 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Image Differencing with ConvNets for Real-time Transient Hunting
Oct 04, 2017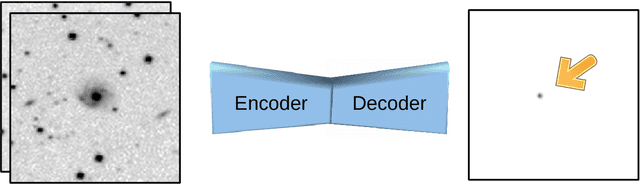

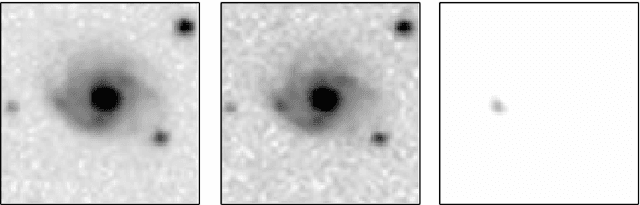
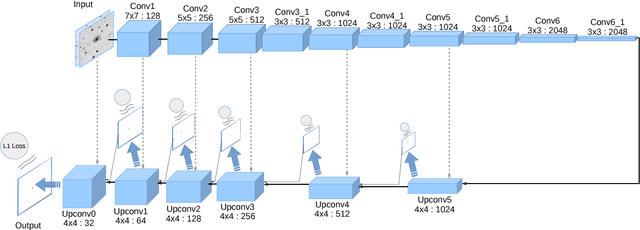
Large sky surveys are increasingly relying on image subtraction pipelines for real-time (and archival) transient detection. In this process one has to contend with varying PSF, small brightness variations in many sources, as well as artifacts resulting from saturated stars, and, in general, matching errors. Very often the differencing is done with a reference image that is deeper than individual images and the attendant difference in noise characteristics can also lead to artifacts. We present here a deep-learning approach to transient detection that encapsulates all the steps of a traditional image subtraction pipeline -- image registration, background subtraction, noise removal, psf matching, and subtraction -- into a single real-time convolutional network. Once trained the method works lighteningly fast, and given that it does multiple steps at one go, the advantages for multi-CCD, fast surveys like ZTF and LSST are obvious.
Deep-Learnt Classification of Light Curves
Sep 19, 2017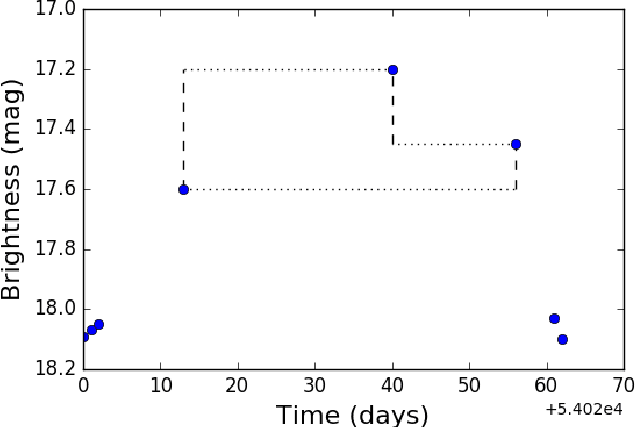
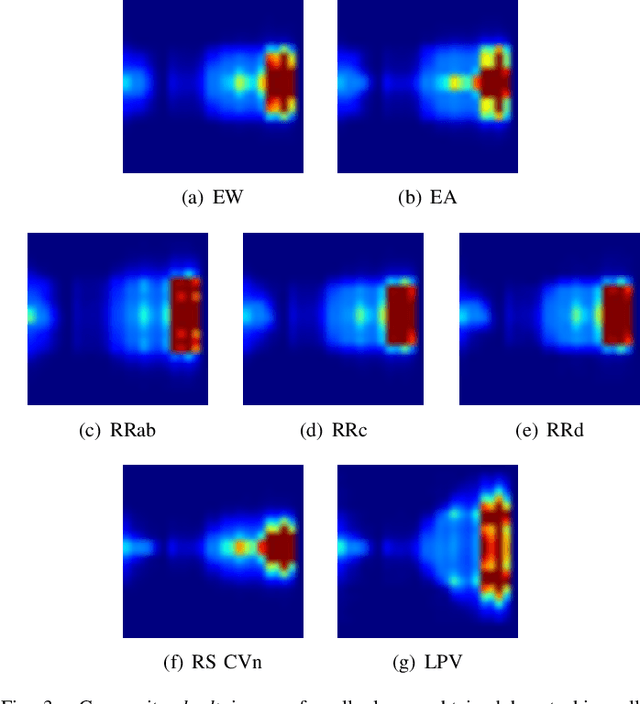
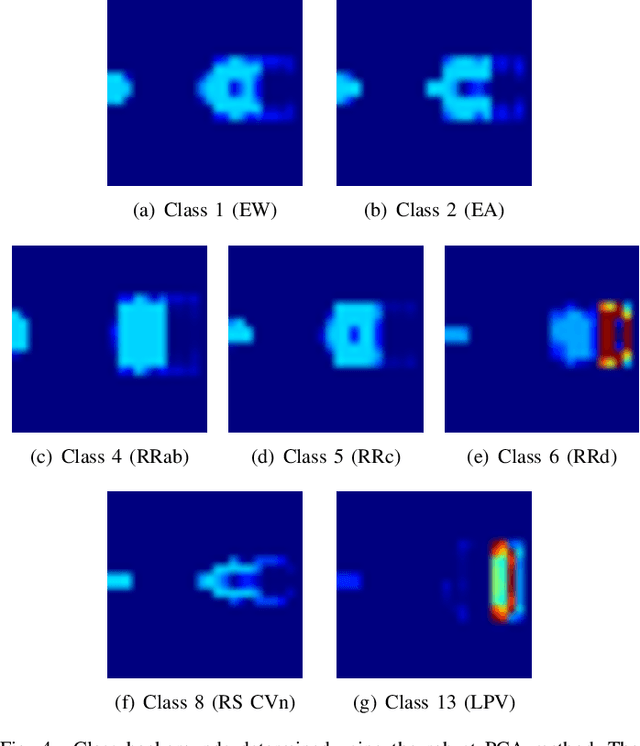
Astronomy light curves are sparse, gappy, and heteroscedastic. As a result standard time series methods regularly used for financial and similar datasets are of little help and astronomers are usually left to their own instruments and techniques to classify light curves. A common approach