 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgek-Winners-Take-All Ensemble Neural Network
Jan 04, 2024Ensembling is one approach that improves the performance of a neural network by combining a number of independent neural networks, usually by either averaging or summing up their individual outputs. We modify this ensembling approach by training the sub-networks concurrently instead of independently. This concurrent training of sub-networks leads them to cooperate with each other, and we refer to them as "cooperative ensemble". Meanwhile, the mixture-of-experts approach improves a neural network performance by dividing up a given dataset to its sub-networks. It then uses a gating network that assigns a specialization to each of its sub-networks called "experts". We improve on these aforementioned ways for combining a group of neural networks by using a k-Winners-Take-All (kWTA) activation function, that acts as the combination method for the outputs of each sub-network in the ensemble. We refer to this proposed model as "kWTA ensemble neural networks" (kWTA-ENN). With the kWTA activation function, the losing neurons of the sub-networks are inhibited while the winning neurons are retained. This results in sub-networks having some form of specialization but also sharing knowledge with one another. We compare our approach with the cooperative ensemble and mixture-of-experts, where we used a feed-forward neural network with one hidden layer having 100 neurons as the sub-network architecture. Our approach yields a better performance compared to the baseline models, reaching the following test accuracies on benchmark datasets: 98.34% on MNIST, 88.06% on Fashion-MNIST, 91.56% on KMNIST, and 95.97% on WDBC.
Text Classification and Clustering with Annealing Soft Nearest Neighbor Loss
Jul 23, 2021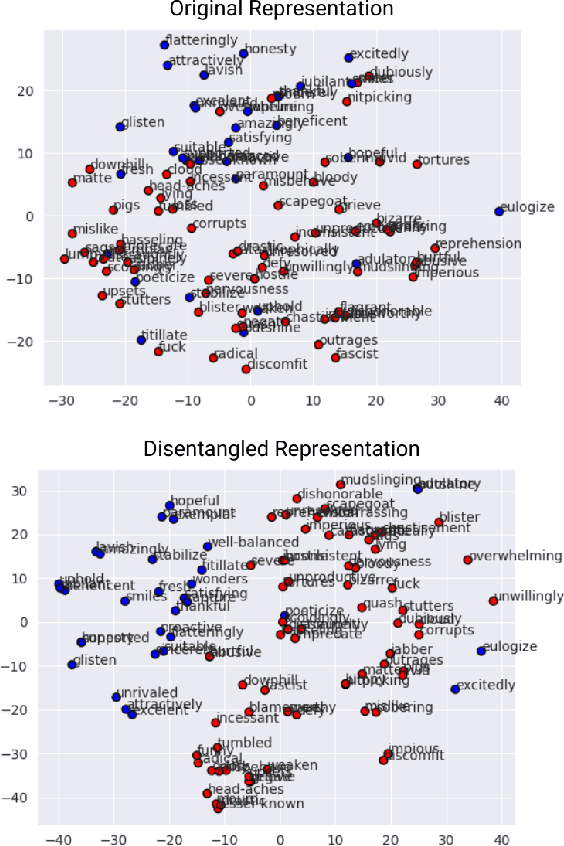


We define disentanglement as how far class-different data points from each other are, relative to the distances among class-similar data points. When maximizing disentanglement during representation learning, we obtain a transformed feature representation where the class memberships of the data points are preserved. If the class memberships of the data points are preserved, we would have a feature representation space in which a nearest neighbour classifier or a clustering algorithm would perform well. We take advantage of this method to learn better natural language representation, and employ it on text classification and text clustering tasks. Through disentanglement, we obtain text representations with better-defined clusters and improve text classification performance. Our approach had a test classification accuracy of as high as 90.11% and test clustering accuracy of 88% on the AG News dataset, outperforming our baseline models -- without any other training tricks or regularization.
