 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexCloth: Extracting Template-free Textured 3D Clothes from a Monocular Image
Aug 27, 2022

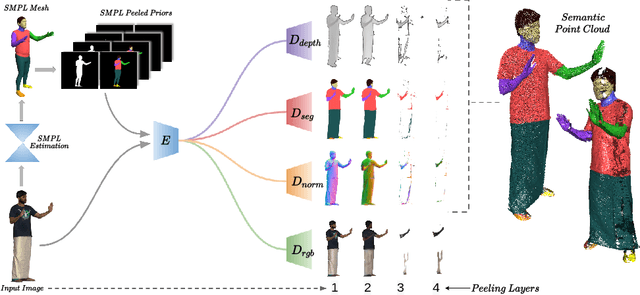
Existing approaches for 3D garment reconstruction either assume a predefined template for the garment geometry (restricting them to fixed clothing styles) or yield vertex colored meshes (lacking high-frequency textural details). Our novel framework co-learns geometric and semantic information of garment surface from the input monocular image for template-free textured 3D garment digitization. More specifically, we propose to extend PeeledHuman representation to predict the pixel-aligned, layered depth and semantic maps to extract 3D garments. The layered representation is further exploited to UV parametrize the arbitrary surface of the extracted garment without any human intervention to form a UV atlas. The texture is then imparted on the UV atlas in a hybrid fashion by first projecting pixels from the input image to UV space for the visible region, followed by inpainting the occluded regions. Thus, we are able to digitize arbitrarily loose clothing styles while retaining high-frequency textural details from a monocular image. We achieve high-fidelity 3D garment reconstruction results on three publicly available datasets and generalization on internet images.
N2NSkip: Learning Highly Sparse Networks using Neuron-to-Neuron Skip Connections
Aug 07, 2022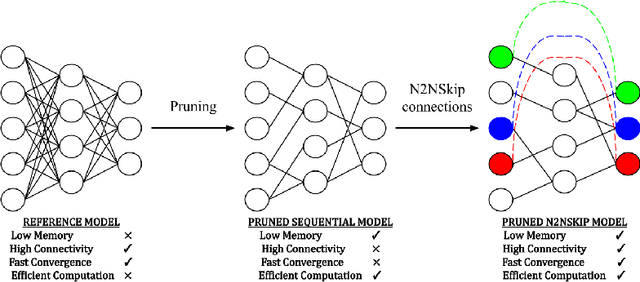
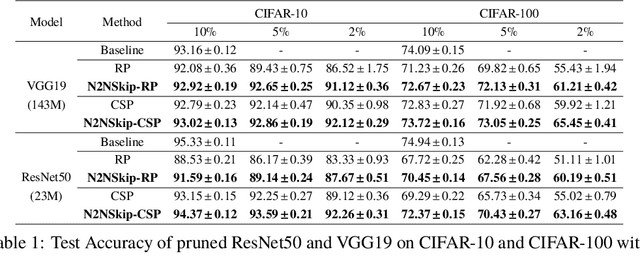
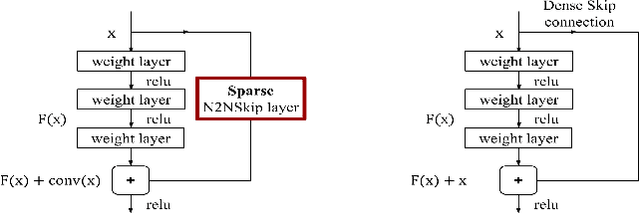

The over-parametrized nature of Deep Neural Networks leads to considerable hindrances during deployment on low-end devices with time and space constraints. Network pruning strategies that sparsify DNNs using iterative prune-train schemes are often computationally expensive. As a result, techniques that prune at initialization, prior to training, have become increasingly popular. In this work, we propose neuron-to-neuron skip connections, which act as sparse weighted skip connections, to enhance the overall connectivity of pruned DNNs. Following a preliminary pruning step, N2NSkip connections are randomly added between individual neurons/channels of the pruned network, while maintaining the overall sparsity of the network. We demonstrate that introducing N2NSkip connections in pruned networks enables significantly superior performance, especially at high sparsity levels, as compared to pruned networks without N2NSkip connections. Additionally, we present a heat diffusion-based connectivity analysis to quantitatively determine the connectivity of the pruned network with respect to the reference network. We evaluate the efficacy of our approach on two different preliminary pruning methods which prune at initialization, and consistently obtain superior performance by exploiting the enhanced connectivity resulting from N2NSkip connections.
