 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAram Galstyan
Understanding confounding effects in linguistic coordination: an information-theoretic approach
Aug 27, 2015
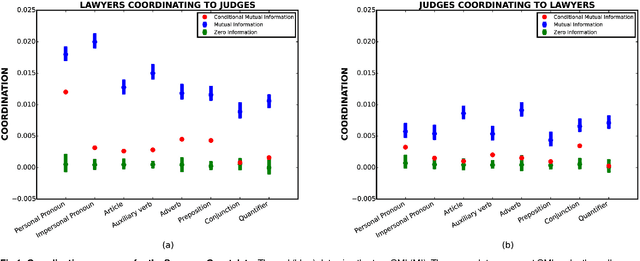
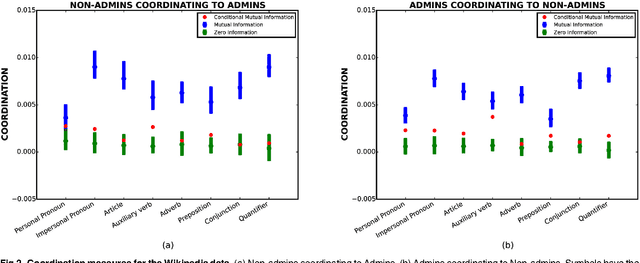
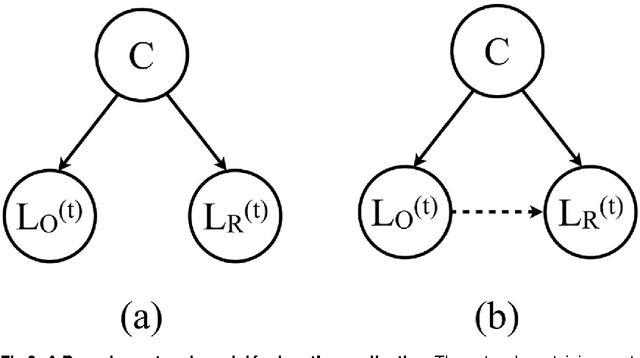
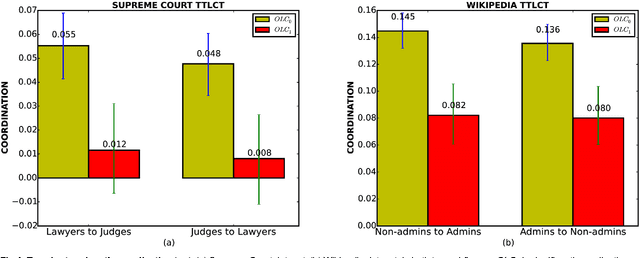
We suggest an information-theoretic approach for measuring stylistic coordination in dialogues. The proposed measure has a simple predictive interpretation and can account for various confounding factors through proper conditioning. We revisit some of the previous studies that reported strong signatures of stylistic accommodation, and find that a significant part of the observed coordination can be attributed to a simple confounding effect - length coordination. Specifically, longer utterances tend to be followed by longer responses, which gives rise to spurious correlations in the other stylistic features. We propose a test to distinguish correlations in length due to contextual factors (topic of conversation, user verbosity, etc.) and turn-by-turn coordination. We also suggest a test to identify whether stylistic coordination persists even after accounting for length coordination and contextual factors.