Improving k-Means Clustering Performance with Disentangled Internal Representations
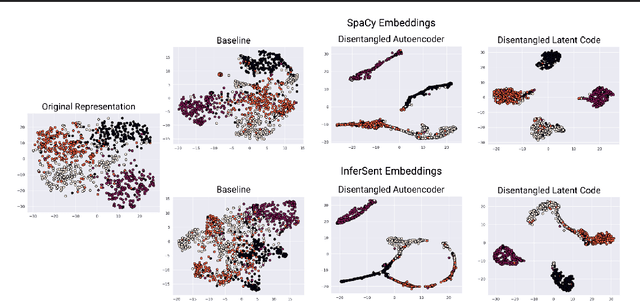
Jun 05, 2020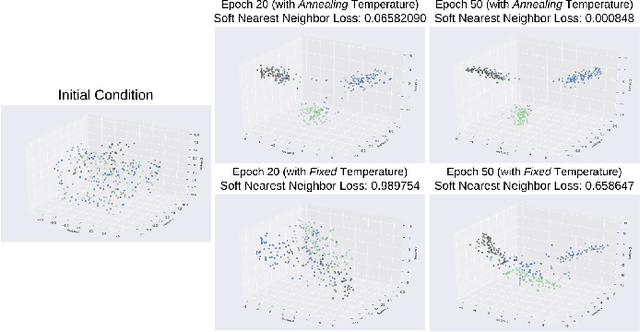
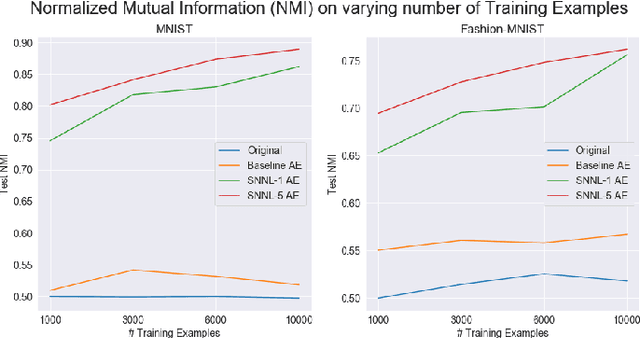
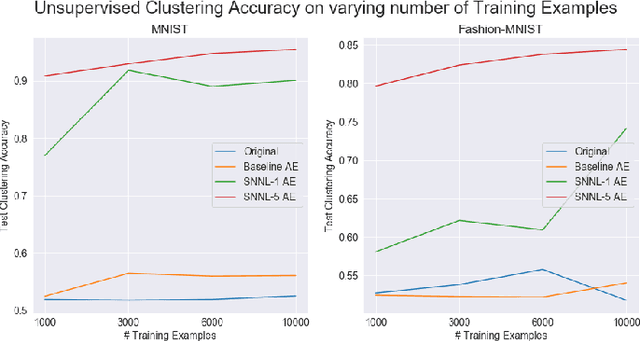

Deep clustering algorithms combine representation learning and clustering by jointly optimizing a clustering loss and a non-clustering loss. In such methods, a deep neural network is used for representation learning together with a clustering network. Instead of following this framework to improve clustering performance, we propose a simpler approach of optimizing the entanglement of the learned latent code representation of an autoencoder. We define entanglement as how close pairs of points from the same class or structure are, relative to pairs of points from different classes or structures. To measure the entanglement of data points, we use the soft nearest neighbor loss, and expand it by introducing an annealing temperature factor. Using our proposed approach, the test clustering accuracy was 96.2% on the MNIST dataset, 85.6% on the Fashion-MNIST dataset, and 79.2% on the EMNIST Balanced dataset, outperforming our baseline models.
