 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Hand Gesture Recognition via High-Density EMG Signals: From Instantaneous Recognition to Fusion of Motor Unit Spike Trains
Dec 07, 2022



Designing efficient and labor-saving prosthetic hands requires powerful hand gesture recognition algorithms that can achieve high accuracy with limited complexity and latency. In this context, the paper proposes a compact deep learning framework referred to as the CT-HGR, which employs a vision transformer network to conduct hand gesture recognition using highdensity sEMG (HD-sEMG) signals. The attention mechanism in the proposed model identifies similarities among different data segments with a greater capacity for parallel computations and addresses the memory limitation problems while dealing with inputs of large sequence lengths. CT-HGR can be trained from scratch without any need for transfer learning and can simultaneously extract both temporal and spatial features of HD-sEMG data. Additionally, the CT-HGR framework can perform instantaneous recognition using sEMG image spatially composed from HD-sEMG signals. A variant of the CT-HGR is also designed to incorporate microscopic neural drive information in the form of Motor Unit Spike Trains (MUSTs) extracted from HD-sEMG signals using Blind Source Separation (BSS). This variant is combined with its baseline version via a hybrid architecture to evaluate potentials of fusing macroscopic and microscopic neural drive information. The utilized HD-sEMG dataset involves 128 electrodes that collect the signals related to 65 isometric hand gestures of 20 subjects. The proposed CT-HGR framework is applied to 31.25, 62.5, 125, 250 ms window sizes of the above-mentioned dataset utilizing 32, 64, 128 electrode channels. The average accuracy over all the participants using 32 electrodes and a window size of 31.25 ms is 86.23%, which gradually increases till reaching 91.98% for 128 electrodes and a window size of 250 ms. The CT-HGR achieves accuracy of 89.13% for instantaneous recognition based on a single frame of HD-sEMG image.
ViT-CAT: Parallel Vision Transformers with Cross Attention Fusion for Popularity Prediction in MEC Networks
Oct 27, 2022

Mobile Edge Caching (MEC) is a revolutionary technology for the Sixth Generation (6G) of wireless networks with the promise to significantly reduce users' latency via offering storage capacities at the edge of the network. The efficiency of the MEC network, however, critically depends on its ability to dynamically predict/update the storage of caching nodes with the top-K popular contents. Conventional statistical caching schemes are not robust to the time-variant nature of the underlying pattern of content requests, resulting in a surge of interest in using Deep Neural Networks (DNNs) for time-series popularity prediction in MEC networks. However, existing DNN models within the context of MEC fail to simultaneously capture both temporal correlations of historical request patterns and the dependencies between multiple contents. This necessitates an urgent quest to develop and design a new and innovative popularity prediction architecture to tackle this critical challenge. The paper addresses this gap by proposing a novel hybrid caching framework based on the attention mechanism. Referred to as the parallel Vision Transformers with Cross Attention (ViT-CAT) Fusion, the proposed architecture consists of two parallel ViT networks, one for collecting temporal correlation, and the other for capturing dependencies between different contents. Followed by a Cross Attention (CA) module as the Fusion Center (FC), the proposed ViT-CAT is capable of learning the mutual information between temporal and spatial correlations, as well, resulting in improving the classification accuracy, and decreasing the model's complexity about 8 times. Based on the simulation results, the proposed ViT-CAT architecture outperforms its counterparts across the classification accuracy, complexity, and cache-hit ratio.
Spatio-Temporal Hybrid Fusion of CAE and SWIn Transformers for Lung Cancer Malignancy Prediction
Oct 27, 2022



The paper proposes a novel hybrid discovery Radiomics framework that simultaneously integrates temporal and spatial features extracted from non-thin chest Computed Tomography (CT) slices to predict Lung Adenocarcinoma (LUAC) malignancy with minimum expert involvement. Lung cancer is the leading cause of mortality from cancer worldwide and has various histologic types, among which LUAC has recently been the most prevalent. LUACs are classified as pre-invasive, minimally invasive, and invasive adenocarcinomas. Timely and accurate knowledge of the lung nodules malignancy leads to a proper treatment plan and reduces the risk of unnecessary or late surgeries. Currently, chest CT scan is the primary imaging modality to assess and predict the invasiveness of LUACs. However, the radiologists' analysis based on CT images is subjective and suffers from a low accuracy compared to the ground truth pathological reviews provided after surgical resections. The proposed hybrid framework, referred to as the CAET-SWin, consists of two parallel paths: (i) The Convolutional Auto-Encoder (CAE) Transformer path that extracts and captures informative features related to inter-slice relations via a modified Transformer architecture, and; (ii) The Shifted Window (SWin) Transformer path, which is a hierarchical vision transformer that extracts nodules' related spatial features from a volumetric CT scan. Extracted temporal (from the CAET-path) and spatial (from the Swin path) are then fused through a fusion path to classify LUACs. Experimental results on our in-house dataset of 114 pathologically proven Sub-Solid Nodules (SSNs) demonstrate that the CAET-SWin significantly improves reliability of the invasiveness prediction task while achieving an accuracy of 82.65%, sensitivity of 83.66%, and specificity of 81.66% using 10-fold cross-validation.
