 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Bayesian and Frequentist Inference for Laboratory-Specific Performance Guarantees in Copy Number Variation Detection
Apr 15, 2026Targeted amplicon panels are widely used in oncology diagnostics, but providing per-gene performance guarantees for copy number variant (CNV) detection remains challenging due to amplification artifacts, process-mismatch heterogeneity, and limited validation sample sizes. While Bayesian CNV callers naturally quantify per-sample uncertainty, translating this into the frequentist population-level guarantees required for clinical validation, coverage rates, false-positive bounds, and minimum detectable copy-number changes, is a fundamentally different inferential problem. We show empirically that even robust Bayesian credible intervals, including coarsened posteriors and sandwich-adjusted intervals, are severely miscalibrated on panels with small amplicon counts per gene. To address this, we propose a hybrid framework that evaluates Bayesian posterior functionals on validation samples and models the resulting squared losses with a Gamma distribution, yielding tolerance intervals with valid frequentist coverage. Three components make the method practical under real-world constraints: (1) imputation that removes the influence of true CNV-positive samples without requiring known ground truth, (2) regularization to address small sample variability, and (3) evidence-based stratification on the log model evidence to accommodate non-exchangeable noise profiles arising from process mismatch. Evaluated on two targeted amplicon panels using leave-one-out cross-validation, the proposed method achieves single-digit mean absolute coverage error across all genes under both process-matched and unmatched conditions, whereas Bayesian comparators exhibit mean absolute errors exceeding 60\% on clinically relevant genes such as ERBB2.
Detecting Batch Heterogeneity via Likelihood Clustering
Jan 14, 2026Batch effects represent a major confounder in genomic diagnostics. In copy number variant (CNV) detection from NGS, many algorithms compare read depth between test samples and a reference sample, assuming they are process-matched. When this assumption is violated, with causes ranging from reagent lot changes to multi-site processing, the reference becomes inappropriate, introducing false CNV calls or masking true pathogenic variants. Detecting such heterogeneity before downstream analysis is critical for reliable clinical interpretation. Existing batch effect detection methods either cluster samples based on raw features, risking conflation of biological signal with technical variation, or require known batch labels that are frequently unavailable. We introduce a method that addresses both limitations by clustering samples according to their Bayesian model evidence. The central insight is that evidence quantifies compatibility between data and model assumptions, technical artifacts violate assumptions and reduce evidence, whereas biological variation, including CNV status, is anticipated by the model and yields high evidence. This asymmetry provides a discriminative signal that separates batch effects from biology. We formalize heterogeneity detection as a likelihood ratio test for mixture structure in evidence space, using parametric bootstrap calibration to ensure conservative false positive rates. We validate our approach on synthetic data demonstrating proper Type I error control, three clinical targeted sequencing panels (liquid biopsy, BRCA, and thalassemia) exhibiting distinct batch effect mechanisms, and mouse electrophysiology recordings demonstrating cross-modality generalization. Our method achieves superior clustering accuracy compared to standard correlation-based and dimensionality-reduction approaches while maintaining the conservativeness required for clinical usage.
Generative Principal Component Regression via Variational Inference
Sep 03, 2024



The ability to manipulate complex systems, such as the brain, to modify specific outcomes has far-reaching implications, particularly in the treatment of psychiatric disorders. One approach to designing appropriate manipulations is to target key features of predictive models. While generative latent variable models, such as probabilistic principal component analysis (PPCA), is a powerful tool for identifying targets, they struggle incorporating information relevant to low-variance outcomes into the latent space. When stimulation targets are designed on the latent space in such a scenario, the intervention can be suboptimal with minimal efficacy. To address this problem, we develop a novel objective based on supervised variational autoencoders (SVAEs) that enforces such information is represented in the latent space. The novel objective can be used with linear models, such as PPCA, which we refer to as generative principal component regression (gPCR). We show in simulations that gPCR dramatically improves target selection in manipulation as compared to standard PCR and SVAEs. As part of these simulations, we develop a metric for detecting when relevant information is not properly incorporated into the loadings. We then show in two neural datasets related to stress and social behavior in which gPCR dramatically outperforms PCR in predictive performance and that SVAEs exhibit low incorporation of relevant information into the loadings. Overall, this work suggests that our method significantly improves target selection for manipulation using latent variable models over competitor inference schemes.