SHARP: Shape-Aware Reconstruction of People in Loose Clothing
May 24, 2022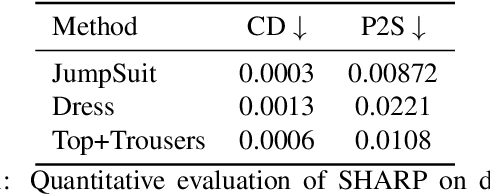
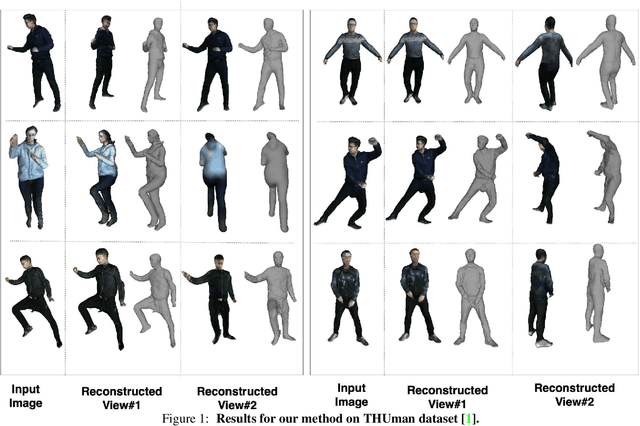
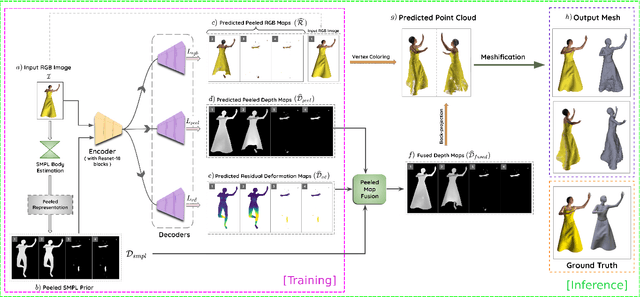
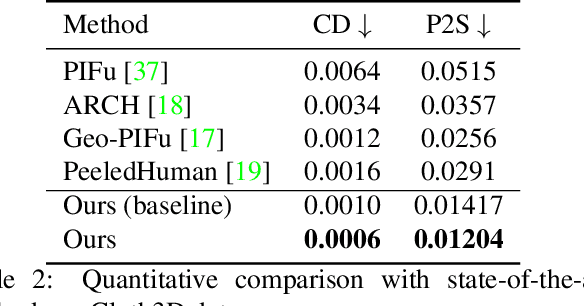
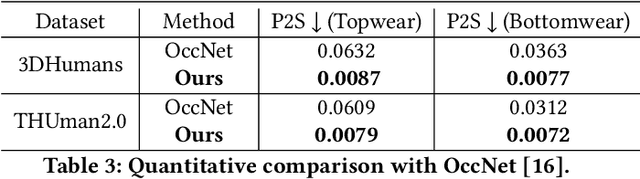
Recent advancements in deep learning have enabled 3D human body reconstruction from a monocular image, which has broad applications in multiple domains. In this paper, we propose SHARP (SHape Aware Reconstruction of People in loose clothing), a novel end-to-end trainable network that accurately recovers the 3D geometry and appearance of humans in loose clothing from a monocular image. SHARP uses a sparse and efficient fusion strategy to combine parametric body prior with a non-parametric 2D representation of clothed humans. The parametric body prior enforces geometrical consistency on the body shape and pose, while the non-parametric representation models loose clothing and handle self-occlusions as well. We also leverage the sparseness of the non-parametric representation for faster training of our network while using losses on 2D maps. Another key contribution is 3DHumans, our new life-like dataset of 3D human body scans with rich geometrical and textural details. We evaluate SHARP on 3DHumans and other publicly available datasets and show superior qualitative and quantitative performance than existing state-of-the-art methods.
