 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevolutionizing Long-Term Memory in AI: New Horizons with High-Capacity and High-Speed Storage
Feb 18, 2026Driven by our mission of "uplifting the world with memory," this paper explores the design concept of "memory" that is essential for achieving artificial superintelligence (ASI). Rather than proposing novel methods, we focus on several alternative approaches whose potential benefits are widely imaginable, yet have remained largely unexplored. The currently dominant paradigm, which can be termed "extract then store," involves extracting information judged to be useful from experiences and saving only the extracted content. However, this approach inherently risks the loss of information, as some valuable knowledge particularly for different tasks may be discarded in the extraction process. In contrast, we emphasize the "store then on-demand extract" approach, which seeks to retain raw experiences and flexibly apply them to various tasks as needed, thus avoiding such information loss. In addition, we highlight two further approaches: discovering deeper insights from large collections of probabilistic experiences, and improving experience collection efficiency by sharing stored experiences. While these approaches seem intuitively effective, our simple experiments demonstrate that this is indeed the case. Finally, we discuss major challenges that have limited investigation into these promising directions and propose research topics to address them.
Revisiting a kNN-based Image Classification System with High-capacity Storage
Apr 03, 2022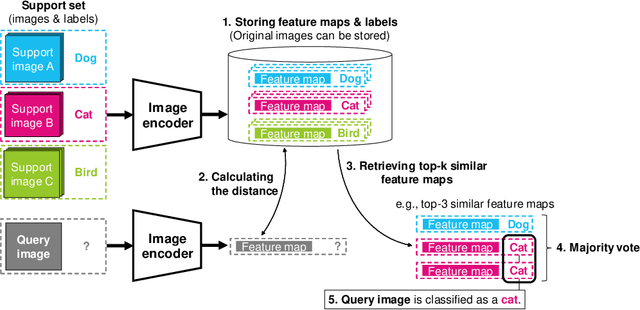


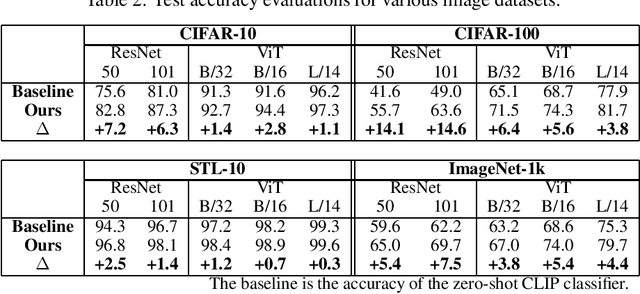
In existing image classification systems that use deep neural networks, the knowledge needed for image classification is implicitly stored in model parameters. If users want to update this knowledge, then they need to fine-tune the model parameters. Moreover, users cannot verify the validity of inference results or evaluate the contribution of knowledge to the results. In this paper, we investigate a system that stores knowledge for image classification, such as image feature maps, labels, and original images, not in model parameters but in external high-capacity storage. Our system refers to the storage like a database when classifying input images. To increase knowledge, our system updates the database instead of fine-tuning model parameters, which avoids catastrophic forgetting in incremental learning scenarios. We revisit a kNN (k-Nearest Neighbor) classifier and employ it in our system. By analyzing the neighborhood samples referred by the kNN algorithm, we can interpret how knowledge learned in the past is used for inference results. Our system achieves 79.8% top-1 accuracy on the ImageNet dataset without fine-tuning model parameters after pretraining, and 90.8% accuracy on the Split CIFAR-100 dataset in the task incremental learning setting.