 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditable Neural Networks
Apr 01, 2020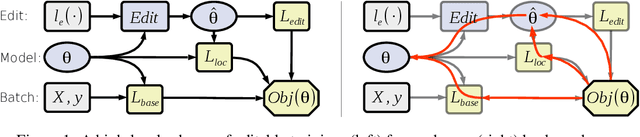



These days deep neural networks are ubiquitously used in a wide range of tasks, from image classification and machine translation to face identification and self-driving cars. In many applications, a single model error can lead to devastating financial, reputational and even life-threatening consequences. Therefore, it is crucially important to correct model mistakes quickly as they appear. In this work, we investigate the problem of neural network editing $-$ how one can efficiently patch a mistake of the model on a particular sample, without influencing the model behavior on other samples. Namely, we propose Editable Training, a model-agnostic training technique that encourages fast editing of the trained model. We empirically demonstrate the effectiveness of this method on large-scale image classification and machine translation tasks.
Unsupervised Discovery of Interpretable Directions in the GAN Latent Space
Feb 18, 2020
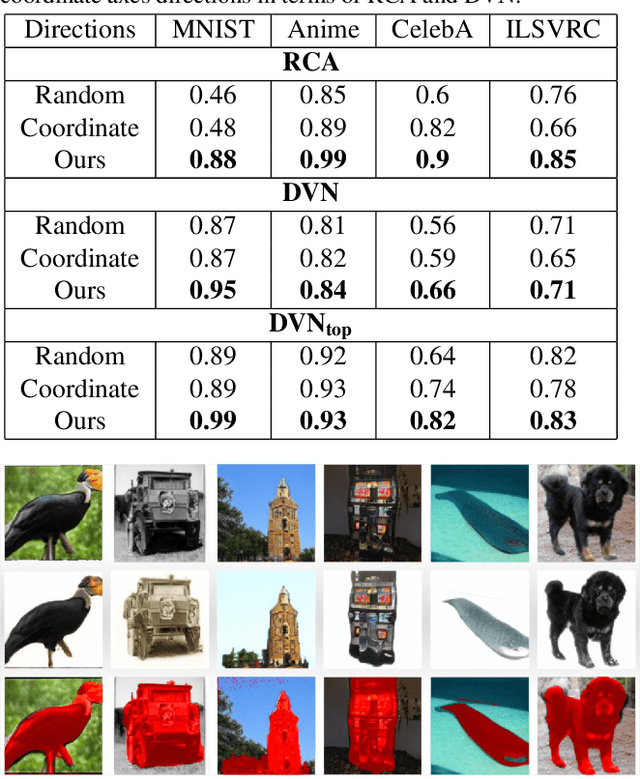


The latent spaces of typical GAN models often have semantically meaningful directions. Moving in these directions corresponds to human-interpretable image transformations, such as zooming or recoloring, enabling a more controllable generation process. However, the discovery of such directions is currently performed in a supervised manner, requiring human labels, pretrained models, or some form of self-supervision. These requirements can severely limit a range of directions existing approaches can discover. In this paper, we introduce an unsupervised method to identify interpretable directions in the latent space of a pretrained GAN model. By a simple model-agnostic procedure, we find directions corresponding to sensible semantic manipulations without any form of (self-)supervision. Furthermore, we reveal several non-trivial findings, which would be difficult to obtain by existing methods, e.g., a direction corresponding to background removal. As an immediate practical benefit of our work, we show how to exploit this finding to achieve a new state-of-the-art for the problem of saliency detection.