Statistical Analysis on E-Commerce Reviews, with Sentiment Classification using Bidirectional Recurrent Neural Network (RNN)
May 08, 2018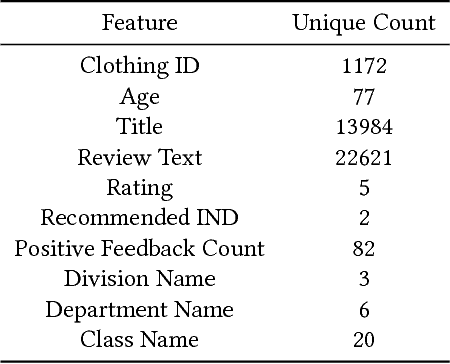
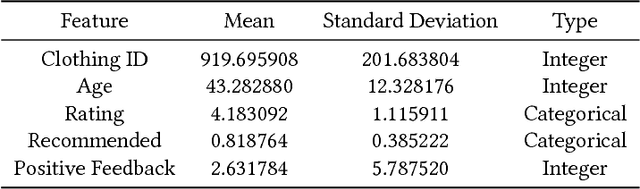
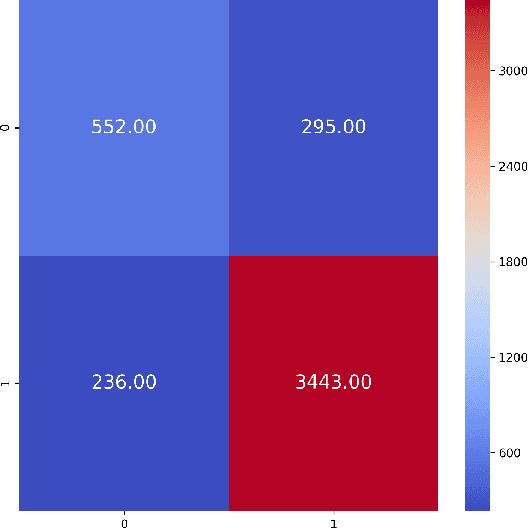
Understanding customer sentiments is of paramount importance in marketing strategies today. Not only will it give companies an insight as to how customers perceive their products and/or services, but it will also give them an idea on how to improve their offers. This paper attempts to understand the correlation of different variables in customer reviews on a women clothing e-commerce, and to classify each review whether it recommends the reviewed product or not and whether it consists of positive, negative, or neutral sentiment. To achieve these goals, we employed univariate and multivariate analyses on dataset features except for review titles and review texts, and we implemented a bidirectional recurrent neural network (RNN) with long-short term memory unit (LSTM) for recommendation and sentiment classification. Results have shown that a recommendation is a strong indicator of a positive sentiment score, and vice-versa. On the other hand, ratings in product reviews are fuzzy indicators of sentiment scores. We also found out that the bidirectional LSTM was able to reach an F1-score of 0.88 for recommendation classification, and 0.93 for sentiment classification.
Deep Learning using Rectified Linear Units (ReLU)
Mar 22, 2018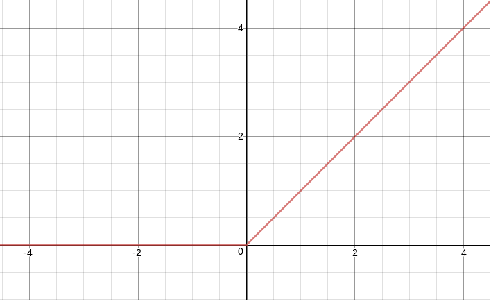
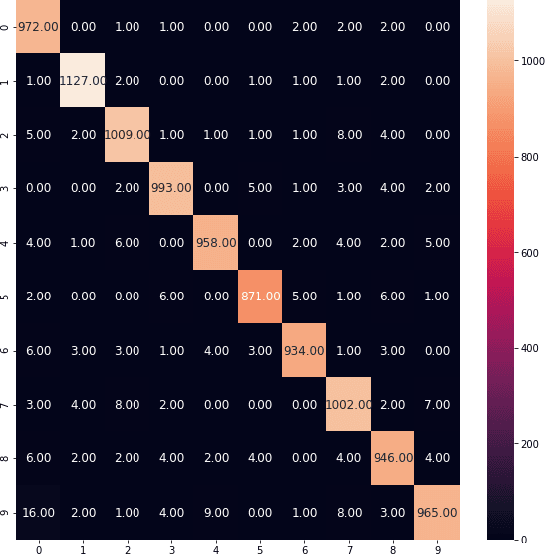
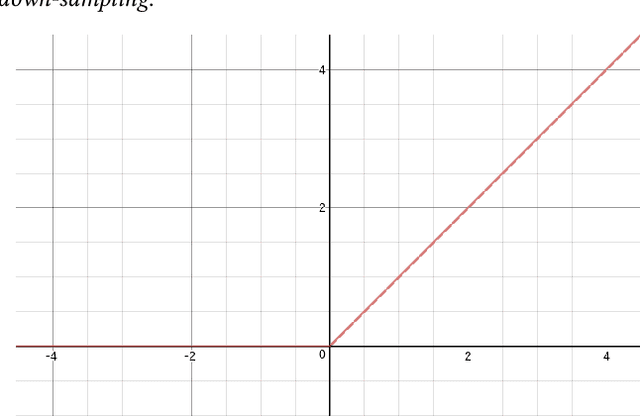
We introduce the use of rectified linear units (ReLU) as the classification function in a deep neural network (DNN). Conventionally, ReLU is used as an activation function in DNNs, with Softmax function as their classification function. However, there have been several studies on using a classification function other than Softmax, and this study is an addition to those. We accomplish this by taking the activation of the penultimate layer $h_{n - 1}$ in a neural network, then multiply it by weight parameters $\theta$ to get the raw scores $o_{i}$. Afterwards, we threshold the raw scores $o_{i}$ by $0$, i.e. $f(o) = \max(0, o_{i})$, where $f(o)$ is the ReLU function. We provide class predictions $\hat{y}$ through argmax function, i.e. argmax $f(x)$.