Deep Generative Framework for Interactive 3D Terrain Authoring and Manipulation
Jan 07, 2022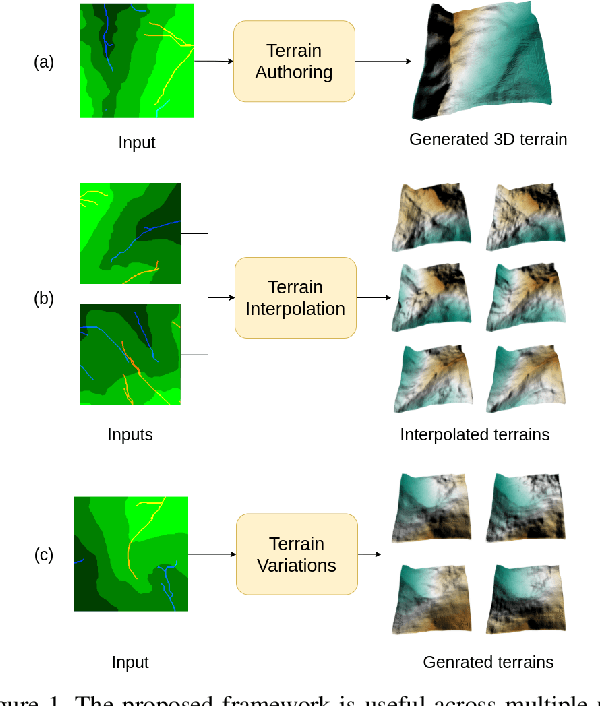
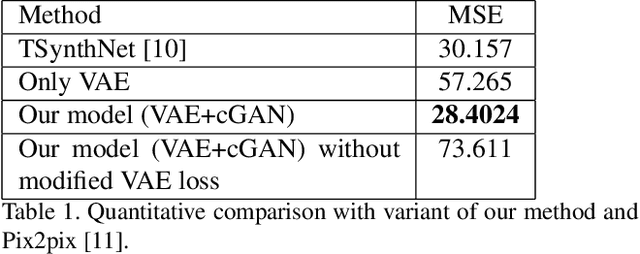
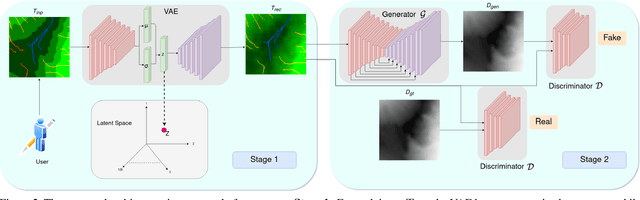
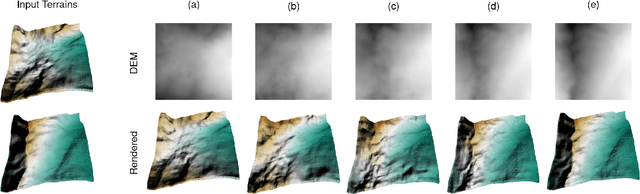
Automated generation and (user) authoring of the realistic virtual terrain is most sought for by the multimedia applications like VR models and gaming. The most common representation adopted for terrain is Digital Elevation Model (DEM). Existing terrain authoring and modeling techniques have addressed some of these and can be broadly categorized as: procedural modeling, simulation method, and example-based methods. In this paper, we propose a novel realistic terrain authoring framework powered by a combination of VAE and generative conditional GAN model. Our framework is an example-based method that attempts to overcome the limitations of existing methods by learning a latent space from a real-world terrain dataset. This latent space allows us to generate multiple variants of terrain from a single input as well as interpolate between terrains while keeping the generated terrains close to real-world data distribution. We also developed an interactive tool, that lets the user generate diverse terrains with minimalist inputs. We perform thorough qualitative and quantitative analysis and provide comparisons with other SOTA methods. We intend to release our code/tool to the academic community.