is to derive statistical features from the time series and to use machine learning methods, generally supervised, to separate objects into a few of the standard classes. In this work, we transform the time series to two-dimensional light curve representations in order to classify them using modern deep learning techniques. In particular, we show that convolutional neural networks based classifiers work well for broad characterization and classification. We use labeled datasets of periodic variables from CRTS survey and show how this opens doors for a quick classification of diverse classes with several possible exciting extensions.
* 8 pages, 9 figures, 6 tables, 2 listings. Accepted to 2017 IEEE Symposium Series on Computational Intelligence (SSCI)
Bigger Buffer k-d Trees on Multi-Many-Core Systems
Dec 09, 2015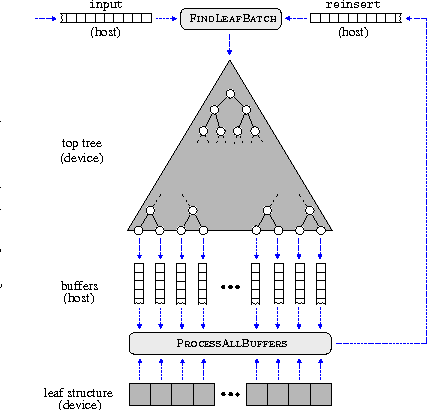
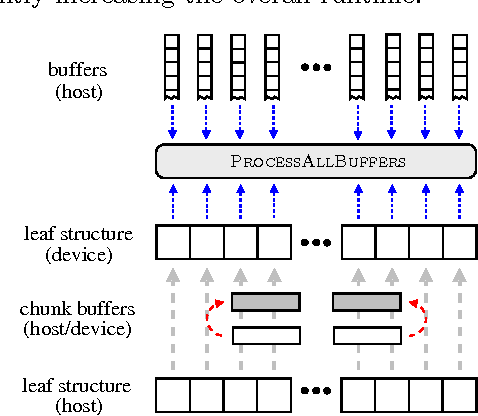
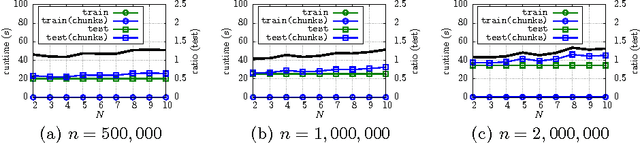

A buffer k-d tree is a k-d tree variant for massively-parallel nearest neighbor search. While providing valuable speed-ups on modern many-core devices in case both a large number of reference and query points are given, buffer k-d trees are limited by the amount of points that can fit on a single device. In this work, we show how to modify the original data structure and the associated workflow to make the overall approach capable of dealing with massive data sets. We further provide a simple yet efficient way of using multiple devices given in a single workstation. The applicability of the modified framework is demonstrated in the context of astronomy, a field that is faced with huge amounts of data.