RPGAN: GANs Interpretability via Random Routing
Feb 17, 2020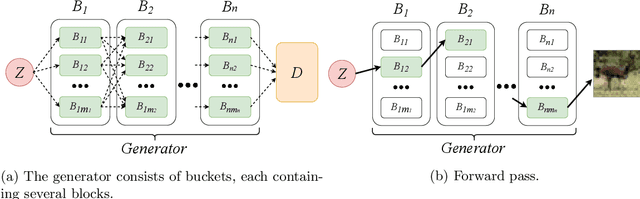

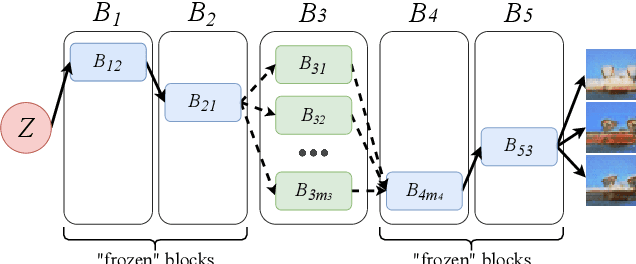

In this paper, we introduce Random Path Generative Adversarial Network (RPGAN) -- an alternative design of GANs that can serve as a tool for generative model analysis. While the latent space of a typical GAN consists of input vectors, randomly sampled from the standard Gaussian distribution, the latent space of RPGAN consists of random paths in a generator network. As we show, this design allows to understand factors of variation, captured by different generator layers, providing their natural interpretability. With experiments on standard benchmarks, we demonstrate that RPGAN reveals several interesting insights about the roles that different layers play in the image generation process. Aside from interpretability, the RPGAN model also provides competitive generation quality and allows efficient incremental learning on new data.
Towards Similarity Graphs Constructed by Deep Reinforcement Learning
Nov 27, 2019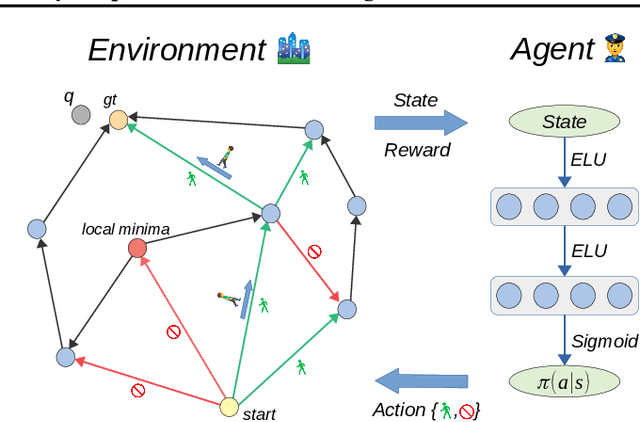
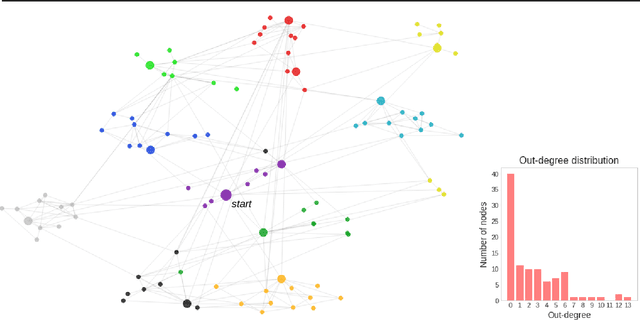
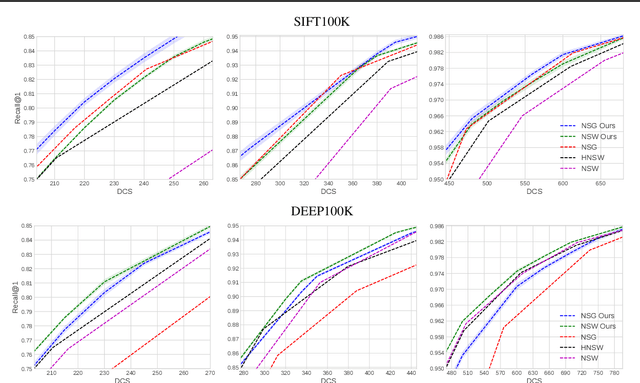
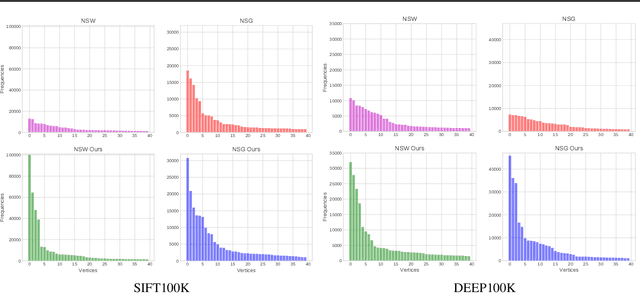
Similarity graphs are an active research direction for the nearest neighbor search (NNS) problem. New algorithms for similarity graph construction are continuously being proposed and analyzed by both theoreticians and practitioners. However, existing construction algorithms are mostly based on heuristics and do not explicitly maximize the target performance measure, i.e., search recall. Therefore, at the moment it is not clear whether the performance of similarity graphs has plateaued or more effective graphs can be constructed with more theoretically grounded methods. In this paper, we introduce a new principled algorithm, based on adjacency matrix optimization, which explicitly maximizes search efficiency. Namely, we propose a probabilistic model of a similarity graph defined in terms of its edge probabilities and show how to learn these probabilities from data as a reinforcement learning task. As confirmed by experiments, the proposed construction method can be used to refine the state-of-the-art similarity graphs, achieving higher recall rates for the same number of distance computations. Furthermore, we analyze the learned graphs and reveal the structural properties that are responsible for more efficient search.