Efficient Estimation of Mutual Information for Strongly Dependent Variables
Mar 05, 2015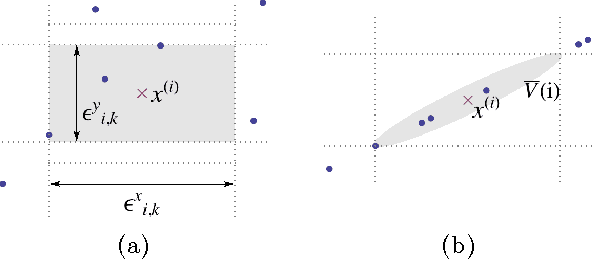
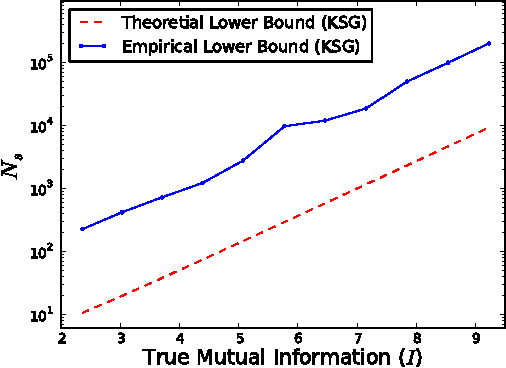
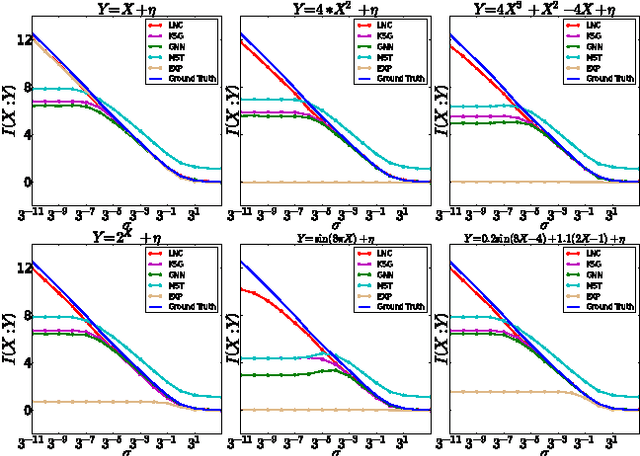
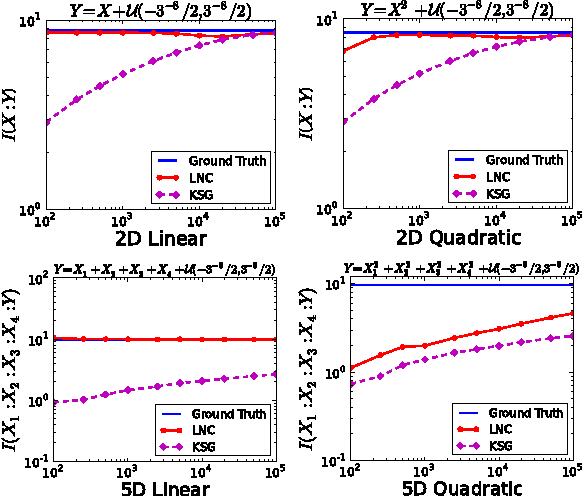
We demonstrate that a popular class of nonparametric mutual information (MI) estimators based on k-nearest-neighbor graphs requires number of samples that scales exponentially with the true MI. Consequently, accurate estimation of MI between two strongly dependent variables is possible only for prohibitively large sample size. This important yet overlooked shortcoming of the existing estimators is due to their implicit reliance on local uniformity of the underlying joint distribution. We introduce a new estimator that is robust to local non-uniformity, works well with limited data, and is able to capture relationship strengths over many orders of magnitude. We demonstrate the superior performance of the proposed estimator on both synthetic and real-world data.