Hybrid Indoor Localization via Reinforcement Learning-based Information Fusion
Oct 27, 2022The paper is motivated by the importance of the Smart Cities (SC) concept for future management of global urbanization. Among all Internet of Things (IoT)-based communication technologies, Bluetooth Low Energy (BLE) plays a vital role in city-wide decision making and services. Extreme fluctuations of the Received Signal Strength Indicator (RSSI), however, prevent this technology from being a reliable solution with acceptable accuracy in the dynamic indoor tracking/localization approaches for ever-changing SC environments. The latest version of the BLE v.5.1 introduced a better possibility for tracking users by utilizing the direction finding approaches based on the Angle of Arrival (AoA), which is more reliable. There are still some fundamental issues remaining to be addressed. Existing works mainly focus on implementing stand-alone models overlooking potentials fusion strategies. The paper addresses this gap and proposes a novel Reinforcement Learning (RL)-based information fusion framework (RL-IFF) by coupling AoA with RSSI-based particle filtering and Inertial Measurement Unit (IMU)-based Pedestrian Dead Reckoning (PDR) frameworks. The proposed RL-IFF solution is evaluated through a comprehensive set of experiments illustrating superior performance compared to its counterparts.
Light-weighted CNN-Attention based architecture for Hand Gesture Recognition via ElectroMyography
Oct 27, 2022Advancements in Biological Signal Processing (BSP) and Machine-Learning (ML) models have paved the path for development of novel immersive Human-Machine Interfaces (HMI). In this context, there has been a surge of significant interest in Hand Gesture Recognition (HGR) utilizing Surface-Electromyogram (sEMG) signals. This is due to its unique potential for decoding wearable data to interpret human intent for immersion in Mixed Reality (MR) environments. To achieve the highest possible accuracy, complicated and heavy-weighted Deep Neural Networks (DNNs) are typically developed, which restricts their practical application in low-power and resource-constrained wearable systems. In this work, we propose a light-weighted hybrid architecture (HDCAM) based on Convolutional Neural Network (CNN) and attention mechanism to effectively extract local and global representations of the input. The proposed HDCAM model with 58,441 parameters reached a new state-of-the-art (SOTA) performance with 82.91% and 81.28% accuracy on window sizes of 300 ms and 200 ms for classifying 17 hand gestures. The number of parameters to train the proposed HDCAM architecture is 18.87 times less than its previous SOTA counterpart.
HYDRA-HGR: A Hybrid Transformer-based Architecture for Fusion of Macroscopic and Microscopic Neural Drive Information
Oct 27, 2022


Development of advance surface Electromyogram (sEMG)-based Human-Machine Interface (HMI) systems is of paramount importance to pave the way towards emergence of futuristic Cyber-Physical-Human (CPH) worlds. In this context, the main focus of recent literature was on development of different Deep Neural Network (DNN)-based architectures that perform Hand Gesture Recognition (HGR) at a macroscopic level (i.e., directly from sEMG signals). At the same time, advancements in acquisition of High-Density sEMG signals (HD-sEMG) have resulted in a surge of significant interest on sEMG decomposition techniques to extract microscopic neural drive information. However, due to complexities of sEMG decomposition and added computational overhead, HGR at microscopic level is less explored than its aforementioned DNN-based counterparts. In this regard, we propose the HYDRA-HGR framework, which is a hybrid model that simultaneously extracts a set of temporal and spatial features through its two independent Vision Transformer (ViT)-based parallel architectures (the so called Macro and Micro paths). The Macro Path is trained directly on the pre-processed HD-sEMG signals, while the Micro path is fed with the p-to-p values of the extracted Motor Unit Action Potentials (MUAPs) of each source. Extracted features at macroscopic and microscopic levels are then coupled via a Fully Connected (FC) fusion layer. We evaluate the proposed hybrid HYDRA-HGR framework through a recently released HD-sEMG dataset, and show that it significantly outperforms its stand-alone counterparts. The proposed HYDRA-HGR framework achieves average accuracy of 94.86% for the 250 ms window size, which is 5.52% and 8.22% higher than that of the Macro and Micro paths, respectively.
