Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hardware Realization of Convolutional Neural Networks using Intra-Kernel Regular Pruning
Mar 15, 2018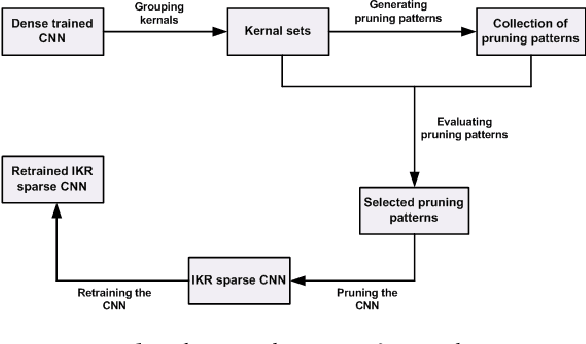
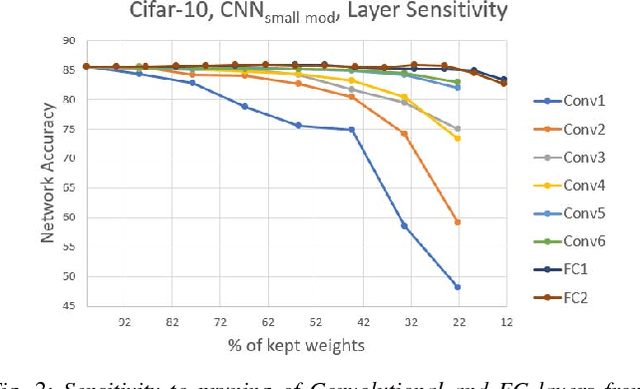
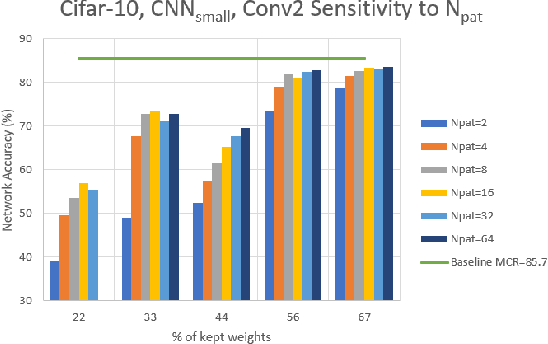
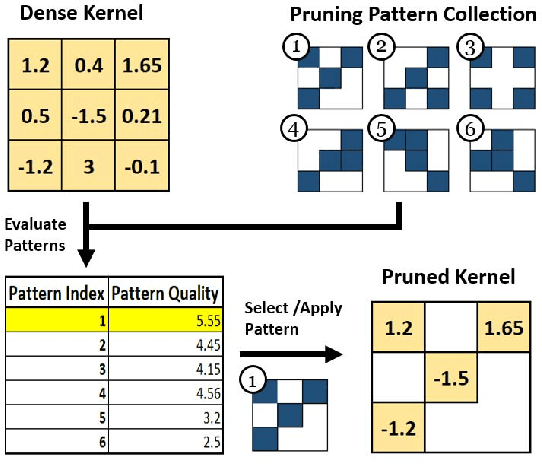
The recent trend toward increasingly deep convolutional neural networks (CNNs) leads to a higher demand of computational power and memory storage. Consequently, the deployment of CNNs in hardware has become more challenging. In this paper, we propose an Intra-Kernel Regular (IKR) pruning scheme to reduce the size and computational complexity of the CNNs by removing redundant weights at a fine-grained level. Unlike other pruning methods such as Fine-Grained pruning, IKR pruning maintains regular kernel structures that are exploitable in a hardware accelerator. Experimental results demonstrate up to 10x parameter reduction and 7x computational reduction at a cost of less than 1% degradation in accuracy versus the un-pruned case.
* 6 pages, 8 figures, ISMVL 2018
Via