 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Image Denoising with Knowledge Distillation for High-Performance Mobile NPUs
May 05, 2026While deep-learning-based image restoration has achieved unprecedented fidelity, deployment on mobile Neural Processing Units (NPUs) remains bottlenecked by operator incompatibility and memory-access overhead. We propose an NPU-aware hardware-algorithm co-design approach for real-world image denoising on mobile NPUs. Our approach employs a high-capacity teacher to supervise a lightweight student network specifically designed to leverage the tiled-memory architectures of modern mobile SoCs. By prioritizing NPU-native primitives -- standard 3x3 convolutions, ReLU activations, and nearest-neighbor upsampling -- and employing a progressive context expansion strategy (up to 1024x1024 crops), the model achieves 37.66 dB PSNR / 0.9278 SSIM on the validation benchmark and 37.58 dB PSNR / 0.9098 SSIM on the held-out test benchmark at full resolution (2432x3200) in the Mobile AI 2026 challenge. Following the official challenge rules, the inference runtime is measured under a standardized Full HD (1088x1920) protocol, where it runs in 34.0 ms on the MediaTek Dimensity 9500 and 46.1 ms on the Qualcomm Snapdragon 8 Elite NPU. We further reveal an "Inference Inversion" effect, where strict adherence to NPU-compatible operations enables dedicated NPU execution up to 3.88x faster than the integrated mobile GPU. The 1.96M-parameter student recovers 99.8% of the teacher's restoration quality via high-alpha knowledge distillation (alpha = 0.9), achieving a 21.2x parameter reduction while closing the PSNR gap from 1.63 dB to only 0.05 dB. These results establish hardware-aware distillation as an effective strategy for unifying high-fidelity denoising with practical deployment across diverse mobile NPU architectures. The proposed lightweight student model (LiteDenoiseNet) and its training statistics are provided in the NN Dataset, available at https://github.com/ABrain-One/NN-Dataset.
VFNet: A Convolutional Architecture for Accent Classification
Oct 15, 2019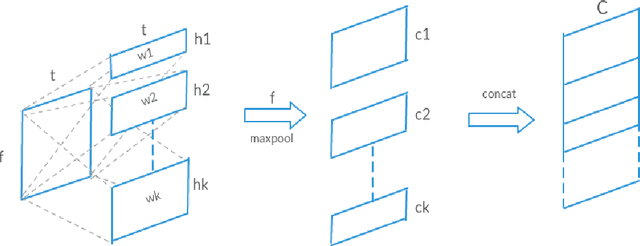
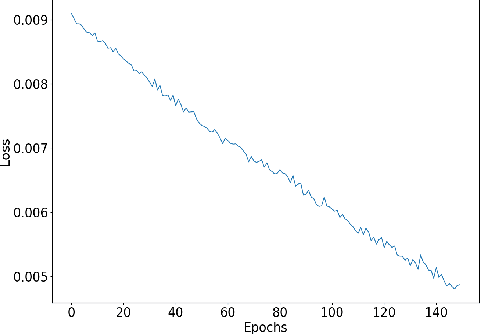
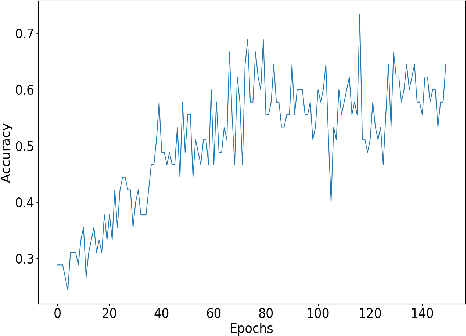
Understanding accent is an issue which can derail any human-machine interaction. Accent classification makes this task easier by identifying the accent being spoken by a person so that the correct words being spoken can be identified by further processing, since same noises can mean entirely different words in different accents of the same language. In this paper, we present VFNet (Variable Filter Net), a convolutional neural network (CNN) based architecture which captures a hierarchy of features to beat the previous benchmarks of accent classification, through a novel and elegant technique of applying variable filter sizes along the frequency band of the audio utterances.
Autoencoder Based Architecture For Fast & Real Time Audio Style Transfer
Dec 26, 2018
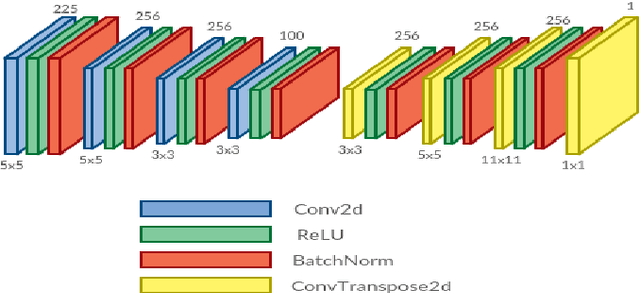
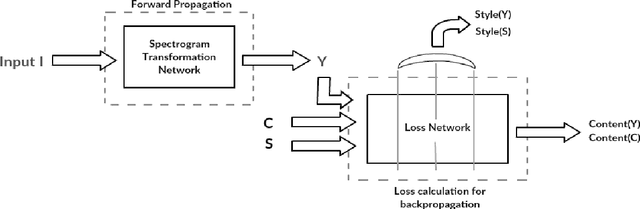

Recently, there has been great interest in the field of audio style transfer, where a stylized audio is generated by imposing the style of a reference audio on the content of a target audio. We improve on the current approaches which use neural networks to extract the content and the style of the audio signal and propose a new autoencoder based architecture for the task. This network generates a stylized audio for a content audio in a single forward pass. The proposed network architecture proves to be advantageous over the quality of audio produced and the time taken to train the network. The network is experimented on speech signals to confirm the validity of our proposal.