 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeywords are not always the key: A metadata field analysis for natural language search on open data portals
Sep 17, 2025Open data portals are essential for providing public access to open datasets. However, their search interfaces typically rely on keyword-based mechanisms and a narrow set of metadata fields. This design makes it difficult for users to find datasets using natural language queries. The problem is worsened by metadata that is often incomplete or inconsistent, especially when users lack familiarity with domain-specific terminology. In this paper, we examine how individual metadata fields affect the success of conversational dataset retrieval and whether LLMs can help bridge the gap between natural queries and structured metadata. We conduct a controlled ablation study using simulated natural language queries over real-world datasets to evaluate retrieval performance under various metadata configurations. We also compare existing content of the metadata field 'description' with LLM-generated content, exploring how different prompting strategies influence quality and impact on search outcomes. Our findings suggest that dataset descriptions play a central role in aligning with user intent, and that LLM-generated descriptions can support effective retrieval. These results highlight both the limitations of current metadata practices and the potential of generative models to improve dataset discoverability in open data portals.
Towards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Visual Analytics approach for finding spatiotemporal patterns from COVID19
Jan 16, 2021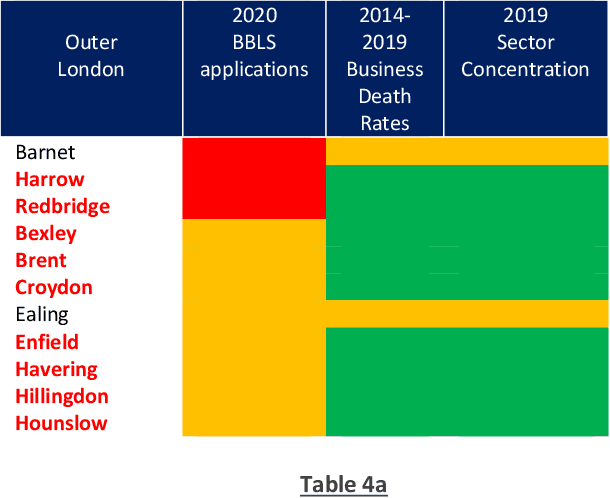
Bounce Back Loan is amongst a number of UK business financial support schemes launched by UK Government in 2020 amidst pandemic lockdown. Through these schemes, struggling businesses are provided financial support to weather economic slowdown from pandemic lockdown. {\pounds}43.5bn loan value has been provided as of 17th Dec2020. However, with no major checks for granting these loans and looming prospect of loan losses from write-offs from failed businesses and fraud, this paper theorizes prospect of applying spatiotemporal modelling technique to explore if geospatial patterns and temporal analysis could aid design of loan grant criteria for schemes. Application of Clustering and Visual Analytics framework to business demographics, survival rate and Sector concentration shows Inner and Outer London spatial patterns which historic business failures and reversal of the patterns under COVID-19 implying sector influence on spatial clusters. Combination of unsupervised clustering technique with multinomial logistic regression modelling on research datasets complimented by additional datasets on other support schemes, business structure and financial crime, is recommended for modelling business vulnerability to certain types of financial market or economic condition. The limitations of clustering technique for high dimensional is discussed along with relevance of an applicable model for continuing the research through next steps.