 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor-Parallelism with Partially Synchronized Activations
Jun 24, 2025Training and inference of Large Language Models (LLMs) with tensor-parallelism requires substantial communication to synchronize activations. Our findings suggest that with a few minor adjustments to current practices, LLMs can be trained without fully synchronizing activations, reducing bandwidth demands. We name this "Communication-Aware Architecture for Tensor-parallelism" (CAAT-Net). We train 1B and 7B parameter CAAT-Net models, with a 50% reduction in tensor-parallel communication and no significant drop in pretraining accuracy. Furthermore, we demonstrate how CAAT-Net accelerates both training and inference workloads.
Dual Precision Quantization for Efficient and Accurate Deep Neural Networks Inference
May 20, 2025



Deep neural networks have achieved state-of-the-art results in a wide range of applications, from natural language processing and computer vision to speech recognition. However, as tasks become increasingly complex, model sizes continue to grow, posing challenges in latency and memory efficiency. To meet these constraints, post-training quantization has emerged as a promising solution. In this paper, we propose a novel hardware-efficient quantization and inference scheme that exploits hardware advantages with minimal accuracy degradation. Specifically, we introduce a W4A8 scheme, where weights are quantized and stored using 4-bit integer precision, and inference computations are performed using 8-bit floating-point arithmetic, demonstrating significant speedups and improved memory utilization compared to 16-bit operations, applicable on various modern accelerators. To mitigate accuracy loss, we develop a novel quantization algorithm, dubbed Dual Precision Quantization (DPQ), that leverages the unique structure of our scheme without introducing additional inference overhead. Experimental results demonstrate improved performance (i.e., increased throughput) while maintaining tolerable accuracy degradation relative to the full-precision model.
DropCompute: simple and more robust distributed synchronous training via compute variance reduction
Jun 18, 2023



Background: Distributed training is essential for large scale training of deep neural networks (DNNs). The dominant methods for large scale DNN training are synchronous (e.g. All-Reduce), but these require waiting for all workers in each step. Thus, these methods are limited by the delays caused by straggling workers. Results: We study a typical scenario in which workers are straggling due to variability in compute time. We find an analytical relation between compute time properties and scalability limitations, caused by such straggling workers. With these findings, we propose a simple yet effective decentralized method to reduce the variation among workers and thus improve the robustness of synchronous training. This method can be integrated with the widely used All-Reduce. Our findings are validated on large-scale training tasks using 200 Gaudi Accelerators.
DeepShadow: Neural Shape from Shadow
Mar 28, 2022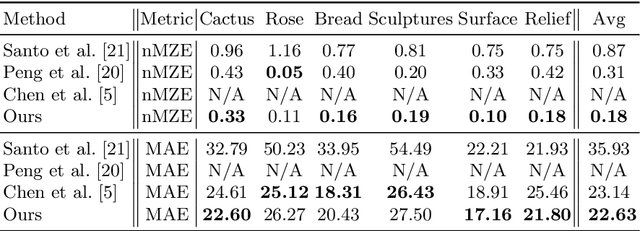
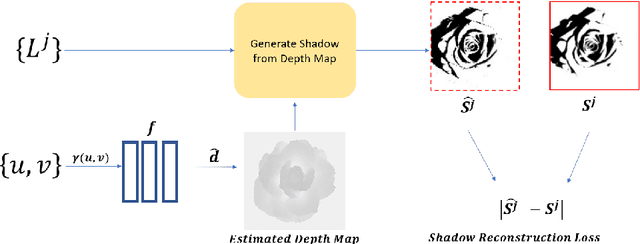

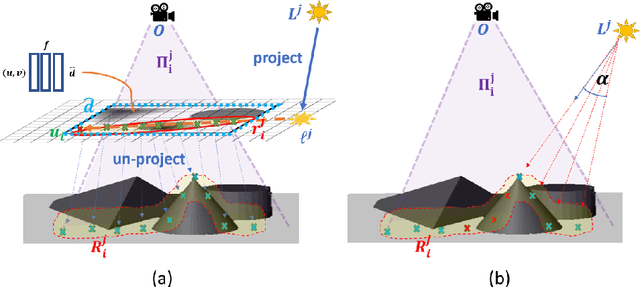
This paper presents DeepShadow, a one-shot method for recovering the depth map and surface normals from photometric stereo shadow maps. Previous works that try to recover the surface normals from photometric stereo images treat cast shadows as a disturbance. We show that the self and cast shadows not only do not disturb 3D reconstruction, but can be used alone, as a strong learning signal, to recover the depth map and surface normals. We demonstrate that 3D reconstruction from shadows can even outperform shape-from-shading in certain cases. To the best of our knowledge, our method is the first to reconstruct 3D shape-from-shadows using neural networks. The method does not require any pre-training or expensive labeled data, and is optimized during inference time.