Maximally Informative Hierarchical Representations of High-Dimensional Data
Jan 31, 2015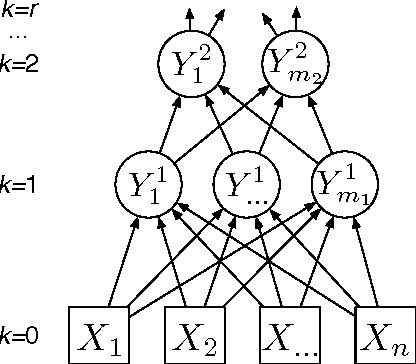
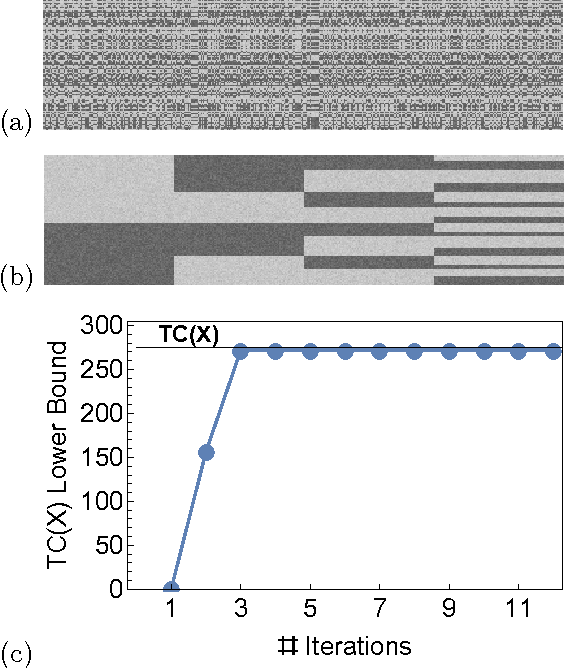
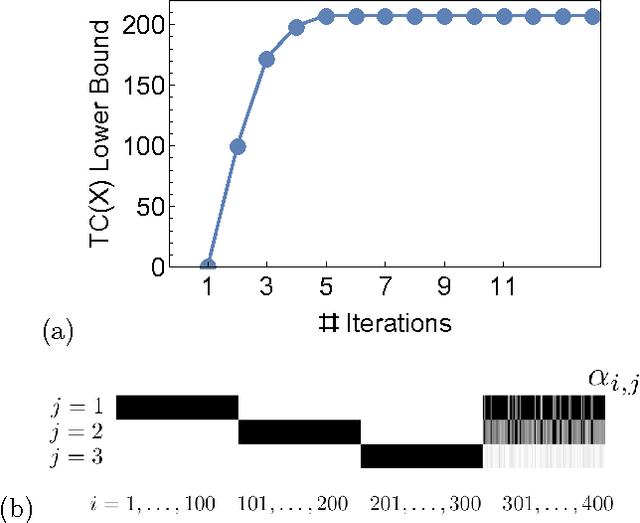
We consider a set of probabilistic functions of some input variables as a representation of the inputs. We present bounds on how informative a representation is about input data. We extend these bounds to hierarchical representations so that we can quantify the contribution of each layer towards capturing the information in the original data. The special form of these bounds leads to a simple, bottom-up optimization procedure to construct hierarchical representations that are also maximally informative about the data. This optimization has linear computational complexity and constant sample complexity in the number of variables. These results establish a new approach to unsupervised learning of deep representations that is both principled and practical. We demonstrate the usefulness of the approach on both synthetic and real-world data.
Active Inference for Binary Symmetric Hidden Markov Models
Nov 03, 2014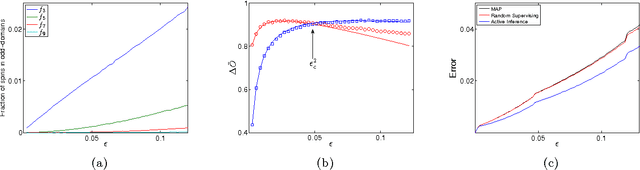
We consider active maximum a posteriori (MAP) inference problem for Hidden Markov Models (HMM), where, given an initial MAP estimate of the hidden sequence, we select to label certain states in the sequence to improve the estimation accuracy of the remaining states. We develop an analytical approach to this problem for the case of binary symmetric HMMs, and obtain a closed form solution that relates the expected error reduction to model parameters under the specified active inference scheme. We then use this solution to determine most optimal active inference scheme in terms of error reduction, and examine the relation of those schemes to heuristic principles of uncertainty reduction and solution unicity.
