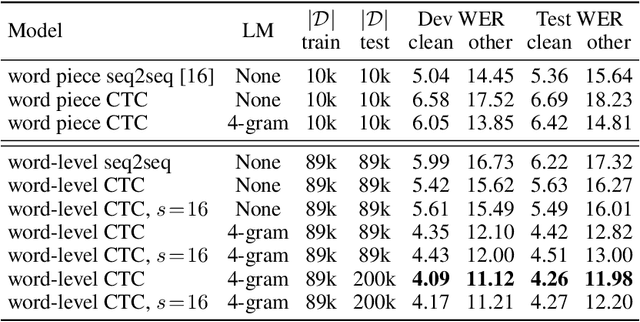
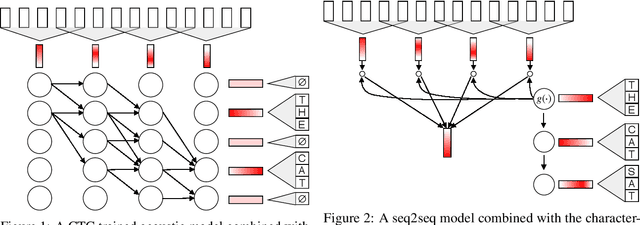

We propose a direct-to-word sequence model with a dynamic lexicon. Our word network constructs word embeddings dynamically from the character level tokens. The word network can be integrated seamlessly with arbitrary sequence models including Connectionist Temporal Classification and encoder-decoder models with attention. Sub-word units are commonly used in speech recognition yet are generated without the use of acoustic context. We show our direct-to-word model can achieve word error rate gains over sub-word level models for speech recognition. Furthermore, we empirically validate that the word-level embeddings we learn contain significant acoustic information, making them more suitable for use in speech recognition. We also show that our direct-to-word approach retains the ability to predict words not seen at training time without any retraining.
Sequence-to-Sequence Speech Recognition with Time-Depth Separable Convolutions
Apr 04, 2019
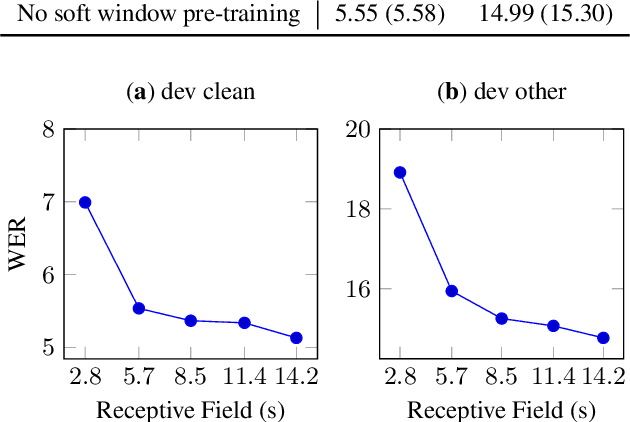
We propose a fully convolutional sequence-to-sequence encoder architecture with a simple and efficient decoder. Our model improves WER on LibriSpeech while being an order of magnitude more efficient than a strong RNN baseline. Key to our approach is a time-depth separable convolution block which dramatically reduces the number of parameters in the model while keeping the receptive field large. We also give a stable and efficient beam search inference procedure which allows us to effectively integrate a language model. Coupled with a convolutional language model, our time-depth separable convolution architecture improves by more than 22% relative WER over the best previously reported sequence-to-sequence results on the noisy LibriSpeech test set.