Beyond Vector Spaces: Compact Data Representation as Differentiable Weighted Graphs
Oct 16, 2019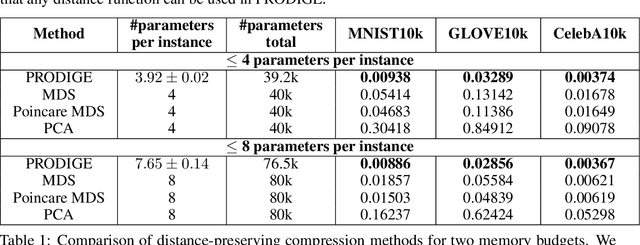
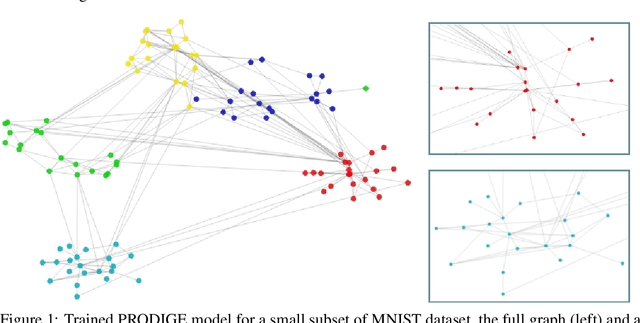
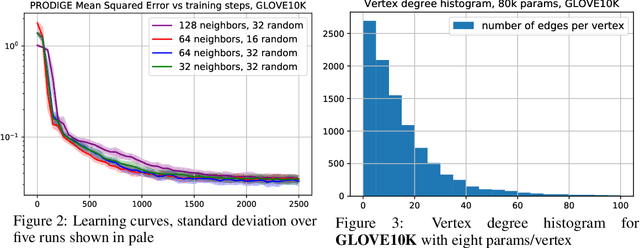
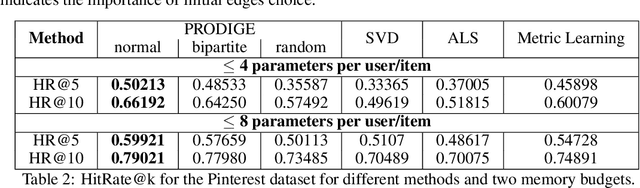
Learning useful representations is a key ingredient to the success of modern machine learning. Currently, representation learning mostly relies on embedding data into Euclidean space. However, recent work has shown that data in some domains is better modeled by non-euclidean metric spaces, and inappropriate geometry can result in inferior performance. In this paper, we aim to eliminate the inductive bias imposed by the embedding space geometry. Namely, we propose to map data into more general non-vector metric spaces: a weighted graph with a shortest path distance. By design, such graphs can model arbitrary geometry with a proper configuration of edges and weights. Our main contribution is PRODIGE: a method that learns a weighted graph representation of data end-to-end by gradient descent. Greater generality and fewer model assumptions make PRODIGE more powerful than existing embedding-based approaches. We confirm the superiority of our method via extensive experiments on a wide range of tasks, including classification, compression, and collaborative filtering.
Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data
Sep 19, 2019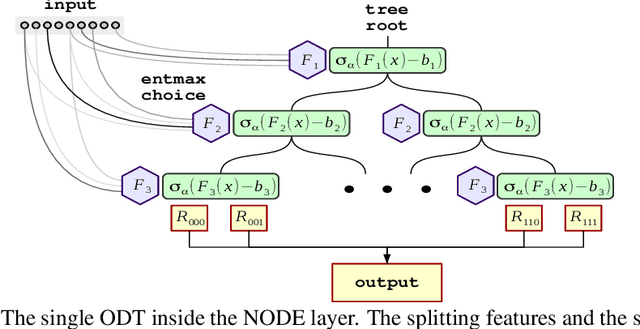

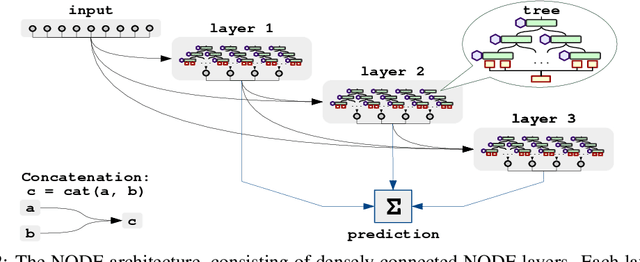

Nowadays, deep neural networks (DNNs) have become the main instrument for machine learning tasks within a wide range of domains, including vision, NLP, and speech. Meanwhile, in an important case of heterogenous tabular data, the advantage of DNNs over shallow counterparts remains questionable. In particular, there is no sufficient evidence that deep learning machinery allows constructing methods that outperform gradient boosting decision trees (GBDT), which are often the top choice for tabular problems. In this paper, we introduce Neural Oblivious Decision Ensembles (NODE), a new deep learning architecture, designed to work with any tabular data. In a nutshell, the proposed NODE architecture generalizes ensembles of oblivious decision trees, but benefits from both end-to-end gradient-based optimization and the power of multi-layer hierarchical representation learning. With an extensive experimental comparison to the leading GBDT packages on a large number of tabular datasets, we demonstrate the advantage of the proposed NODE architecture, which outperforms the competitors on most of the tasks. We open-source the PyTorch implementation of NODE and believe that it will become a universal framework for machine learning on tabular data.
Unsupervised Neural Quantization for Compressed-Domain Similarity Search
Aug 11, 2019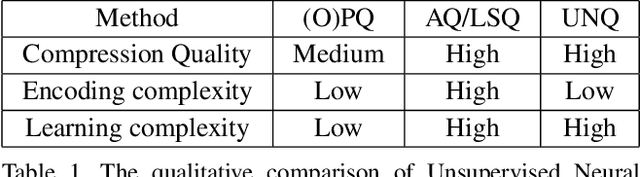
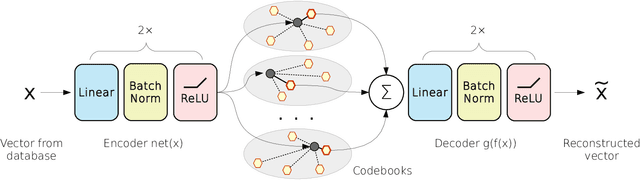
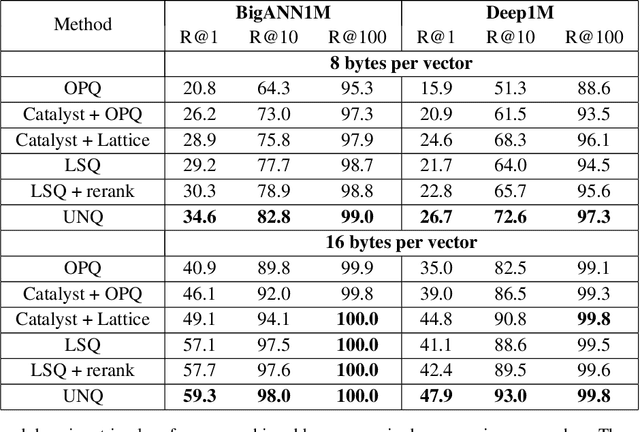
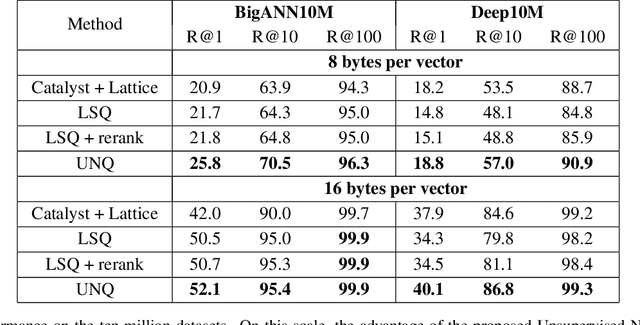
We tackle the problem of unsupervised visual descriptors compression, which is a key ingredient of large-scale image retrieval systems. While the deep learning machinery has benefited literally all computer vision pipelines, the existing state-of-the-art compression methods employ shallow architectures, and we aim to close this gap by our paper. In more detail, we introduce a DNN architecture for the unsupervised compressed-domain retrieval, based on multi-codebook quantization. The proposed architecture is designed to incorporate both fast data encoding and efficient distances computation via lookup tables. We demonstrate the exceptional advantage of our scheme over existing quantization approaches on several datasets of visual descriptors via outperforming the previous state-of-the-art by a large margin.
