 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig GANs Are Watching You: Towards Unsupervised Object Segmentation with Off-the-Shelf Generative Models
Jun 08, 2020
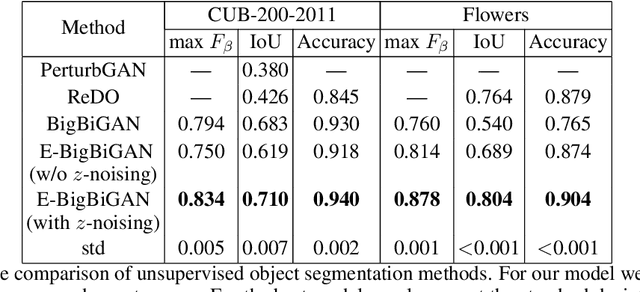
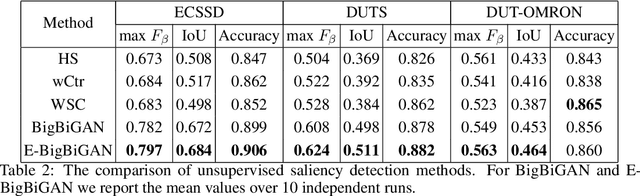

Since collecting pixel-level groundtruth data is expensive, unsupervised visual understanding problems are currently an active research topic. In particular, several recent methods based on generative models have achieved promising results for object segmentation and saliency detection. However, since generative models are known to be unstable and sensitive to hyperparameters, the training of these methods can be challenging and time-consuming. In this work, we introduce an alternative, much simpler way to exploit generative models for unsupervised object segmentation. First, we explore the latent space of the BigBiGAN -- the state-of-the-art unsupervised GAN, which parameters are publicly available. We demonstrate that object saliency masks for GAN-produced images can be obtained automatically with BigBiGAN. These masks then are used to train a discriminative segmentation model. Being very simple and easy-to-reproduce, our approach provides competitive performance on common benchmarks in the unsupervised scenario.
Beyond Vector Spaces: Compact Data Representation as Differentiable Weighted Graphs
Oct 16, 2019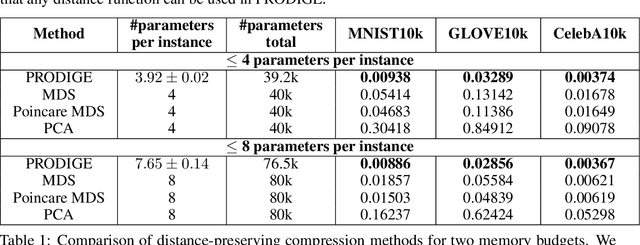
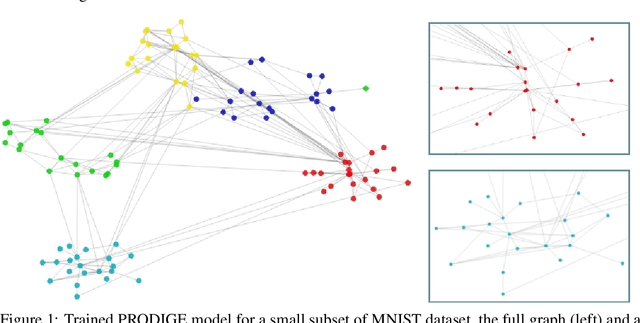
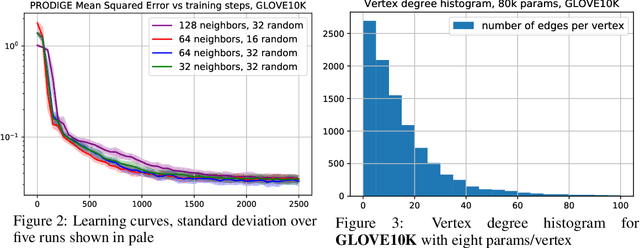
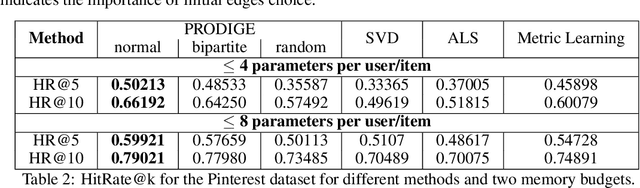
Learning useful representations is a key ingredient to the success of modern machine learning. Currently, representation learning mostly relies on embedding data into Euclidean space. However, recent work has shown that data in some domains is better modeled by non-euclidean metric spaces, and inappropriate geometry can result in inferior performance. In this paper, we aim to eliminate the inductive bias imposed by the embedding space geometry. Namely, we propose to map data into more general non-vector metric spaces: a weighted graph with a shortest path distance. By design, such graphs can model arbitrary geometry with a proper configuration of edges and weights. Our main contribution is PRODIGE: a method that learns a weighted graph representation of data end-to-end by gradient descent. Greater generality and fewer model assumptions make PRODIGE more powerful than existing embedding-based approaches. We confirm the superiority of our method via extensive experiments on a wide range of tasks, including classification, compression, and collaborative filtering.
Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data
Sep 19, 2019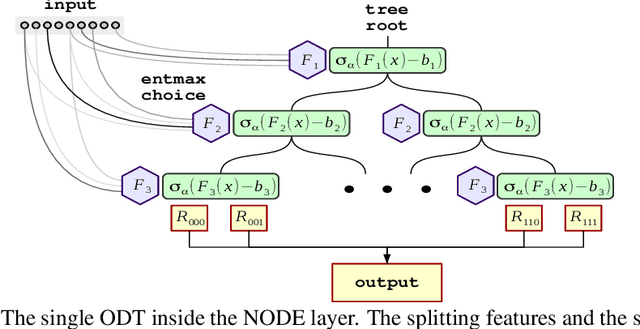