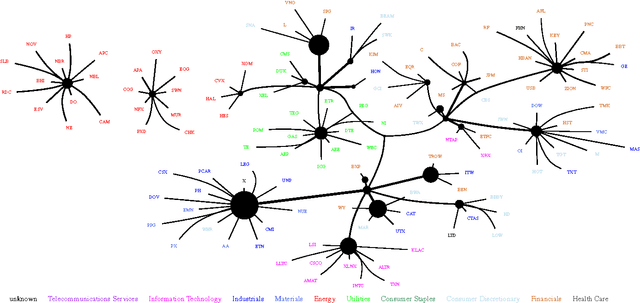
Discovering Structure in High-Dimensional Data Through Correlation Explanation
Oct 31, 2014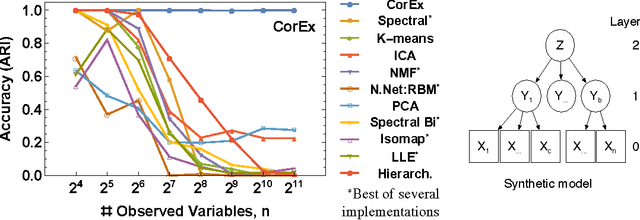

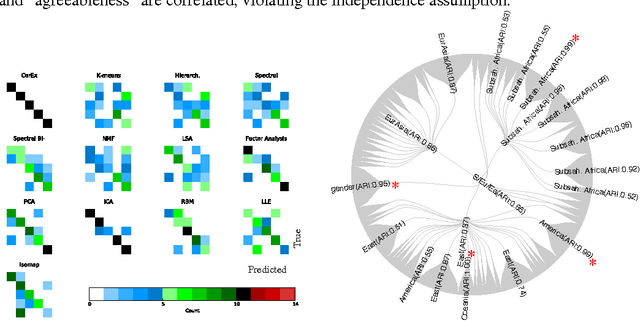
We introduce a method to learn a hierarchy of successively more abstract representations of complex data based on optimizing an information-theoretic objective. Intuitively, the optimization searches for a set of latent factors that best explain the correlations in the data as measured by multivariate mutual information. The method is unsupervised, requires no model assumptions, and scales linearly with the number of variables which makes it an attractive approach for very high dimensional systems. We demonstrate that Correlation Explanation (CorEx) automatically discovers meaningful structure for data from diverse sources including personality tests, DNA, and human language.
Tripartite Graph Clustering for Dynamic Sentiment Analysis on Social Media
Jun 12, 2014
The growing popularity of social media (e.g, Twitter) allows users to easily share information with each other and influence others by expressing their own sentiments on various subjects. In this work, we propose an unsupervised \emph{tri-clustering} framework, which analyzes both user-level and tweet-level sentiments through co-clustering of a tripartite graph. A compelling feature of the proposed framework is that the quality of sentiment clustering of tweets, users, and features can be mutually improved by joint clustering. We further investigate the evolution of user-level sentiments and latent feature vectors in an online framework and devise an efficient online algorithm to sequentially update the clustering of tweets, users and features with newly arrived data. The online framework not only provides better quality of both dynamic user-level and tweet-level sentiment analysis, but also improves the computational and storage efficiency. We verified the effectiveness and efficiency of the proposed approaches on the November 2012 California ballot Twitter data.
Latent Self-Exciting Point Process Model for Spatial-Temporal Networks
Apr 30, 2014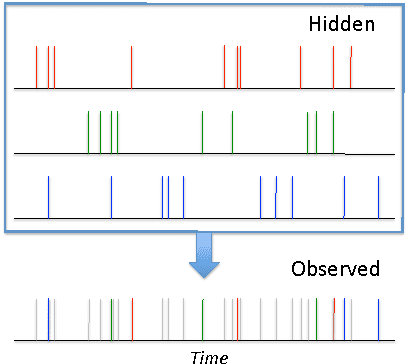

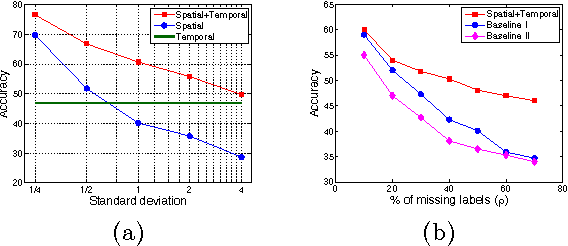

We propose a latent self-exciting point process model that describes geographically distributed interactions between pairs of entities. In contrast to most existing approaches that assume fully observable interactions, here we consider a scenario where certain interaction events lack information about participants. Instead, this information needs to be inferred from the available observations. We develop an efficient approximate algorithm based on variational expectation-maximization to infer unknown participants in an event given the location and the time of the event. We validate the model on synthetic as well as real-world data, and obtain very promising results on the identity-inference task. We also use our model to predict the timing and participants of future events, and demonstrate that it compares favorably with baseline approaches.