AugmentedPCA: A Python Package of Supervised and Adversarial Linear Factor Models
Jan 07, 2022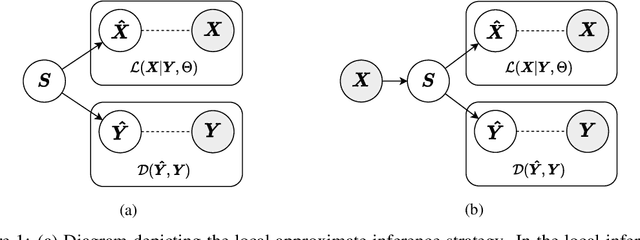


Deep autoencoders are often extended with a supervised or adversarial loss to learn latent representations with desirable properties, such as greater predictivity of labels and outcomes or fairness with respects to a sensitive variable. Despite the ubiquity of supervised and adversarial deep latent factor models, these methods should demonstrate improvement over simpler linear approaches to be preferred in practice. This necessitates a reproducible linear analog that still adheres to an augmenting supervised or adversarial objective. We address this methodological gap by presenting methods that augment the principal component analysis (PCA) objective with either a supervised or an adversarial objective and provide analytic and reproducible solutions. We implement these methods in an open-source Python package, AugmentedPCA, that can produce excellent real-world baselines. We demonstrate the utility of these factor models on an open-source, RNA-seq cancer gene expression dataset, showing that augmenting with a supervised objective results in improved downstream classification performance, produces principal components with greater class fidelity, and facilitates identification of genes aligned with the principal axes of data variance with implications to development of specific types of cancer.
Supervising the Decoder of Variational Autoencoders to Improve Scientific Utility
Sep 09, 2021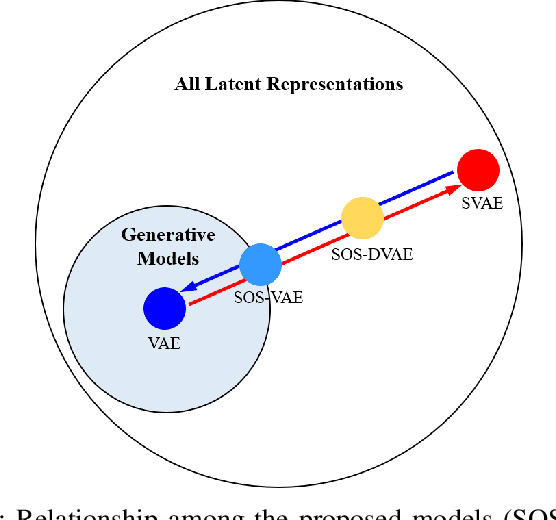
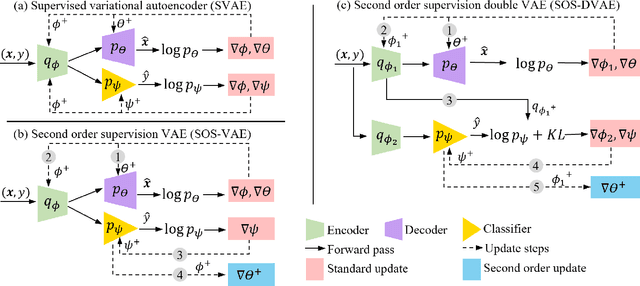
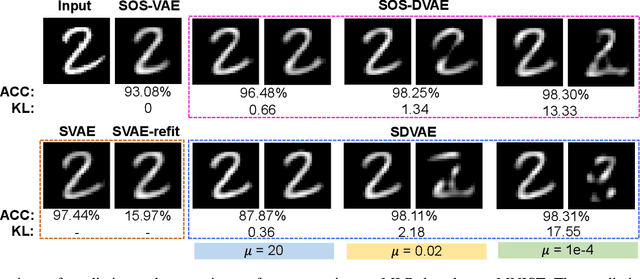
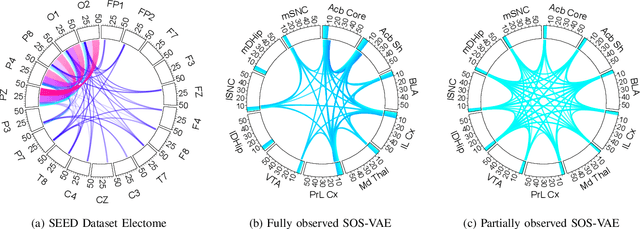
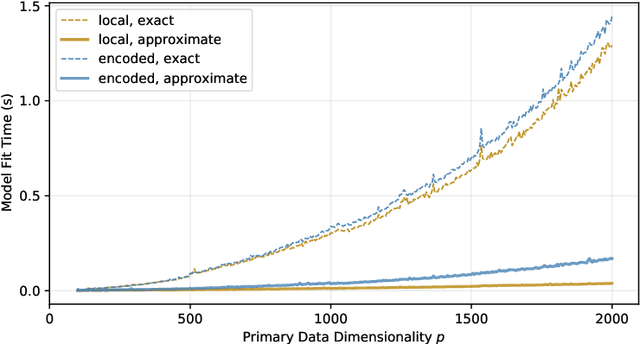
Probabilistic generative models are attractive for scientific modeling because their inferred parameters can be used to generate hypotheses and design experiments. This requires that the learned model provide an accurate representation of the input data and yield a latent space that effectively predicts outcomes relevant to the scientific question. Supervised Variational Autoencoders (SVAEs) have previously been used for this purpose, where a carefully designed decoder can be used as an interpretable generative model while the supervised objective ensures a predictive latent representation. Unfortunately, the supervised objective forces the encoder to learn a biased approximation to the generative posterior distribution, which renders the generative parameters unreliable when used in scientific models. This issue has