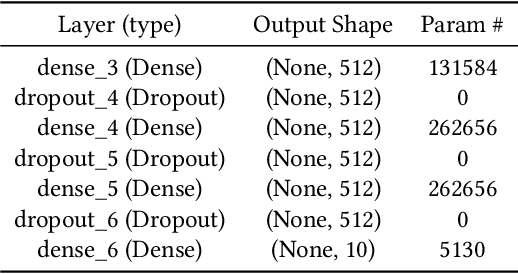
A Neural Network Architecture Combining Gated Recurrent Unit (GRU) and Support Vector Machine (SVM) for Intrusion Detection in Network Traffic Data
Mar 10, 2018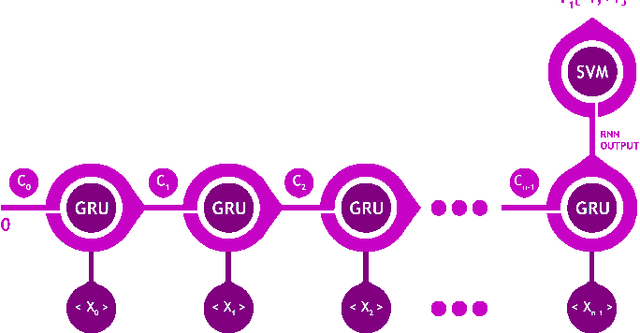
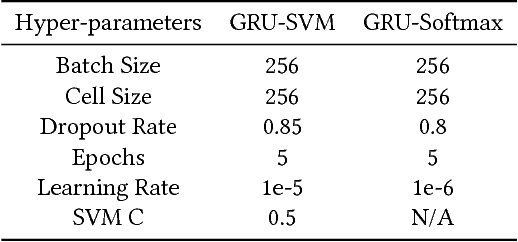

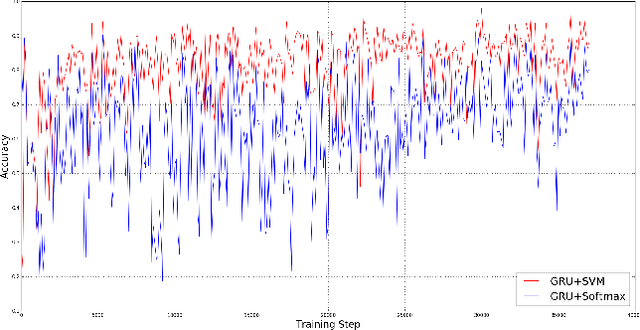
Gated Recurrent Unit (GRU) is a recently-developed variation of the long short-term memory (LSTM) unit, both of which are types of recurrent neural network (RNN). Through empirical evidence, both models have been proven to be effective in a wide variety of machine learning tasks such as natural language processing (Wen et al., 2015), speech recognition (Chorowski et al., 2015), and text classification (Yang et al., 2016). Conventionally, like most neural networks, both of the aforementioned RNN variants employ the Softmax function as its final output layer for its prediction, and the cross-entropy function for computing its loss. In this paper, we present an amendment to this norm by introducing linear support vector machine (SVM) as the replacement for Softmax in the final output layer of a GRU model. Furthermore, the cross-entropy function shall be replaced with a margin-based function. While there have been similar studies (Alalshekmubarak & Smith, 2013; Tang, 2013), this proposal is primarily intended for binary classification on intrusion detection using the 2013 network traffic data from the honeypot systems of Kyoto University. Results show that the GRU-SVM model performs relatively higher than the conventional GRU-Softmax model. The proposed model reached a training accuracy of ~81.54% and a testing accuracy of ~84.15%, while the latter was able to reach a training accuracy of ~63.07% and a testing accuracy of ~70.75%. In addition, the juxtaposition of these two final output layers indicate that the SVM would outperform Softmax in prediction time - a theoretical implication which was supported by the actual training and testing time in the study.