Learning to Route in Similarity Graphs
May 27, 2019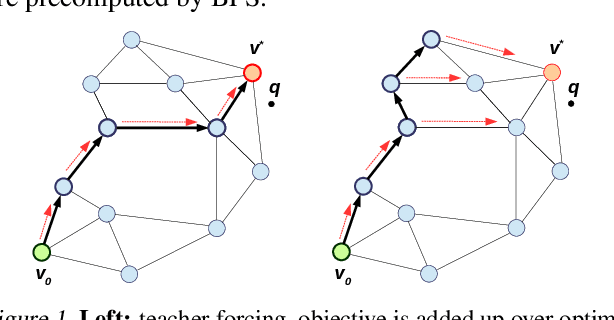
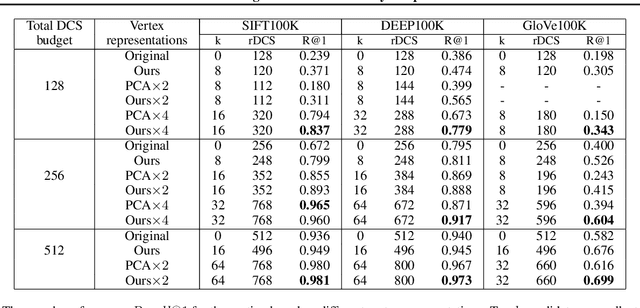
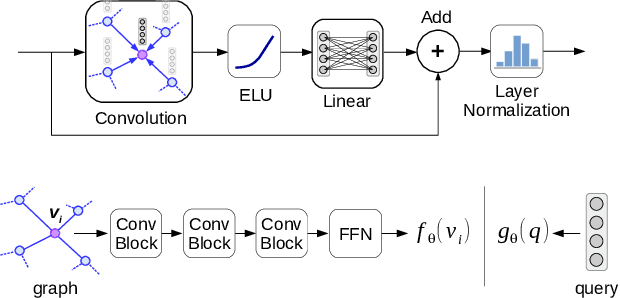
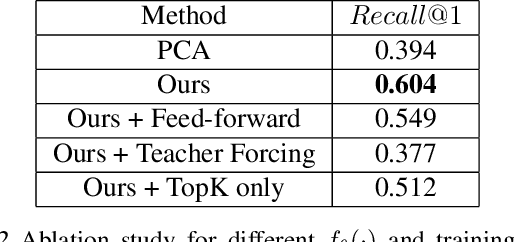
Recently similarity graphs became the leading paradigm for efficient nearest neighbor search, outperforming traditional tree-based and LSH-based methods. Similarity graphs perform the search via greedy routing: a query traverses the graph and in each vertex moves to the adjacent vertex that is the closest to this query. In practice, similarity graphs are often susceptible to local minima, when queries do not reach its nearest neighbors, getting stuck in suboptimal vertices. In this paper we propose to learn the routing function that overcomes local minima via incorporating information about the graph global structure. In particular, we augment the vertices of a given graph with additional representations that are learned to provide the optimal routing from the start vertex to the query nearest neighbor. By thorough experiments, we demonstrate that the proposed learnable routing successfully diminishes the local minima problem and significantly improves the overall search performance.