A Fully Differentiable Beam Search Decoder
Feb 16, 2019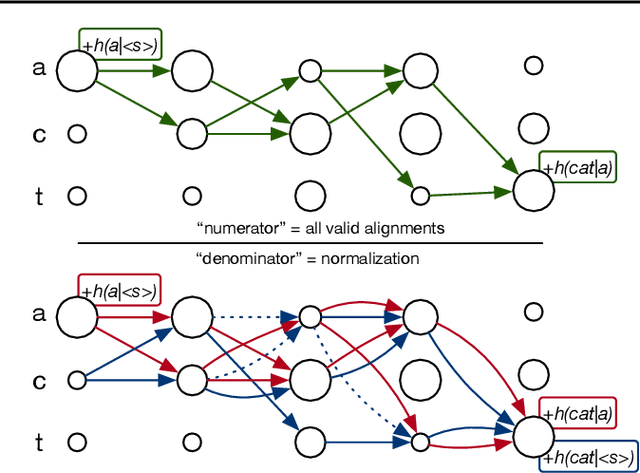
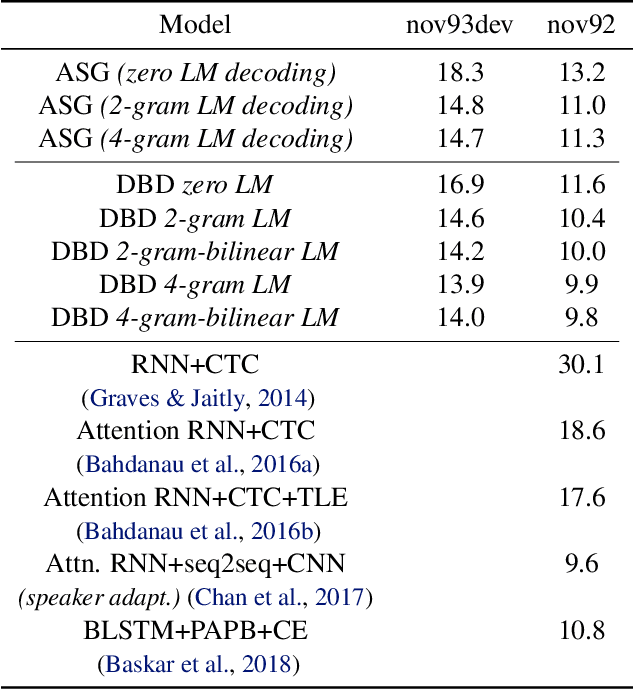
We introduce a new beam search decoder that is fully differentiable, making it possible to optimize at training time through the inference procedure. Our decoder allows us to combine models which operate at different granularities (e.g. acoustic and language models). It can be used when target sequences are not aligned to input sequences by considering all possible alignments between the two. We demonstrate our approach scales by applying it to speech recognition, jointly training acoustic and word-level language models. The system is end-to-end, with gradients flowing through the whole architecture from the word-level transcriptions. Recent research efforts have shown that deep neural networks with attention-based mechanisms are powerful enough to successfully train an acoustic model from the final transcription, while implicitly learning a language model. Instead, we show that it is possible to discriminatively train an acoustic model jointly with an explicit and possibly pre-trained language model.
wav2letter++: The Fastest Open-source Speech Recognition System
Dec 18, 2018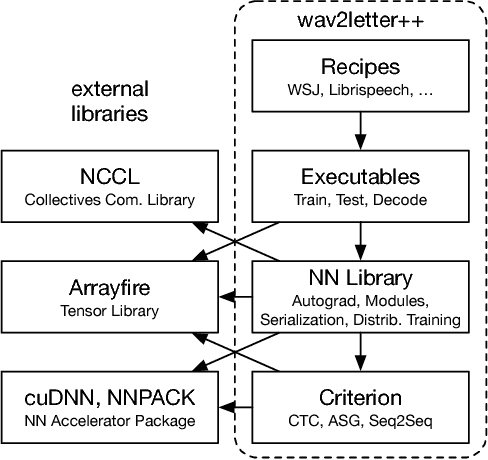
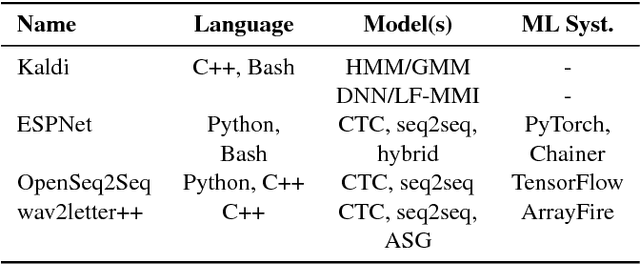

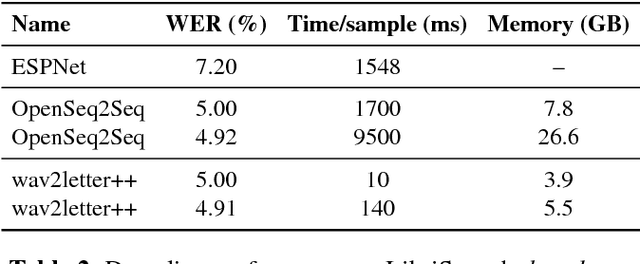
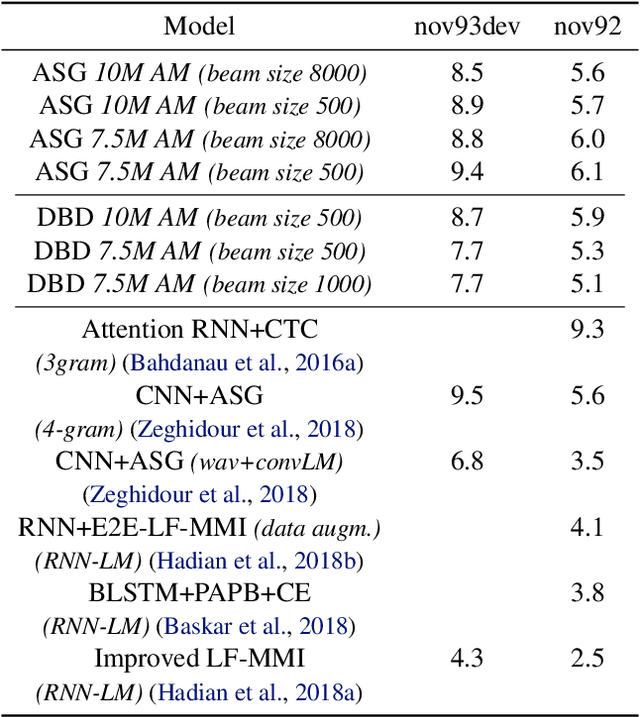