On Breast Cancer Detection: An Application of Machine Learning Algorithms on the Wisconsin Diagnostic Dataset
Mar 06, 2018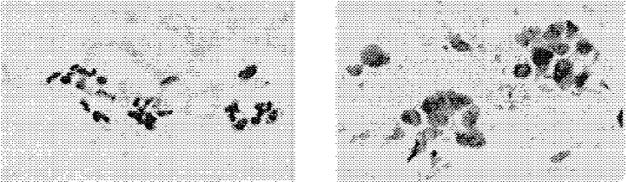

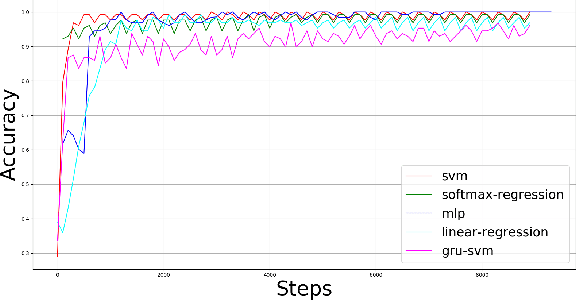

This paper presents a comparison of six machine learning (ML) algorithms: GRU-SVM (Agarap, 2017), Linear Regression, Multilayer Perceptron (MLP), Nearest Neighbor (NN) search, Softmax Regression, and Support Vector Machine (SVM) on the Wisconsin Diagnostic Breast Cancer (WDBC) dataset (Wolberg, Street, & Mangasarian, 1992) by measuring their classification test accuracy and their sensitivity and specificity values. The said dataset consists of features which were computed from digitized images of FNA tests on a breast mass (Wolberg, Street, & Mangasarian, 1992). For the implementation of the ML algorithms, the dataset was partitioned in the following fashion: 70% for training phase, and 30% for the testing phase. The hyper-parameters used for all the classifiers were manually assigned. Results show that all the presented ML algorithms performed well (all exceeded 90% test accuracy) on the classification task. The MLP algorithm stands out among the implemented algorithms with a test accuracy of ~99.04%.
Towards Building an Intelligent Anti-Malware System: A Deep Learning Approach using Support Vector Machine (SVM) for Malware Classification
Dec 31, 2017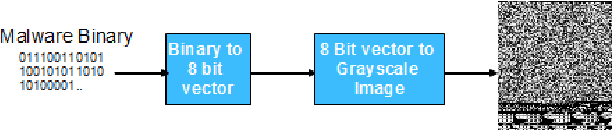
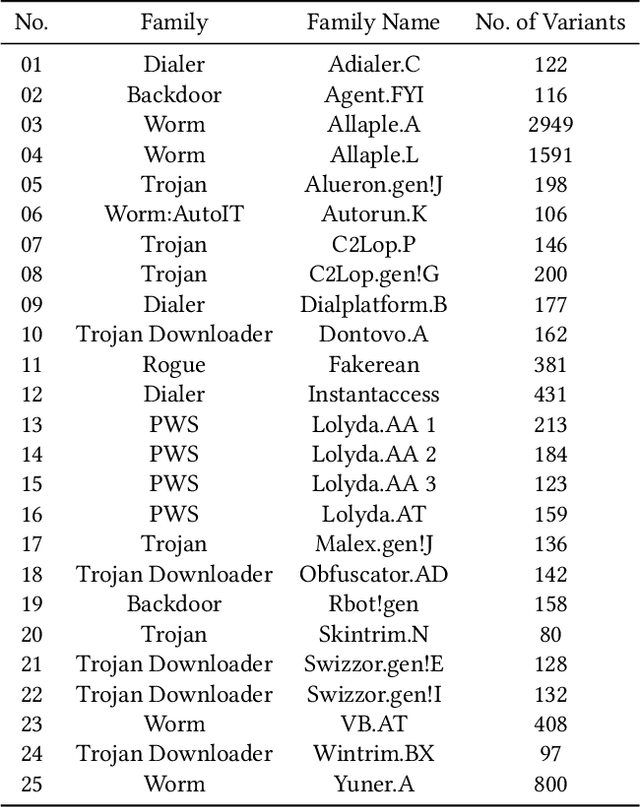
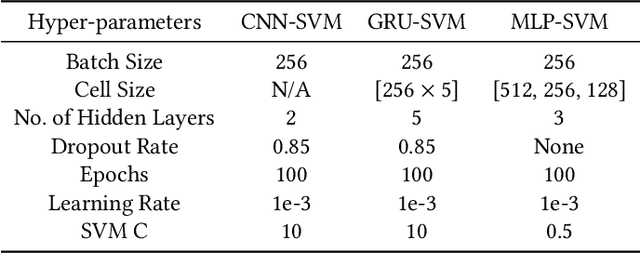
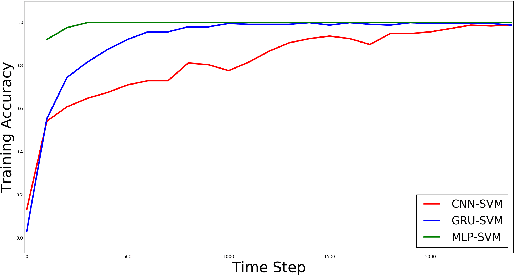
Effective and efficient mitigation of malware is a long-time endeavor in the information security community. The development of an anti-malware system that can counteract an unknown malware is a prolific activity that may benefit several sectors. We envision an intelligent anti-malware system that utilizes the power of deep learning (DL) models. Using such models would enable the detection of newly-released malware through mathematical generalization. That is, finding the relationship between a given malware $x$ and its corresponding malware family $y$, $f: x \mapsto y$. To accomplish this feat, we used the Malimg dataset (Nataraj et al., 2011) which consists of malware images that were processed from malware binaries, and then we trained the