Multi-Content Time-Series Popularity Prediction with Multiple-Model Transformers in MEC Networks
Oct 12, 2022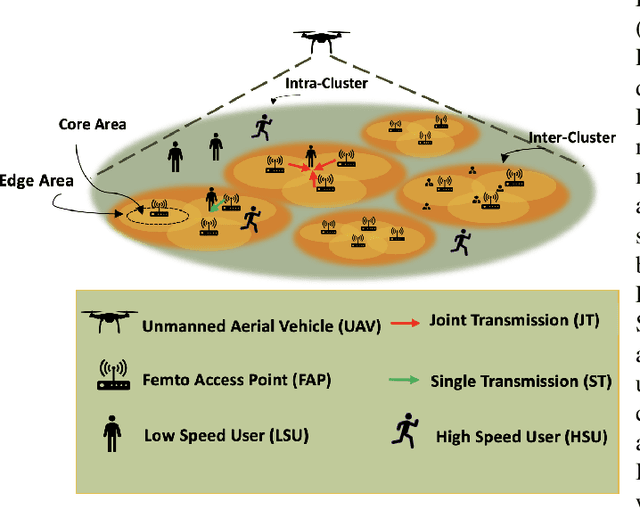
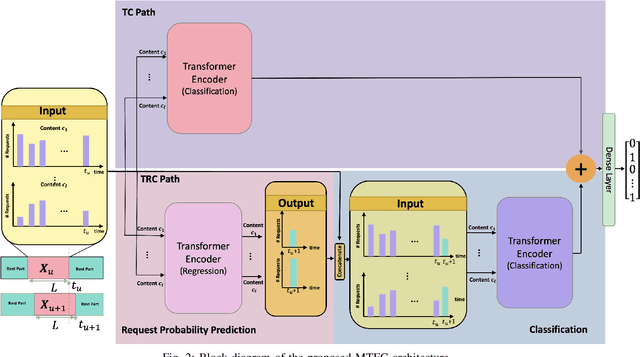
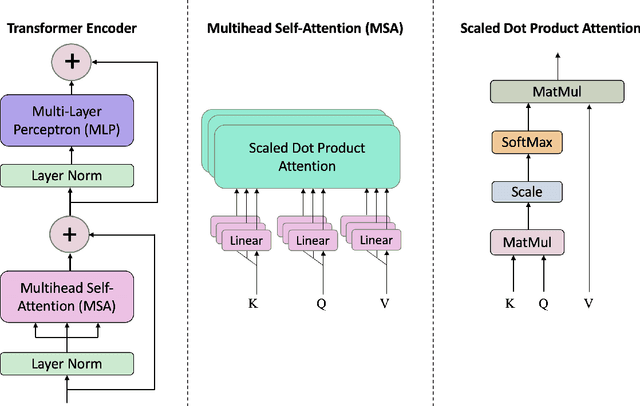
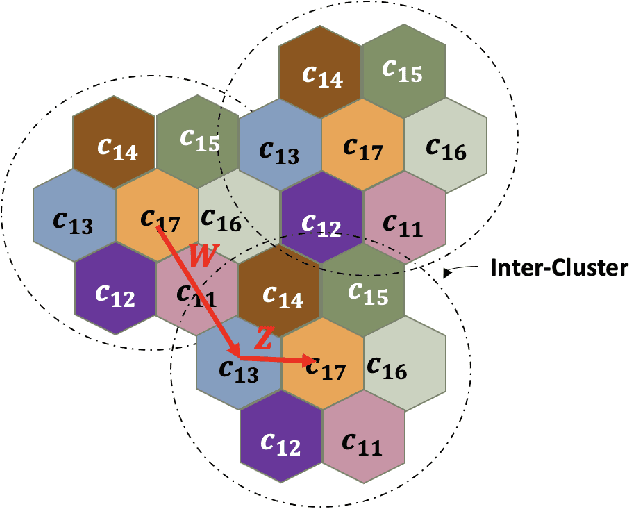
Coded/uncoded content placement in Mobile Edge Caching (MEC) has evolved as an efficient solution to meet the significant growth of global mobile data traffic by boosting the content diversity in the storage of caching nodes. To meet the dynamic nature of the historical request pattern of multimedia contents, the main focus of recent researches has been shifted to develop data-driven and real-time caching schemes. In this regard and with the assumption that users' preferences remain unchanged over a short horizon, the Top-K popular contents are identified as the output of the learning model. Most existing datadriven popularity prediction models, however, are not suitable for the coded/uncoded content placement frameworks. On the one hand, in coded/uncoded content placement, in addition to classifying contents into two groups, i.e., popular and nonpopular, the probability of content request is required to identify which content should be stored partially/completely, where this information is not provided by existing data-driven popularity prediction models. On the other hand, the assumption that users' preferences remain unchanged over a short horizon only works for content with a smooth request pattern. To tackle these challenges, we develop a Multiple-model (hybrid) Transformer-based Edge Caching (MTEC) framework with higher generalization ability, suitable for various types of content with different time-varying behavior, that can be adapted with coded/uncoded content placement frameworks. Simulation results corroborate the effectiveness of the proposed MTEC caching framework in comparison to its counterparts in terms of the cache-hit ratio, classification accuracy, and the transferred byte volume.