Revisiting the Inverted Indices for Billion-Scale Approximate Nearest Neighbors
Jul 23, 2018



This work addresses the problem of billion-scale nearest neighbor search. The state-of-the-art retrieval systems for billion-scale databases are currently based on the inverted multi-index, the recently proposed generalization of the inverted index structure. The multi-index provides a very fine-grained partition of the feature space that allows extracting concise and accurate short-lists of candidates for the search queries. In this paper, we argue that the potential of the simple inverted index was not fully exploited in previous works and advocate its usage both for the highly-entangled deep descriptors and relatively disentangled SIFT descriptors. We introduce a new retrieval system that is based on the inverted index and outperforms the multi-index by a large margin for the same memory consumption and construction complexity. For example, our system achieves the state-of-the-art recall rates several times faster on the dataset of one billion deep descriptors compared to the efficient implementation of the inverted multi-index from the FAISS library.
Impostor Networks for Fast Fine-Grained Recognition
Jun 13, 2018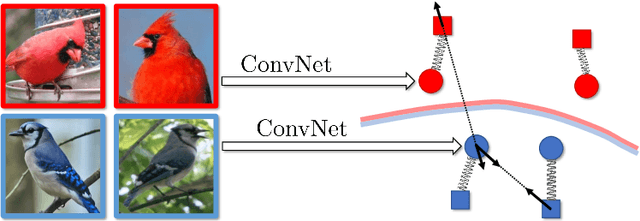
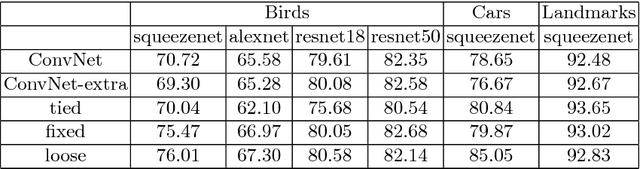
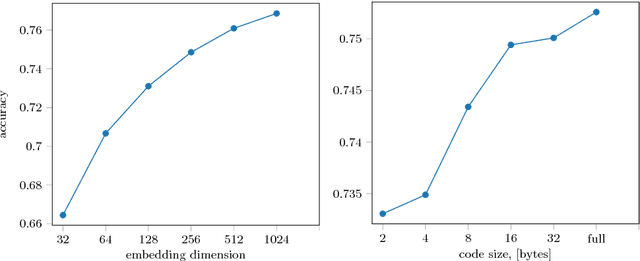
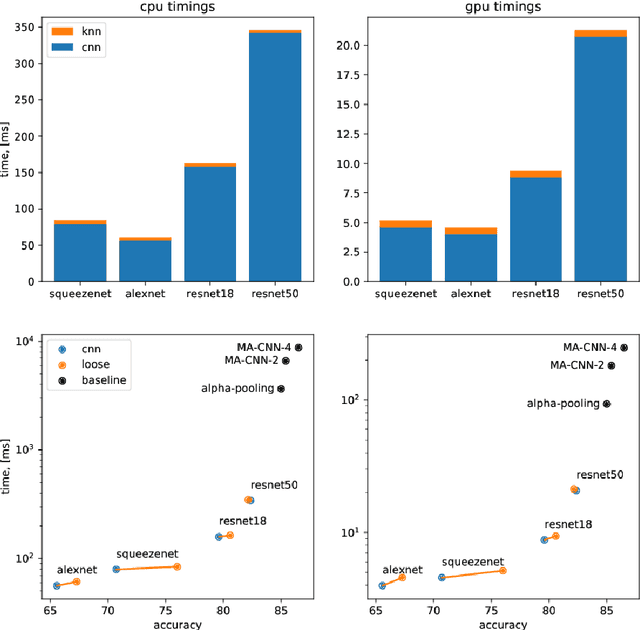
In this work we introduce impostor networks, an architecture that allows to perform fine-grained recognition with high accuracy and using a light-weight convolutional network, making it particularly suitable for fine-grained applications on low-power and non-GPU enabled platforms. Impostor networks compensate for the lightness of its `backend' network by combining it with a lightweight non-parametric classifier. The combination of a convolutional network and such non-parametric classifier is trained in an end-to-end fashion. Similarly to convolutional neural networks, impostor networks can fit large-scale training datasets very well, while also being able to generalize to new data points. At the same time, the bulk of computations within impostor networks happen through nearest neighbor search in high-dimensions. Such search can be performed efficiently on a variety of architectures including standard CPUs, where deep convolutional networks are inefficient. In a series of experiments with three fine-grained datasets, we show that impostor networks are able to boost the classification accuracy of a moderate-sized convolutional network considerably at a very small computational cost.