 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR as an Evaluation Playground: Bridging Metrics and Visual Perception of Computer Vision Models
Aug 06, 2025Human perception studies can provide complementary insights to qualitative evaluation for understanding computer vision (CV) model performance. However, conducting human perception studies remains a non-trivial task, it often requires complex, end-to-end system setups that are time-consuming and difficult to scale. In this paper, we explore the unique opportunity presented by augmented reality (AR) for helping CV researchers to conduct perceptual studies. We design ARCADE, an evaluation platform that allows researchers to easily leverage AR's rich context and interactivity for human-centered CV evaluation. Specifically, ARCADE supports cross-platform AR data collection, custom experiment protocols via pluggable model inference, and AR streaming for user studies. We demonstrate ARCADE using two types of CV models, depth and lighting estimation and show that AR tasks can be effectively used to elicit human perceptual judgments of model quality. We also evaluate the systems usability and performance across different deployment and study settings, highlighting its flexibility and effectiveness as a human-centered evaluation platform.
HybridDepth: Robust Depth Fusion for Mobile AR by Leveraging Depth from Focus and Single-Image Priors
Jul 26, 2024



We propose HYBRIDDEPTH, a robust depth estimation pipeline that addresses the unique challenges of depth estimation for mobile AR, such as scale ambiguity, hardware heterogeneity, and generalizability. HYBRIDDEPTH leverages the camera features available on mobile devices. It effectively combines the scale accuracy inherent in Depth from Focus (DFF) methods with the generalization capabilities enabled by strong single-image depth priors. By utilizing the focal planes of a mobile camera, our approach accurately captures depth values from focused pixels and applies these values to compute scale and shift parameters for transforming relative depths into metric depths. We test our pipeline as an end-to-end system, with a newly developed mobile client to capture focal stacks, which are then sent to a GPU-powered server for depth estimation. Through comprehensive quantitative and qualitative analyses, we demonstrate that HYBRIDDEPTH not only outperforms state-of-the-art (SOTA) models in common datasets (DDFF12, NYU Depth v2) and a real-world AR dataset ARKitScenes but also demonstrates strong zero-shot generalization. For example, HYBRIDDEPTH trained on NYU Depth v2 achieves comparable performance on the DDFF12 to existing models trained on DDFF12. it also outperforms all the SOTA models in zero-shot performance on the ARKitScenes dataset. Additionally, we conduct a qualitative comparison between our model and the ARCore framework, demonstrating that our models output depth maps are significantly more accurate in terms of structural details and metric accuracy. The source code of this project is available at github.
Mobile AR Depth Estimation: Challenges & Prospects -- Extended Version
Oct 22, 2023



Metric depth estimation plays an important role in mobile augmented reality (AR). With accurate metric depth, we can achieve more realistic user interactions such as object placement and occlusion detection. While specialized hardware like LiDAR demonstrates its promise, its restricted availability, i.e., only on selected high-end mobile devices, and performance limitations such as range and sensitivity to the environment, make it less ideal. Monocular depth estimation, on the other hand, relies solely on mobile cameras, which are ubiquitous, making it a promising alternative for mobile AR. In this paper, we investigate the challenges and opportunities of achieving accurate metric depth estimation in mobile AR. We tested four different state-of-the-art monocular depth estimation models on a newly introduced dataset (ARKitScenes) and identified three types of challenges: hard-ware, data, and model related challenges. Furthermore, our research provides promising future directions to explore and solve those challenges. These directions include (i) using more hardware-related information from the mobile device's camera and other available sensors, (ii) capturing high-quality data to reflect real-world AR scenarios, and (iii) designing a model architecture to utilize the new information.