Attention based Occlusion Removal for Hybrid Telepresence Systems
Dec 02, 2021
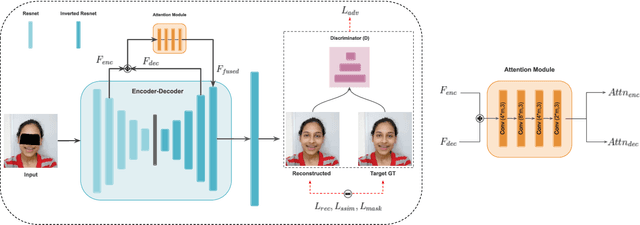


Traditionally, video conferencing is a widely adopted solution for telecommunication, but a lack of immersiveness comes inherently due to the 2D nature of facial representation. The integration of Virtual Reality (VR) in a communication/telepresence system through Head Mounted Displays (HMDs) promises to provide users a much better immersive experience. However, HMDs cause hindrance by blocking the facial appearance and expressions of the user. To overcome these issues, we propose a novel attention-enabled encoder-decoder architecture for HMD de-occlusion. We also propose to train our person-specific model using short videos (1-2 minutes) of the user, captured in varying appearances, and demonstrated generalization to unseen poses and appearances of the user. We report superior qualitative and quantitative results over state-of-the-art methods. We also present applications of this approach to hybrid video teleconferencing using existing animation and 3D face reconstruction pipelines.
Robust 3D Garment Digitization from Monocular 2D Images for 3D Virtual Try-On Systems
Nov 30, 2021
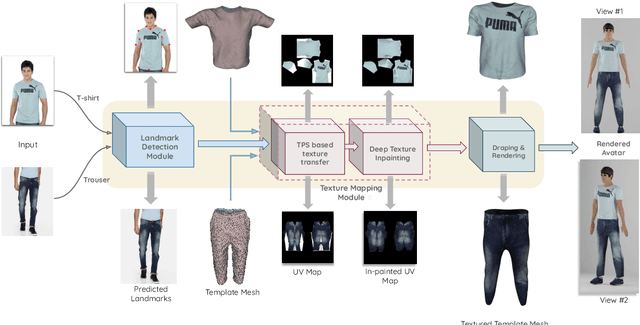
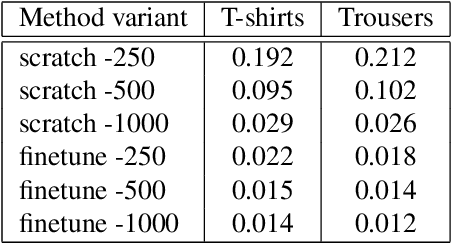
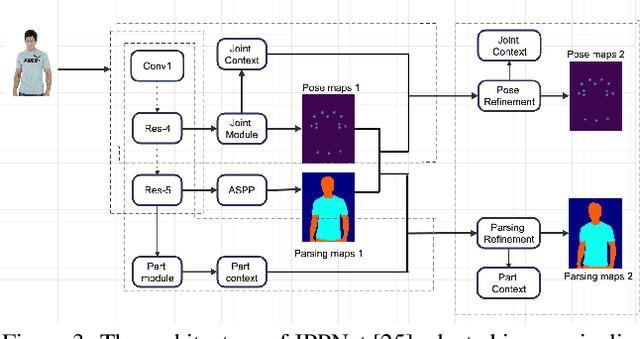
In this paper, we develop a robust 3D garment digitization solution that can generalize well on real-world fashion catalog images with cloth texture occlusions and large body pose variations. We assumed fixed topology parametric template mesh models for known types of garments (e.g., T-shirts, Trousers) and perform mapping of high-quality texture from an input catalog image to UV map panels corresponding to the parametric mesh model of the garment. We achieve this by first predicting a sparse set of 2D landmarks on the boundary of the garments. Subsequently, we use these landmarks to perform Thin-Plate-Spline-based texture transfer on UV map panels. Subsequently, we employ a deep texture inpainting network to fill the large holes (due to view variations & self-occlusions) in TPS output to generate consistent UV maps. Furthermore, to train the supervised deep networks for landmark prediction & texture inpainting tasks, we generated a large set of synthetic data with varying texture and lighting imaged from various views with the human present in a wide variety of poses. Additionally, we manually annotated a small set of fashion catalog images crawled from online fashion e-commerce platforms to finetune. We conduct thorough empirical evaluations and show impressive qualitative results of our proposed 3D garment texture solution on fashion catalog images. Such 3D garment digitization helps us solve the challenging task of enabling 3D Virtual Try-on.