* 20 pages, 6 figures (v3); 11 pages, 6 figures (v2); previous version appeared in the 9th Bayesian Modeling Applications Workshop, UAI'12
Demystifying Information-Theoretic Clustering
Feb 05, 2014
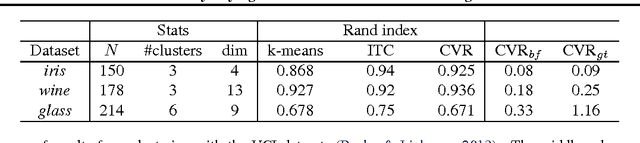
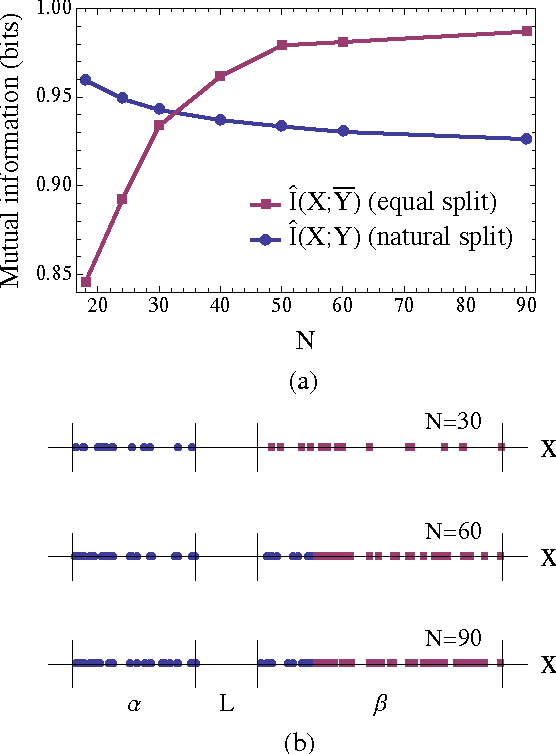
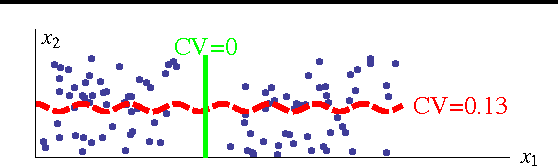
We propose a novel method for clustering data which is grounded in information-theoretic principles and requires no parametric assumptions. Previous attempts to use information theory to define clusters in an assumption-free way are based on maximizing mutual information between data and cluster labels. We demonstrate that this intuition suffers from a fundamental conceptual flaw that causes clustering performance to deteriorate as the amount of data increases. Instead, we return to the axiomatic foundations of information theory to define a meaningful clustering measure based on the notion of consistency under coarse-graining for finite data.
