 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtriever: End-to-End Differentiable Protein Homology Search for Fitness Prediction
Jun 10, 2025Retrieving homologous protein sequences is essential for a broad range of protein modeling tasks such as fitness prediction, protein design, structure modeling, and protein-protein interactions. Traditional workflows have relied on a two-step process: first retrieving homologs via Multiple Sequence Alignments (MSA), then training models on one or more of these alignments. However, MSA-based retrieval is computationally expensive, struggles with highly divergent sequences or complex insertions & deletions patterns, and operates independently of the downstream modeling objective. We introduce Protriever, an end-to-end differentiable framework that learns to retrieve relevant homologs while simultaneously training for the target task. When applied to protein fitness prediction, Protriever achieves state-of-the-art performance compared to sequence-based models that rely on MSA-based homolog retrieval, while being two orders of magnitude faster through efficient vector search. Protriever is both architecture- and task-agnostic, and can flexibly adapt to different retrieval strategies and protein databases at inference time -- offering a scalable alternative to alignment-centric approaches.
On the Performance Evaluation of Action Recognition Models on Transcoded Low Quality Videos
Apr 19, 2022

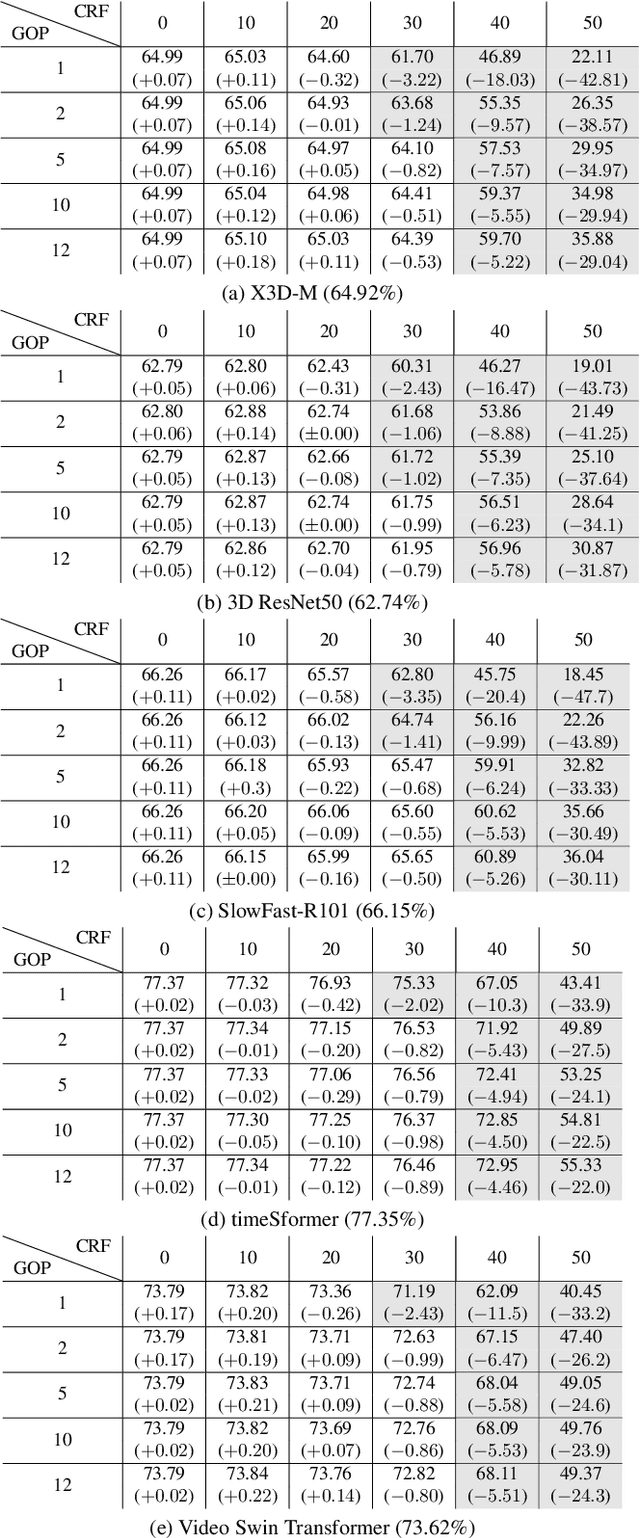
In the design of action recognition models, the quality of videos in the dataset is an important issue, however the trade-off between the quality and performance is often ignored. In general, action recognition models are trained and tested on high-quality videos, but in actual situations where action recognition models are deployed, sometimes it might not be assumed that the input videos are of high quality. In this study, we report qualitative evaluations of action recognition models for the quality degradation associated with transcoding by JPEG and H.264/AVC. Experimental results are shown for evaluating the performance of pre-trained models on the transcoded validation videos of Kinetics400. The models are also trained on the transcoded training videos. From these results, we quantitatively show the degree of degradation of the model performance with respect to the degradation of the video quality.