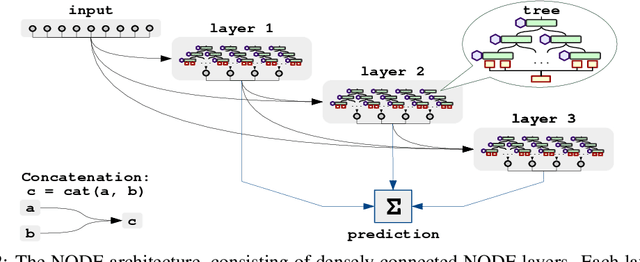

Nowadays, deep neural networks (DNNs) have become the main instrument for machine learning tasks within a wide range of domains, including vision, NLP, and speech. Meanwhile, in an important case of heterogenous tabular data, the advantage of DNNs over shallow counterparts remains questionable. In particular, there is no sufficient evidence that deep learning machinery allows constructing methods that outperform gradient boosting decision trees (GBDT), which are often the top choice for tabular problems. In this paper, we introduce Neural Oblivious Decision Ensembles (NODE), a new deep learning architecture, designed to work with any tabular data. In a nutshell, the proposed NODE architecture generalizes ensembles of oblivious decision trees, but benefits from both end-to-end gradient-based optimization and the power of multi-layer hierarchical representation learning. With an extensive experimental comparison to the leading GBDT packages on a large number of tabular datasets, we demonstrate the advantage of the proposed NODE architecture, which outperforms the competitors on most of the tasks. We open-source the PyTorch implementation of NODE and believe that it will become a universal framework for machine learning on tabular data.
Unsupervised Neural Quantization for Compressed-Domain Similarity Search
Aug 11, 2019
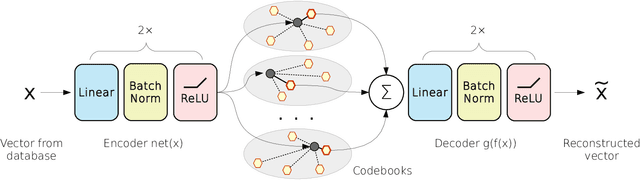
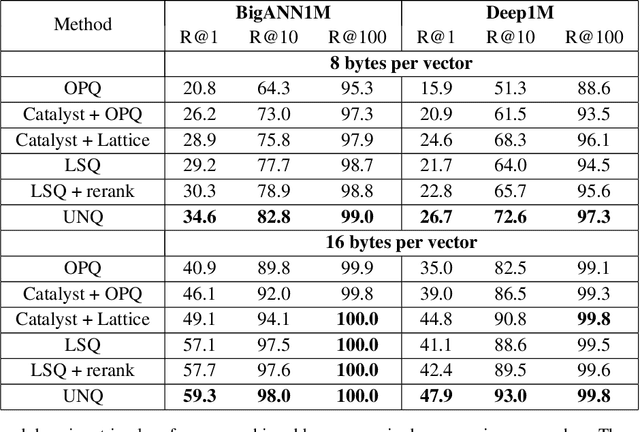
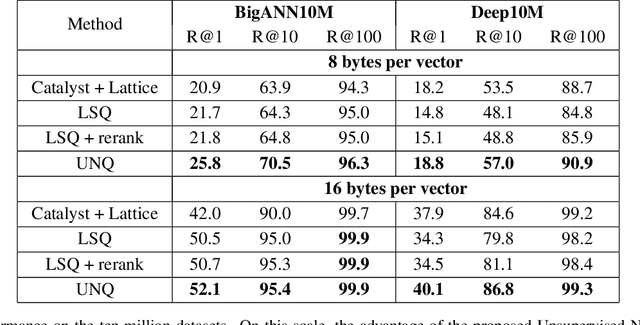
We tackle the problem of unsupervised visual descriptors compression, which is a key ingredient of large-scale image retrieval systems. While the deep learning machinery has benefited literally all computer vision pipelines, the existing state-of-the-art compression methods employ shallow architectures, and we aim to close this gap by our paper. In more detail, we introduce a DNN architecture for the unsupervised compressed-domain retrieval, based on multi-codebook quantization. The proposed architecture is designed to incorporate both fast data encoding and efficient distances computation via lookup tables. We demonstrate the exceptional advantage of our scheme over existing quantization approaches on several datasets of visual descriptors via outperforming the previous state-of-the-art by a large margin.