 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General framework for PAC-Bayes Bounds for Meta-Learning
Jun 11, 2022
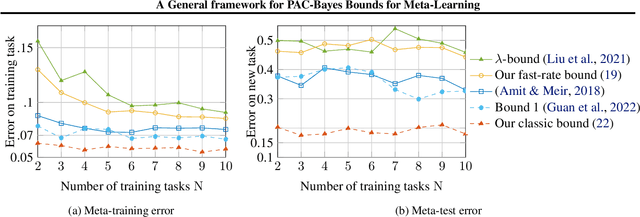
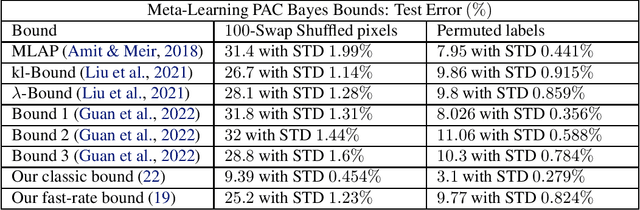
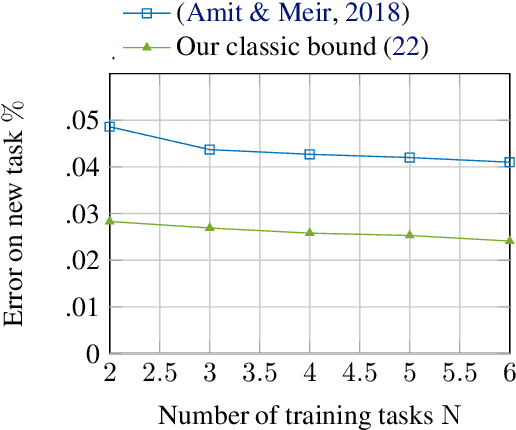
Meta learning automatically infers an inductive bias, that includes the hyperparameter of the base-learning algorithm, by observing data from a finite number of related tasks. This paper studies PAC-Bayes bounds on meta generalization gap. The meta-generalization gap comprises two sources of generalization gaps: the environment-level and task-level gaps resulting from observation of a finite number of tasks and data samples per task, respectively. In this paper, by upper bounding arbitrary convex functions, which link the expected and empirical losses at the environment and also per-task levels, we obtain new PAC-Bayes bounds. Using these bounds, we develop new PAC-Bayes meta-learning algorithms. Numerical examples demonstrate the merits of the proposed novel bounds and algorithm in comparison to prior PAC-Bayes bounds for meta-learning.
Conditional Mutual Information Bound for Meta Generalization Gap
Oct 21, 2020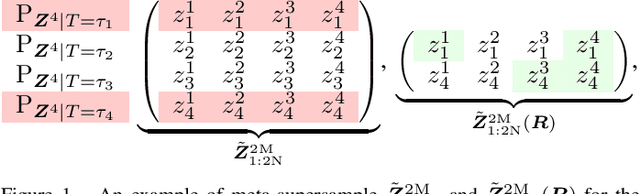
Meta-learning infers an inductive bias---typically in the form of the hyperparameters of a base-learning algorithm---by observing data from a finite number of related tasks. This paper presents an information-theoretic upper bound on the average meta-generalization gap that builds on the conditional mutual information (CMI) framework of Steinke and Zakynthinou (2020), which was originally developed for conventional learning. In the context of meta-learning, the CMI framework involves a training \textit{meta-supersample} obtained by first sampling $2N$ independent tasks from the task environment, and then drawing $2M$ independent training samples for each sampled task. The meta-training data fed to the meta-learner is then obtained by randomly selecting $N$ tasks from the available $2N$ tasks and $M$ training samples per task from the available $2M$ training samples per task. The resulting bound is explicit in two CMI terms, which measure the information that the meta-learner output and the base-learner output respectively provide about which training data are selected given the entire meta-supersample.