3D Shape Registration Using Spectral Graph Embedding and Probabilistic Matching
Jun 21, 2021

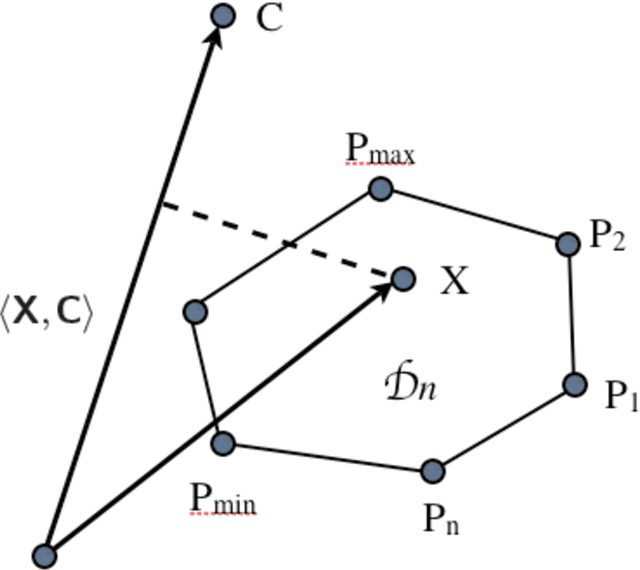
We address the problem of 3D shape registration and we propose a novel technique based on spectral graph theory and probabilistic matching. The task of 3D shape analysis involves tracking, recognition, registration, etc. Analyzing 3D data in a single framework is still a challenging task considering the large variability of the data gathered with different acquisition devices. 3D shape registration is one such challenging shape analysis task. The main contribution of this chapter is to extend the spectral graph matching methods to very large graphs by combining spectral graph matching with Laplacian embedding. Since the embedded representation of a graph is obtained by dimensionality reduction we claim that the existing spectral-based methods are not easily applicable. We discuss solutions for the exact and inexact graph isomorphism problems and recall the main spectral properties of the combinatorial graph Laplacian; We provide a novel analysis of the commute-time embedding that allows us to interpret the latter in terms of the PCA of a graph, and to select the appropriate dimension of the associated embedded metric space; We derive a unit hyper-sphere normalization for the commute-time embedding that allows us to register two shapes with different samplings; We propose a novel method to find the eigenvalue-eigenvector ordering and the eigenvector signs using the eigensignature (histogram) which is invariant to the isometric shape deformations and fits well in the spectral graph matching framework, and we present a probabilistic shape matching formulation using an expectation maximization point registration algorithm which alternates between aligning the eigenbases and finding a vertex-to-vertex assignment.