remained undetected as reconstruction losses commonly used to evaluate model performance do not detect bias in the encoder. We address this previously-unreported issue by developing a second order supervision framework (SOS-VAE) that influences the decoder to induce a predictive latent representation. This ensures that the associated encoder maintains a reliable generative interpretation. We extend this technique to allow the user to trade-off some bias in the generative parameters for improved predictive performance, acting as an intermediate option between SVAEs and our new SOS-VAE. We also use this methodology to address missing data issues that often arise when combining recordings from multiple scientific experiments. We demonstrate the effectiveness of these developments using synthetic data and electrophysiological recordings with an emphasis on how our learned representations can be used to design scientific experiments.
Supervised Autoencoders Learn Robust Joint Factor Models of Neural Activity
Apr 10, 2020

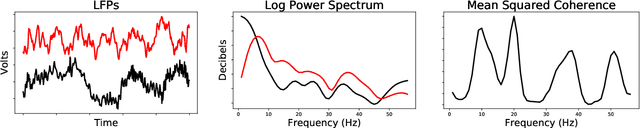
Factor models are routinely used for dimensionality reduction in modeling of correlated, high-dimensional data. We are particularly motivated by neuroscience applications collecting high-dimensional `predictors' corresponding to brain activity in different regions along with behavioral outcomes. Joint factor models for the predictors and outcomes are natural, but maximum likelihood estimates of these models can struggle in practice when there is model misspecification. We propose an alternative inference strategy based on supervised autoencoders; rather than placing a probability distribution on the latent factors, we define them as an unknown function of the high-dimensional predictors. This mapping function, along with the loadings, can be optimized to explain variance in brain activity while simultaneously being predictive of behavior. In practice, the mapping function can range in complexity from linear to more complex forms, such as splines or neural networks, with the usual tradeoff between bias and variance. This approach yields distinct solutions from a maximum likelihood inference strategy, as we demonstrate by deriving analytic solutions for a linear Gaussian factor model. Using synthetic data, we show that this function-based approach is robust against multiple types of misspecification. We then apply this technique to a neuroscience application resulting in substantial gains in predicting behavioral tasks from electrophysiological measurements in multiple factor models.