JUNO: Jump-Start Reinforcement Learning-based Node Selection for UWB Indoor Localization
May 06, 2022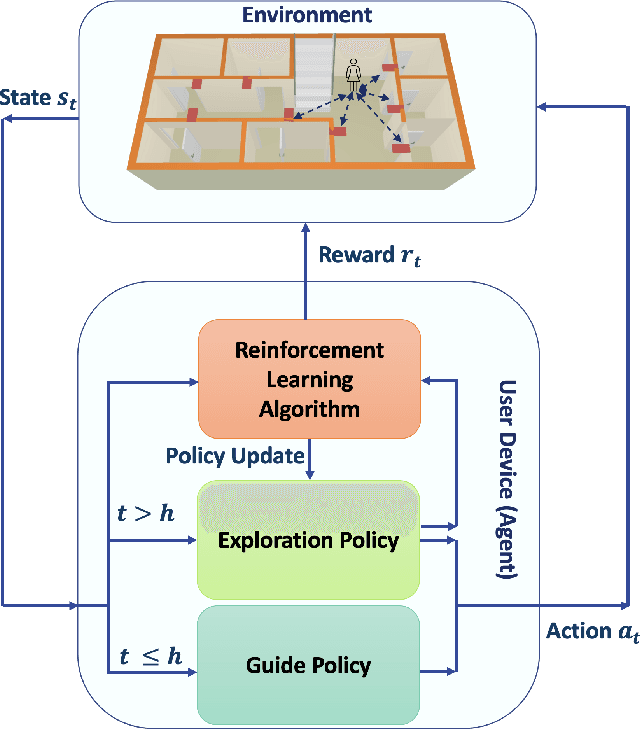
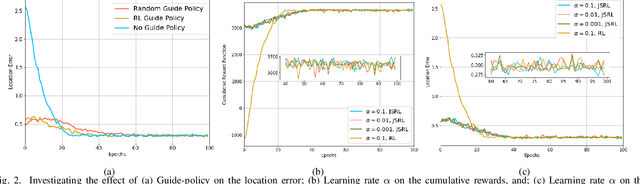
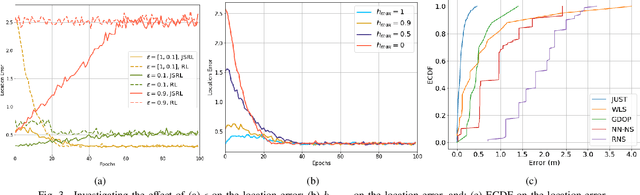
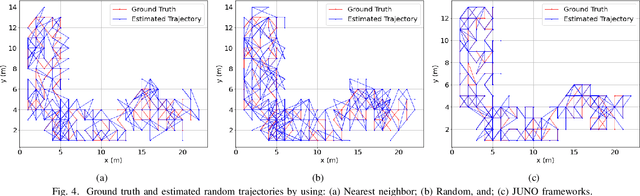
Ultra-Wideband (UWB) is one of the key technologies empowering the Internet of Thing (IoT) concept to perform reliable, energy-efficient, and highly accurate monitoring, screening, and localization in indoor environments. Performance of UWB-based localization systems, however, can significantly degrade because of Non Line of Sight (NLoS) connections between a mobile user and UWB beacons. To mitigate the destructive effects of NLoS connections, we target development of a Reinforcement Learning (RL) anchor selection framework that can efficiently cope with the dynamic nature of indoor environments. Existing RL models in this context, however, lack the ability to generalize well to be used in a new setting. Moreover, it takes a long time for the conventional RL models to reach the optimal policy. To tackle these challenges, we propose the Jump-start RL-based Uwb NOde selection (JUNO) framework, which performs real-time location predictions without relying on complex NLoS identification/mitigation methods. The effectiveness of the proposed JUNO framework is evaluated in term of the location error, where the mobile user moves randomly through an ultra-dense indoor environment with a high chance of establishing NLoS connections. Simulation results corroborate the effectiveness of the proposed framework in comparison to its state-of-the-art counterparts.
