 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRECEPT: Planning Resilience via Experience, Context Engineering & Probing Trajectories A Unified Framework for Test-Time Adaptation with Compositional Rule Learning and Pareto-Guided Prompt Evolution
Mar 10, 2026LLM agents that store knowledge as natural language suffer steep retrieval degradation as condition count grows, often struggle to compose learned rules reliably, and typically lack explicit mechanisms to detect stale or adversarial knowledge. We introduce PRECEPT, a unified framework for test-time adaptation with three tightly coupled components: (1) deterministic exact-match rule retrieval over structured condition keys, (2) conflict-aware memory with Bayesian source reliability and threshold-based rule invalidation, and (3) COMPASS, a Pareto-guided prompt-evolution outer loop. Exact retrieval eliminates partial-match interpretation errors on the deterministic path (0% by construction, vs 94.4% under Theorem~B.6's independence model at N=10) and supports compositional stacking through a semantic tier hierarchy; conflict-aware memory resolves static--dynamic disagreements and supports drift adaptation; COMPASS evaluates prompts through the same end-to-end execution pipeline. Results (9--10 seeds): PRECEPT achieves a +41.1pp first-try advantage over Full Reflexion (d>1.9), +33.3pp compositional generalization (d=1.55), 100% $P_1$ on 2-way logistics compositions (d=2.64), +40--55pp continuous learning gains, strong eventual robustness under adversarial static knowledge (100% logistics with adversarial SK active; partial recovery on integration), +55.0pp drift recovery (d=0.95, p=0.031), and 61% fewer steps. Core comparisons are statistically significant, often at p<0.001.
Concurrent Brainstorming & Hypothesis Satisfying: An Iterative Framework for Enhanced Retrieval-Augmented Generation (R2CBR3H-SR)
Jan 03, 2024Addressing the complexity of comprehensive information retrieval, this study introduces an innovative, iterative retrieval-augmented generation system. Our approach uniquely integrates a vector-space driven re-ranking mechanism with concurrent brainstorming to expedite the retrieval of highly relevant documents, thereby streamlining the generation of potential queries. This sets the stage for our novel hybrid process, which synergistically combines hypothesis formulation with satisfying decision-making strategy to determine content adequacy, leveraging a chain of thought-based prompting technique. This unified hypothesize-satisfied phase intelligently distills information to ascertain whether user queries have been satisfactorily addressed. Upon reaching this criterion, the system refines its output into a concise representation, maximizing conceptual density with minimal verbosity. The iterative nature of the workflow enhances process efficiency and accuracy. Crucially, the concurrency within the brainstorming phase significantly accelerates recursive operations, facilitating rapid convergence to solution satisfaction. Compared to conventional methods, our system demonstrates a marked improvement in computational time and cost-effectiveness. This research advances the state-of-the-art in intelligent retrieval systems, setting a new benchmark for resource-efficient information extraction and abstraction in knowledge-intensive applications.
Dynamic Recognition of Speakers for Consent Management by Contrastive Embedding Replay
May 17, 2022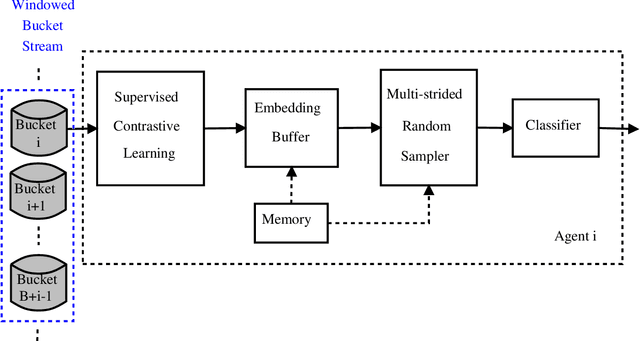

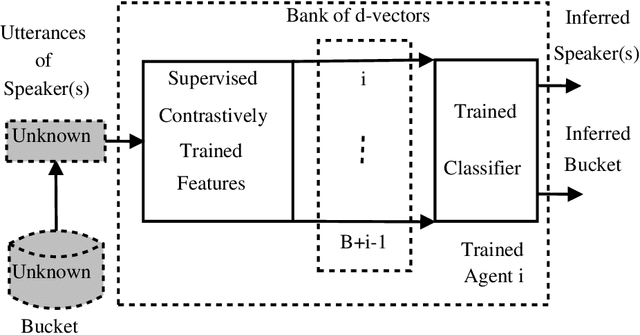
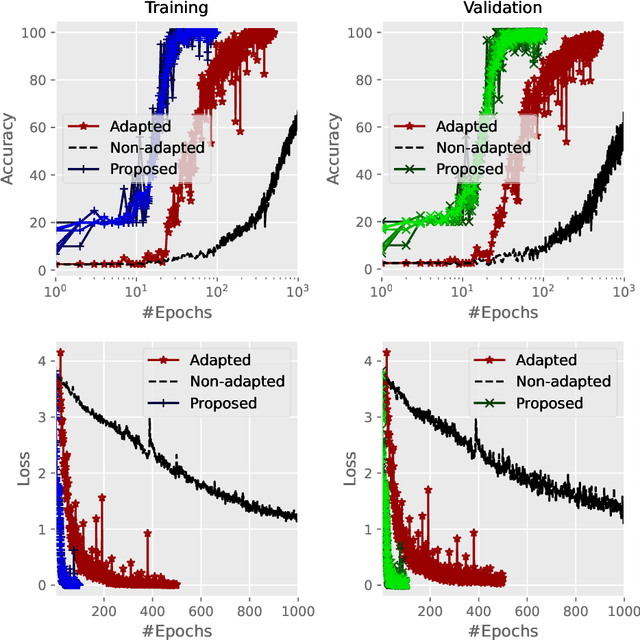
Voice assistants record sound and can overhear conversations. Thus, a consent management mechanism is desirable such that users can express their wish to be recorded or not. Consent management can be implemented using speaker recognition; users that do not give consent enrol their voice and all further recordings of these users is subsequently not processed. Building speaker recognition based consent management is challenging due to the dynamic nature of the problem, required scalability for large number of speakers, and need for fast speaker recognition with high accuracy. This paper describes a speaker recognition based consent management system addressing the aforementioned challenges. A fully supervised batch contrastive learning is applied to learn the underlying speaker equivariance inductive bias during the training on the set of speakers noting recording dissent. Speakers that do not provide consent are grouped in buckets which are trained continuously. The embeddings are contrastively learned for speakers in their buckets during training and act later as a replay buffer for classification. The buckets are progressively registered during training and a novel multi-strided random sampling of the contrastive embedding replay buffer is proposed. Buckets are contrastively trained for a few steps only in each iteration and replayed for classification progressively leading to fast convergence. An algorithm for fast and dynamic registration and removal of speakers in buckets is described. The evaluation results show that the proposed approach provides the desired fast and dynamic solution for consent management and outperforms existing approaches in terms of convergence speed and adaptive capabilities as well as verification performance during inference.