 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in the Evidence? Reproducing Document Position and Context Size Effects in RAG
May 27, 2026Retrieval-Augmented Generation (RAG) systems rely on retrieved documents being concatenated into a model's input context, making both document ordering and context size critical yet controversial design choices. Prior work reports position-based effects such as lost in the middle and related long-context phenomena. However, empirical findings remain inconsistent and hard to reproduce across models, datasets, and evaluation protocols. In this paper, we present a systematic reproducibility study that revisits these claims and examines how they evolve with contemporary LLMs under a controlled evaluation framework. We first show that topic sampling is a major source of variance: small topic sets can mask or exaggerate ordering effects. Based on repeated subset sampling across multiple topic budgets, we provide a practical calibration procedure that identifies topic counts yielding stable trends at feasible cost. Using these fixed topic sets, we then reproduce and extend results on position sensitivity, re-evaluating lost in the middle and positional biases in modern LLMs. Then, we also study a more realistic RAG scenario in which relevance is mediated by a retriever rather than oracle access to ground-truth documents. In this setting, we re-examine a recent industry study and identify discrepancies to evaluation choices such as limited topic coverage and reliance on LLM-based judges. Finally, we conduct an analysis of how retrieval order and context size affect downstream LLM performance under imperfect retrieval. Our results demonstrate that both factors interact strongly with retrieval quality and model choice, and that conclusions drawn from idealised setups do not always transfer to real-world RAG pipelines. We release all code and configurations to support reproducibility and future work on robust RAG evaluation.
Learning Evidence of Depression Symptoms via Prompt Induction
Apr 27, 2026Depression places substantial pressure on mental health services, and many people describe their experiences outside clinical settings in high-volume user-generated text (e.g., online forums and social media). Automatically identifying clinical symptom evidence in such text can therefore complement limited clinical capacity and scale to large populations. We address this need through sentence-level classification of 21 depression symptoms from the BDI-II questionnaire, using BDI-Sen, a dataset annotated for symptom relevance. This task is fine-grained and highly imbalanced, and we find that common LLM approaches (zero-shot, in-context learning, and fine-tuning) struggle to apply consistent relevance criteria for most symptoms. We propose Symptom Induction (SI), a novel approach which compresses labeled examples into short, interpretable guidelines that specify what counts as evidence for each symptom and uses these guidelines to condition classification. Across four LLM families and eight models, SI achieves the best overall weighted F1 on BDI-Sen, with especially large gains for infrequent symptoms. Cross-domain evaluation on an external dataset further shows that induced guidelines generalize across other diseases shared symptomatology (bipolar and eating disorders).
Eval4Sim: An Evaluation Framework for Persona Simulation
Mar 03, 2026Large Language Model (LLM) personas with explicit specifications of attributes, background, and behavioural tendencies are increasingly used to simulate human conversations for tasks such as user modeling, social reasoning, and behavioural analysis. Ensuring that persona-grounded simulations faithfully reflect human conversational behaviour is therefore critical. However, current evaluation practices largely rely on LLM-as-a-judge approaches, offering limited grounding in observable human behavior and producing opaque scalar scores. We address this gap by proposing Eval4Sim, an evaluation framework that measures how closely simulated conversations align with human conversational patterns across three complementary dimensions. Adherence captures how effectively persona backgrounds are implicitly encoded in generated utterances, assessed via dense retrieval with speaker-aware representations. Consistency evaluates whether a persona maintains a distinguishable identity across conversations, computed through authorship verification. Naturalness reflects whether conversations exhibit human-like flow rather than overly rigid or optimized structure, quantified through distributions derived from dialogue-focused Natural Language Inference. Unlike absolute or optimization-oriented metrics, Eval4Sim uses a human conversational corpus (i.e., PersonaChat) as a reference baseline and penalizes deviations in both directions, distinguishing insufficient persona encoding from over-optimized, unnatural behaviour. Although demonstrated on PersonaChat, the applicability of Eval4Sim extends to any conversational corpus containing speaker-level annotations.
TalkDep: Clinically Grounded LLM Personas for Conversation-Centric Depression Screening
Aug 06, 2025
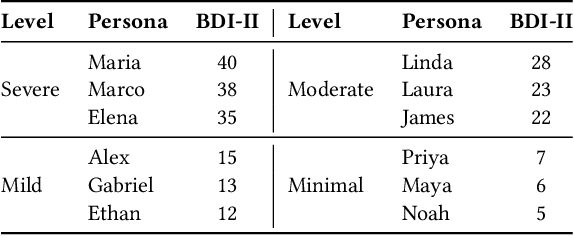


The increasing demand for mental health services has outpaced the availability of real training data to develop clinical professionals, leading to limited support for the diagnosis of depression. This shortage has motivated the development of simulated or virtual patients to assist in training and evaluation, but existing approaches often fail to generate clinically valid, natural, and diverse symptom presentations. In this work, we embrace the recent advanced language models as the backbone and propose a novel clinician-in-the-loop patient simulation pipeline, TalkDep, with access to diversified patient profiles to develop simulated patients. By conditioning the model on psychiatric diagnostic criteria, symptom severity scales, and contextual factors, our goal is to create authentic patient responses that can better support diagnostic model training and evaluation. We verify the reliability of these simulated patients with thorough assessments conducted by clinical professionals. The availability of validated simulated patients offers a scalable and adaptable resource for improving the robustness and generalisability of automatic depression diagnosis systems.