AKF-SR: Adaptive Kalman Filtering-based Successor Representation
Mar 31, 2022

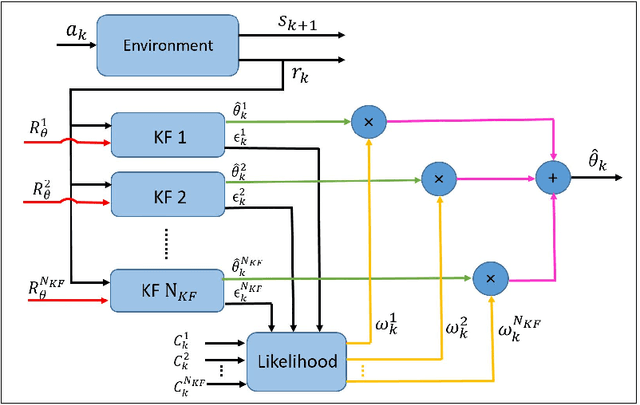
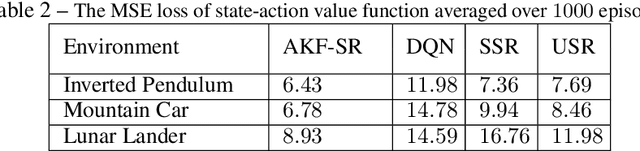
Recent studies in neuroscience suggest that Successor Representation (SR)-based models provide adaptation to changes in the goal locations or reward function faster than model-free algorithms, together with lower computational cost compared to that of model-based algorithms. However, it is not known how such representation might help animals to manage uncertainty in their decision-making. Existing methods for SR learning do not capture uncertainty about the estimated SR. In order to address this issue, the paper presents a Kalman filter-based SR framework, referred to as Adaptive Kalman Filtering-based Successor Representation (AKF-SR). First, Kalman temporal difference approach, which is a combination of the Kalman filter and the temporal difference method, is used within the AKF-SR framework to cast the SR learning procedure into a filtering problem to benefit from the uncertainty estimation of the SR, and also decreases in memory requirement and sensitivity to model's parameters in comparison to deep neural network-based algorithms. An adaptive Kalman filtering approach is then applied within the proposed AKF-SR framework in order to tune the measurement noise covariance and measurement mapping function of Kalman filter as the most important parameters affecting the filter's performance. Moreover, an active learning method that exploits the estimated uncertainty of the SR to form the behaviour policy leading to more visits to less certain values is proposed to improve the overall performance of an agent in terms of received rewards while interacting with its environment.