following DL models 1 to classify each malware family: CNN-SVM (Tang, 2013), GRU-SVM (Agarap, 2017), and MLP-SVM. Empirical evidence has shown that the GRU-SVM stands out among the DL models with a predictive accuracy of ~84.92%. This stands to reason for the mentioned model had the relatively most sophisticated architecture design among the presented models. The exploration of an even more optimal DL-SVM model is the next stage towards the engineering of an intelligent anti-malware system.
An Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification
Dec 10, 2017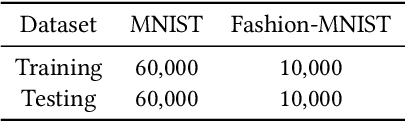
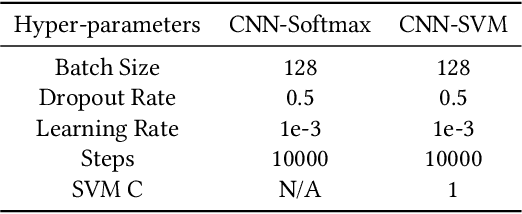
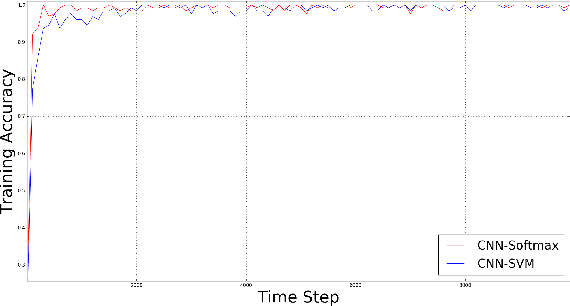
Convolutional neural networks (CNNs) are similar to "ordinary" neural networks in the sense that they are made up of hidden layers consisting of neurons with "learnable" parameters. These neurons receive inputs, performs a dot product, and then follows it with a non-linearity. The whole network expresses the mapping between raw image pixels and their class scores. Conventionally, the Softmax function is the classifier used at the last layer of this network. However, there have been studies (Alalshekmubarak and Smith, 2013; Agarap, 2017; Tang, 2013) conducted to challenge this norm. The cited studies introduce the usage of linear support vector machine (SVM) in an artificial neural network architecture. This project is yet another take on the subject, and is inspired by (Tang, 2013). Empirical data has shown that the CNN-SVM model was able to achieve a test accuracy of ~99.04% using the MNIST dataset (LeCun, Cortes, and Burges, 2010). On the other hand, the CNN-Softmax was able to achieve a test accuracy of ~99.23% using the same dataset. Both models were also tested on the recently-published Fashion-MNIST dataset (Xiao, Rasul, and Vollgraf, 2017), which is suppose to be a more difficult image classification dataset than MNIST (Zalandoresearch, 2017). This proved to be the case as CNN-SVM reached a test accuracy of ~90.72%, while the CNN-Softmax reached a test accuracy of ~91.86%. The said results may be improved if data preprocessing techniques were employed on the datasets, and if the base CNN model was a relatively more sophisticated than the one used in this study.