 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgek-Winners-Take-All Ensemble Neural Network
Jan 04, 2024Ensembling is one approach that improves the performance of a neural network by combining a number of independent neural networks, usually by either averaging or summing up their individual outputs. We modify this ensembling approach by training the sub-networks concurrently instead of independently. This concurrent training of sub-networks leads them to cooperate with each other, and we refer to them as "cooperative ensemble". Meanwhile, the mixture-of-experts approach improves a neural network performance by dividing up a given dataset to its sub-networks. It then uses a gating network that assigns a specialization to each of its sub-networks called "experts". We improve on these aforementioned ways for combining a group of neural networks by using a k-Winners-Take-All (kWTA) activation function, that acts as the combination method for the outputs of each sub-network in the ensemble. We refer to this proposed model as "kWTA ensemble neural networks" (kWTA-ENN). With the kWTA activation function, the losing neurons of the sub-networks are inhibited while the winning neurons are retained. This results in sub-networks having some form of specialization but also sharing knowledge with one another. We compare our approach with the cooperative ensemble and mixture-of-experts, where we used a feed-forward neural network with one hidden layer having 100 neurons as the sub-network architecture. Our approach yields a better performance compared to the baseline models, reaching the following test accuracies on benchmark datasets: 98.34% on MNIST, 88.06% on Fashion-MNIST, 91.56% on KMNIST, and 95.97% on WDBC.
Improving k-Means Clustering Performance with Disentangled Internal Representations
Jun 05, 2020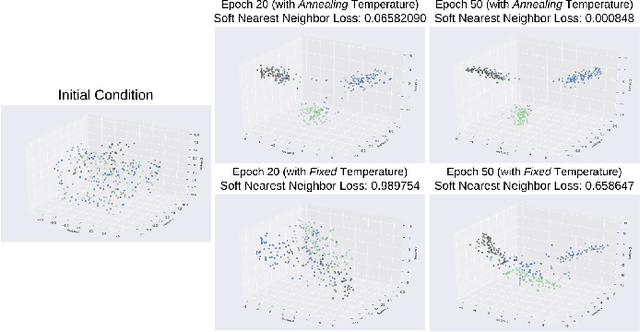
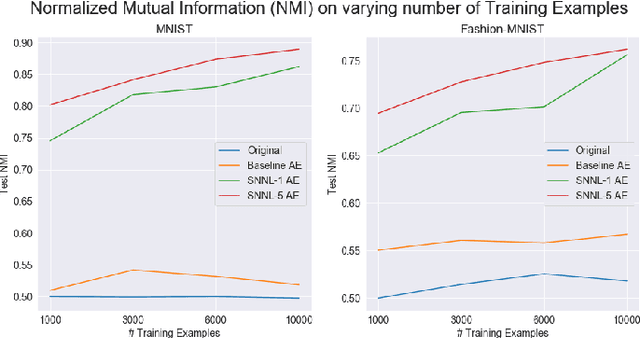
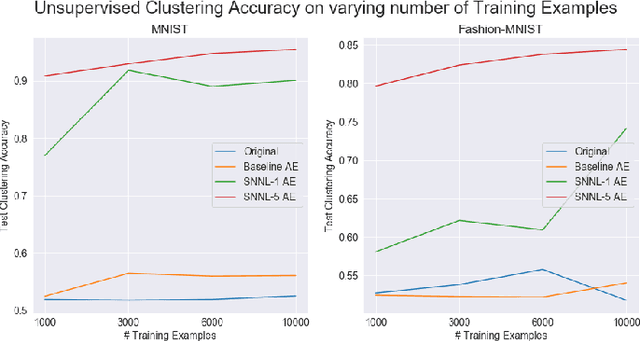

Deep clustering algorithms combine representation learning and clustering by jointly optimizing a clustering loss and a non-clustering loss. In such methods, a deep neural network is used for representation learning together with a clustering network. Instead of following this framework to improve clustering performance, we propose a simpler approach of optimizing the entanglement of the learned latent code representation of an autoencoder. We define entanglement as how close pairs of points from the same class or structure are, relative to pairs of points from different classes or structures. To measure the entanglement of data points, we use the soft nearest neighbor loss, and expand it by introducing an annealing temperature factor. Using our proposed approach, the test clustering accuracy was 96.2% on the MNIST dataset, 85.6% on the Fashion-MNIST dataset, and 79.2% on the EMNIST Balanced dataset, outperforming our baseline models.