TraHGR: Transformer for Hand Gesture Recognition via ElectroMyography
Mar 31, 2022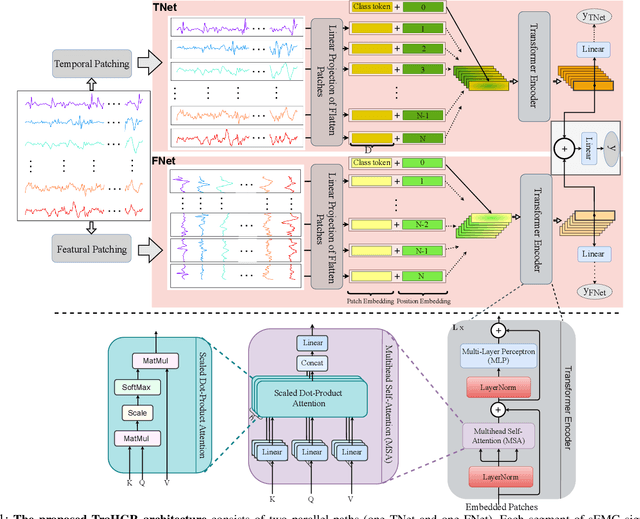
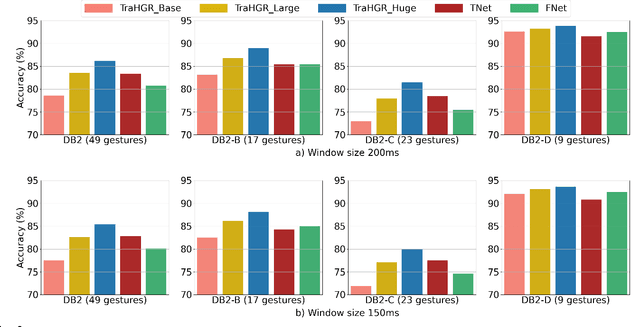
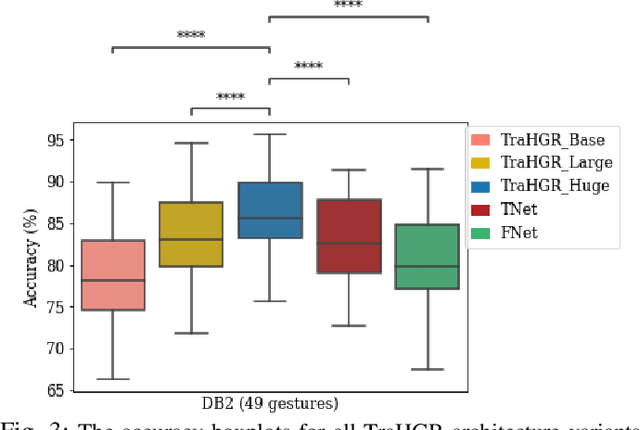
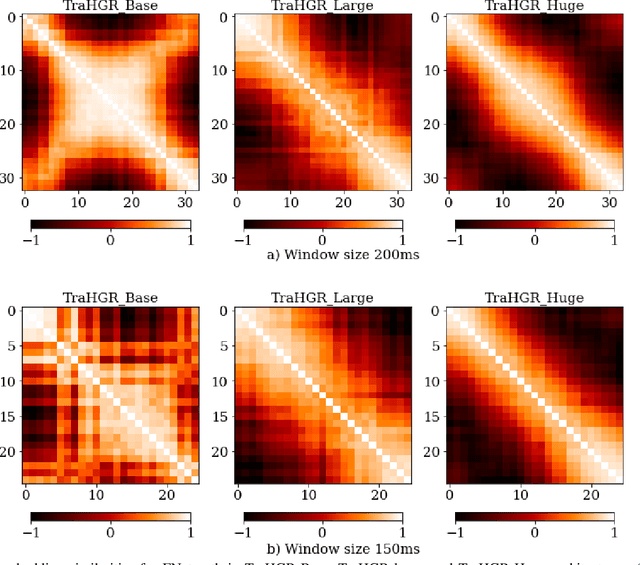
Deep learning-based Hand Gesture Recognition (HGR) via surface Electromyogram (sEMG) signals has recently shown significant potential for development of advanced myoelectric-controlled prosthesis. Existing deep learning approaches, typically, include only one model as such can hardly maintain acceptable generalization performance in changing scenarios. In this paper, we aim to address this challenge by capitalizing on the recent advances of hybrid models and transformers. In other words, we propose a hybrid framework based on the transformer architecture, which is a relatively new and revolutionizing deep learning model. The proposed hybrid architecture, referred to as the Transformer for Hand Gesture Recognition (TraHGR), consists of two parallel paths followed by a linear layer that acts as a fusion center to integrate the advantage of each module and provide robustness over different scenarios. We evaluated the proposed architecture TraHGR based on the commonly used second Ninapro dataset, referred to as the DB2. The sEMG signals in the DB2 dataset are measured in the real-life conditions from 40 healthy users, each performing 49 gestures. We have conducted extensive set of experiments to test and validate the proposed TraHGR architecture, and have compared its achievable accuracy with more than five recently proposed HGR classification algorithms over the same dataset. We have also compared the results of the proposed TraHGR architecture with each individual path and demonstrated the distinguishing power of the proposed hybrid architecture. The recognition accuracies of the proposed TraHGR architecture are 86.18%, 88.91%, 81.44%, and 93.84%, which are 2.48%, 5.12%, 8.82%, and 4.30% higher than the state-ofthe-art performance for DB2 (49 gestures), DB2-B (17 gestures), DB2-C (23 gestures), and DB2-D (9 gestures), respectively.