SHARP: Shape-Aware Reconstruction of People In Loose Clothing
Jun 17, 20213D human body reconstruction from monocular images is an interesting and ill-posed problem in computer vision with wider applications in multiple domains. In this paper, we propose SHARP, a novel end-to-end trainable network that accurately recovers the detailed geometry and appearance of 3D people in loose clothing from a monocular image. We propose a sparse and efficient fusion of a parametric body prior with a non-parametric peeled depth map representation of clothed models. The parametric body prior constraints our model in two ways: first, the network retains geometrically consistent body parts that are not occluded by clothing, and second, it provides a body shape context that improves prediction of the peeled depth maps. This enables SHARP to recover fine-grained 3D geometrical details with just L1 losses on the 2D maps, given an input image. We evaluate SHARP on publicly available Cloth3D and THuman datasets and report superior performance to state-of-the-art approaches.
GlocalNet: Class-aware Long-term Human Motion Synthesis
Dec 19, 2020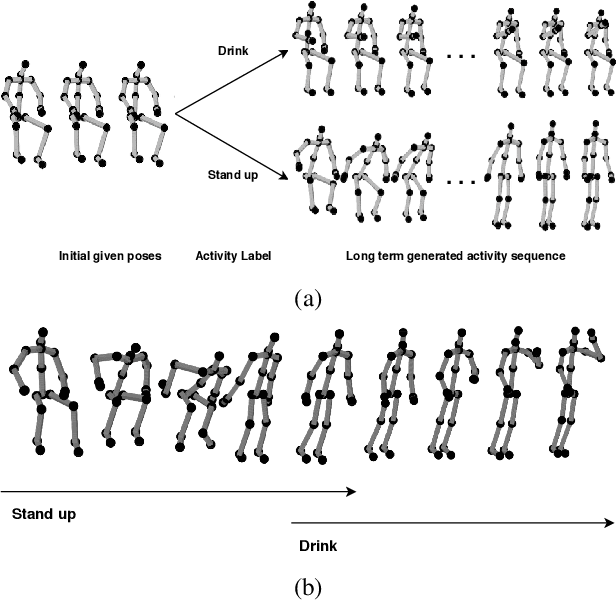
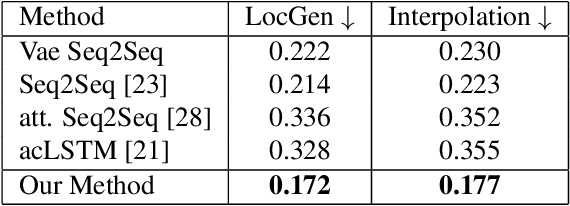
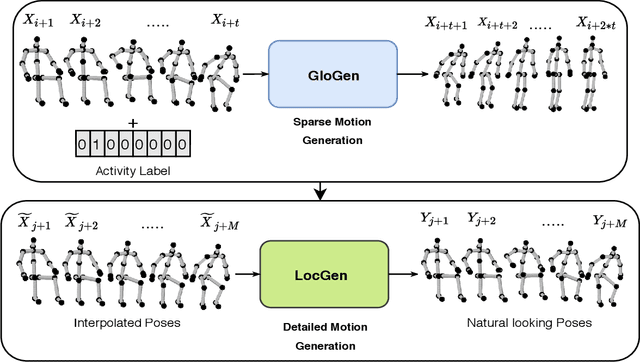
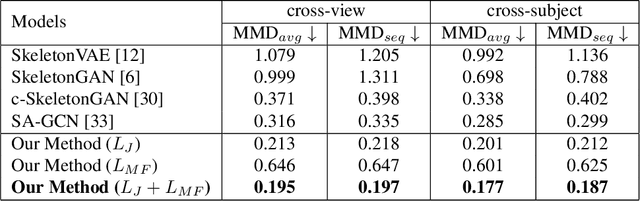
Synthesis of long-term human motion skeleton sequences is essential to aid human-centric video generation with potential applications in Augmented Reality, 3D character animations, pedestrian trajectory prediction, etc. Long-term human motion synthesis is a challenging task due to multiple factors like, long-term temporal dependencies among poses, cyclic repetition across poses, bi-directional and multi-scale dependencies among poses, variable speed of actions, and a large as well as partially overlapping space of temporal pose variations across multiple class/types of human activities. This paper aims to address these challenges to synthesize a long-term (> 6000 ms) human motion trajectory across a large variety of human activity classes (>50). We propose a two-stage activity generation method to achieve this goal, where the first stage deals with learning the long-term global pose dependencies in activity sequences by learning to synthesize a sparse motion trajectory while the second stage addresses the generation of dense motion trajectories taking the output of the first stage. We demonstrate the superiority of the proposed method over SOTA methods using various quantitative evaluation metrics on publicly available datasets.