Comparative Analysis of Viterbi Training and Maximum Likelihood Estimation for HMMs
Dec 16, 2013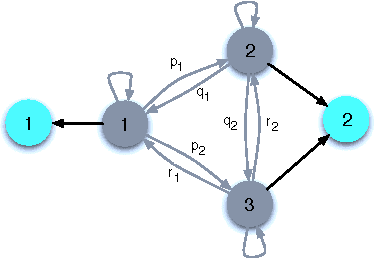
We present an asymptotic analysis of Viterbi Training (VT) and contrast it with a more conventional Maximum Likelihood (ML) approach to parameter estimation in Hidden Markov Models. While ML estimator works by (locally) maximizing the likelihood of the observed data, VT seeks to maximize the probability of the most likely hidden state sequence. We develop an analytical framework based on a generating function formalism and illustrate it on an exactly solvable model of HMM with one unambiguous symbol. For this particular model the ML objective function is continuously degenerate. VT objective, in contrast, is shown to have only finite degeneracy. Furthermore, VT converges faster and results in sparser (simpler) models, thus realizing an automatic Occam's razor for HMM learning. For more general scenario VT can be worse compared to ML but still capable of correctly recovering most of the parameters.
Phase Transitions in Community Detection: A Solvable Toy Model
Dec 02, 2013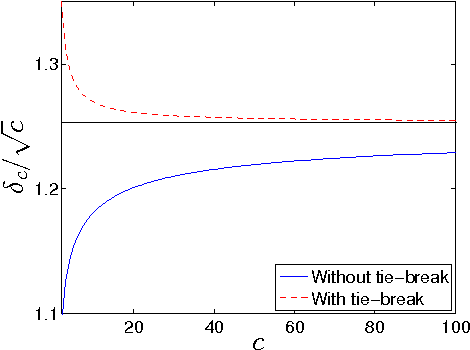
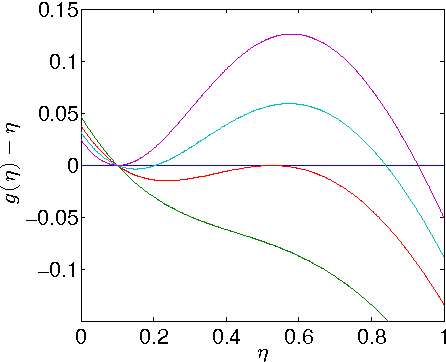
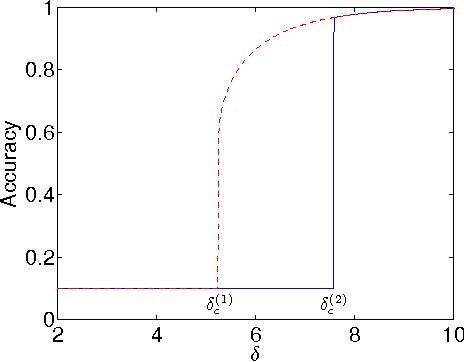
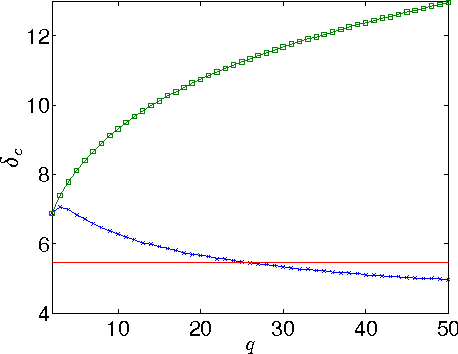
Recently, it was shown that there is a phase transition in the community detection problem. This transition was first computed using the cavity method, and has been proved rigorously in the case of $q=2$ groups. However, analytic calculations using the cavity method are challenging since they require us to understand probability distributions of messages. We study analogous transitions in so-called "zero-temperature inference" model, where this distribution is supported only on the most-likely messages. Furthermore, whenever several messages are equally likely, we break the tie by choosing among them with equal probability. While the resulting analysis does not give the correct values of the thresholds, it does reproduce some of the qualitative features of the system. It predicts a first-order detectability transition whenever $q > 2$, while the finite-temperature cavity method shows that this is the case only when $q > 4$. It also has a regime analogous to the "hard but detectable" phase, where the community structure can be partially recovered, but only when the initial messages are sufficiently accurate. Finally, we study a semisupervised setting where we are given the correct labels for a fraction $\rho$ of the nodes. For $q > 2$, we find a regime where the accuracy jumps discontinuously at a critical value of $\rho$.