This paper introduces wav2letter++, the fastest open-source deep learning speech recognition framework. wav2letter++ is written entirely in C++, and uses the ArrayFire tensor library for maximum efficiency. Here we explain the architecture and design of the wav2letter++ system and compare it to other major open-source speech recognition systems. In some cases wav2letter++ is more than 2x faster than other optimized frameworks for training end-to-end neural networks for speech recognition. We also show that wav2letter++'s training times scale linearly to 64 GPUs, the highest we tested, for models with 100 million parameters. High-performance frameworks enable fast iteration, which is often a crucial factor in successful research and model tuning on new datasets and tasks.
An End-to-End Architecture for Keyword Spotting and Voice Activity Detection
Nov 28, 2016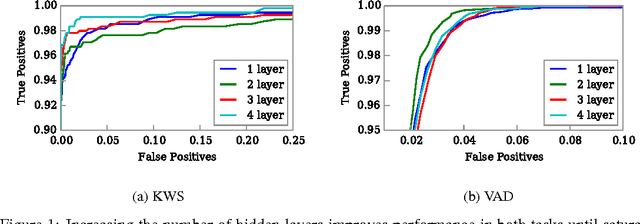
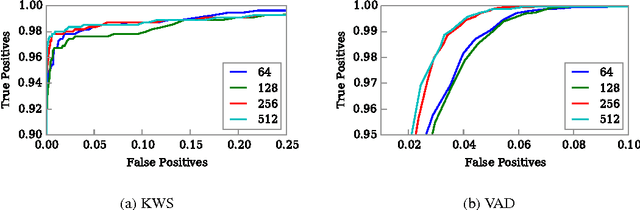
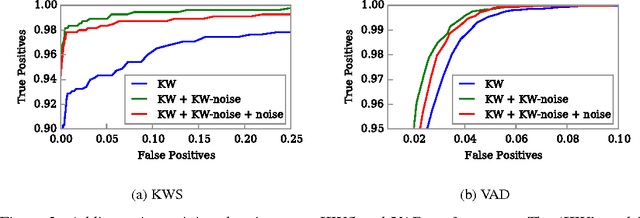
We propose a single neural network architecture for two tasks: on-line keyword spotting and voice activity detection. We develop novel inference algorithms for an end-to-end Recurrent Neural Network trained with the Connectionist Temporal Classification loss function which allow our model to achieve high accuracy on both keyword spotting and voice activity detection without retraining. In contrast to prior voice activity detection models, our architecture does not require aligned training data and uses the same parameters as the keyword spotting model. This allows us to deploy a high quality voice activity detector with no additional memory or maintenance requirements.