* Appearing in 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)
AFN: Attentional Feedback Network based 3D Terrain Super-Resolution
Oct 04, 2020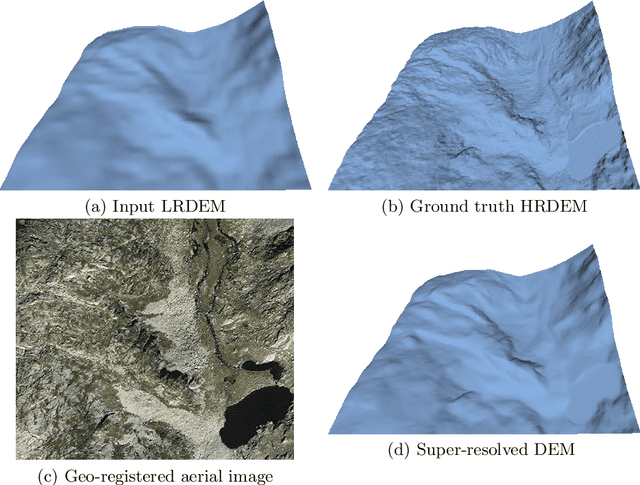
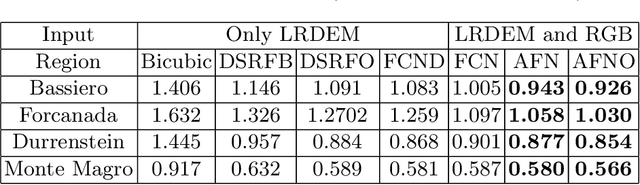
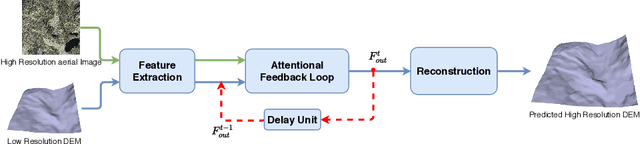
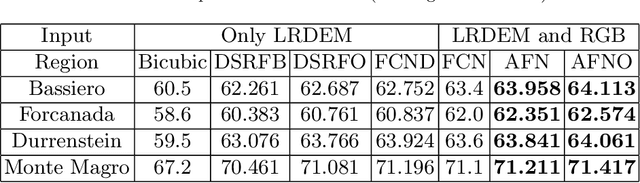
Terrain, representing features of an earth surface, plays a crucial role in many applications such as simulations, route planning, analysis of surface dynamics, computer graphics-based games, entertainment, films, to name a few. With recent advancements in digital technology, these applications demand the presence of high-resolution details in the terrain. In this paper, we propose a novel fully convolutional neural network-based super-resolution architecture to increase the resolution of low-resolution Digital Elevation Model (LRDEM) with the help of information extracted from the corresponding aerial image as a complementary modality. We perform the super-resolution of LRDEM using an attention-based feedback mechanism named 'Attentional Feedback Network' (AFN), which selectively fuses the information from LRDEM and aerial image to enhance and infuse the high-frequency features and to produce the terrain realistically. We compare the proposed architecture with existing state-of-the-art DEM super-resolution methods and show that the proposed architecture outperforms enhancing the resolution of input LRDEM accurately and in a realistic manner.