A Block-based Convolutional Neural Network for Low-Resolution Image Classification
Jul 19, 2022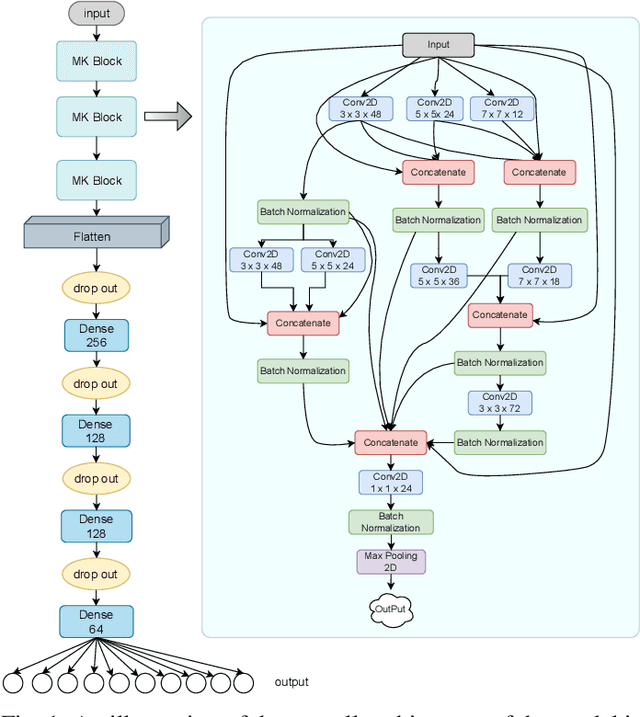
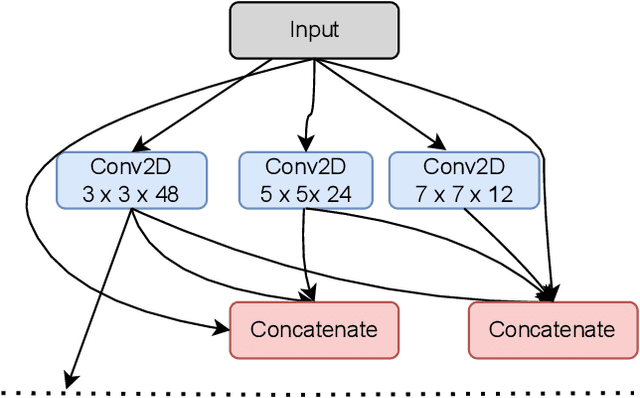
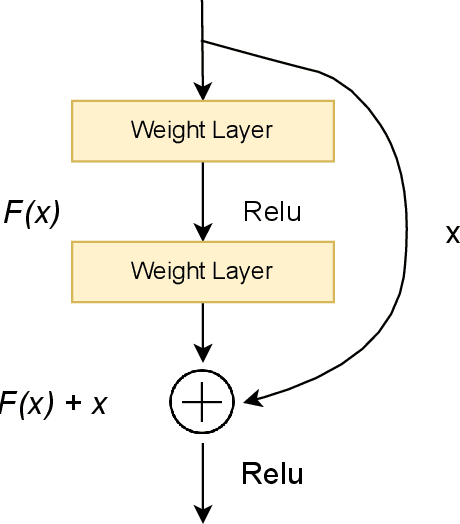
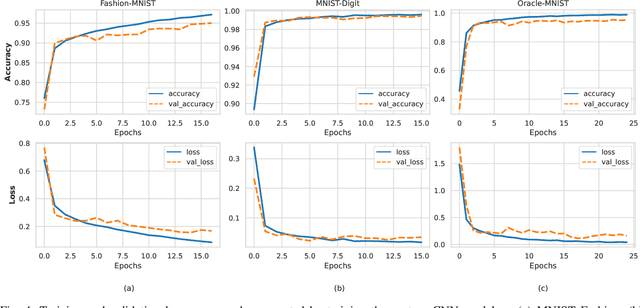
The success of CNN-based architecture on image classification in learning and extracting features made them so popular these days, but the task of image classification becomes more challenging when we use state of art models to classify noisy and low-quality images. To solve this problem, we proposed a novel image classification architecture that learns subtle details in low-resolution images that are blurred and noisy. In order to build our new blocks, we used the idea of Res Connections and the Inception module ideas. Using the MNIST datasets, we have conducted extensive experiments that show that the introduced architecture is more accurate and faster than other state-of-the-art Convolutional neural networks. As a result of the special characteristics of our model, it can achieve a better result with fewer parameters.