Learning Multiscale Features Directly From Waveforms
Apr 05, 2016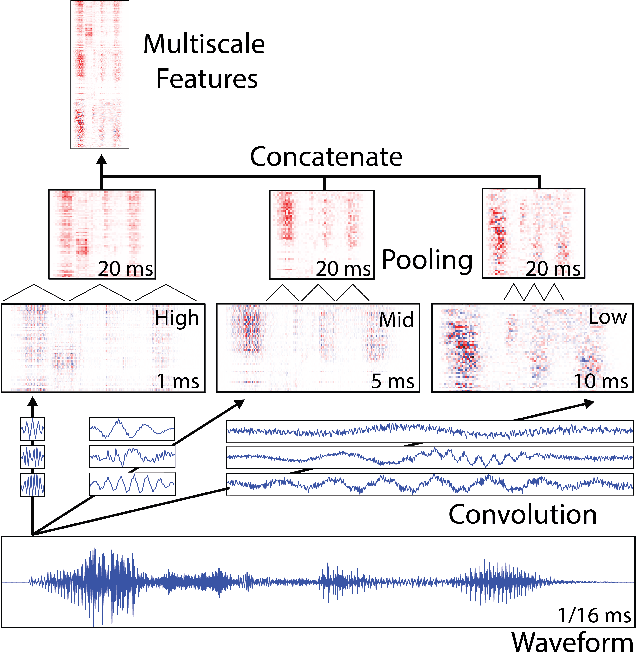

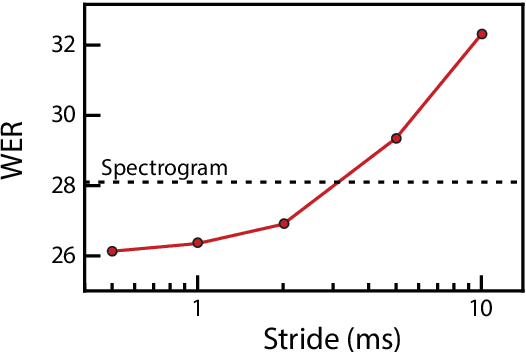
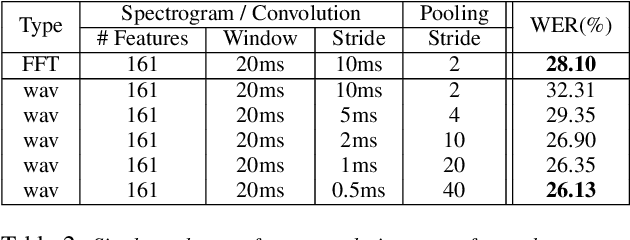
Deep learning has dramatically improved the performance of speech recognition systems through learning hierarchies of features optimized for the task at hand. However, true end-to-end learning, where features are learned directly from waveforms, has only recently reached the performance of hand-tailored representations based on the Fourier transform. In this paper, we detail an approach to use convolutional filters to push past the inherent tradeoff of temporal and frequency resolution that exists for spectral representations. At increased computational cost, we show that increasing temporal resolution via reduced stride and increasing frequency resolution via additional filters delivers significant performance improvements. Further, we find more efficient representations by simultaneously learning at multiple scales, leading to an overall decrease in word error rate on a difficult internal speech test set by 20.7% relative to networks with the same number of parameters trained on spectrograms.