 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of Explainable AI Techniques with Large Language Models for Enhanced Interpretability for Sentiment Analysis
Mar 15, 2025Interpretability remains a key difficulty in sentiment analysis with Large Language Models (LLMs), particularly in high-stakes applications where it is crucial to comprehend the rationale behind forecasts. This research addressed this by introducing a technique that applies SHAP (Shapley Additive Explanations) by breaking down LLMs into components such as embedding layer,encoder,decoder and attention layer to provide a layer-by-layer knowledge of sentiment prediction. The approach offers a clearer overview of how model interpret and categorise sentiment by breaking down LLMs into these parts. The method is evaluated using the Stanford Sentiment Treebank (SST-2) dataset, which shows how different sentences affect different layers. The effectiveness of layer-wise SHAP analysis in clarifying sentiment-specific token attributions is demonstrated by experimental evaluations, which provide a notable enhancement over current whole-model explainability techniques. These results highlight how the suggested approach could improve the reliability and transparency of LLM-based sentiment analysis in crucial applications.
Extending Memory for Language Modelling
May 19, 2023



Breakthroughs in deep learning and memory networks have made major advances in natural language understanding. Language is sequential and information carried through the sequence can be captured through memory networks. Learning the sequence is one of the key aspects in learning the language. However, memory networks are not capable of holding infinitely long sequences in their memories and are limited by various constraints such as the vanishing or exploding gradient problem. Therefore, natural language understanding models are affected when presented with long sequential text. We introduce Long Term Memory network (LTM) to learn from infinitely long sequences. LTM gives priority to the current inputs to allow it to have a high impact. Language modeling is an important factor in natural language understanding. LTM was tested in language modeling, which requires long term memory. LTM is tested on Penn Tree bank dataset, Google Billion Word dataset and WikiText-2 dataset. We compare LTM with other language models which require long term memory.
Predicting Electricity Consumption using Deep Recurrent Neural Networks
Sep 18, 2019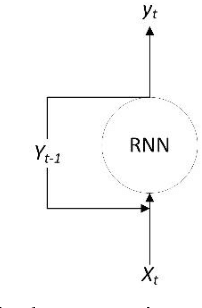
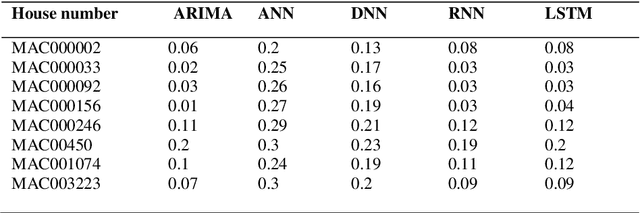
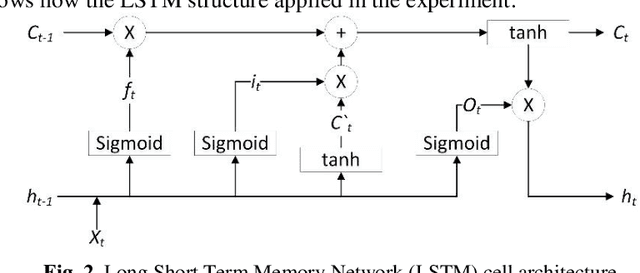
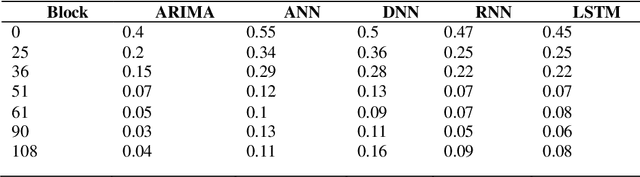
Electricity consumption has increased exponentially during the past few decades. This increase is heavily burdening the electricity distributors. Therefore, predicting the future demand for electricity consumption will provide an upper hand to the electricity distributor. Predicting electricity consumption requires many parameters. The paper presents two approaches with one using a Recurrent Neural Network (RNN) and another one using a Long Short Term Memory (LSTM) network, which only considers the previous electricity consumption to predict the future electricity consumption. These models were tested on the publicly available London smart meter dataset. To assess the applicability of the RNN and the LSTM network to predict electricity consumption, they were tested to predict for an individual house and a block of houses for a given time period. The predictions were done for daily, trimester and 13 months, which covers short term, mid-term and long term prediction. Both the RNN and the LSTM network have achieved an average Root Mean Square error of 0.1.
Language Modeling through Long Term Memory Network
Apr 18, 2019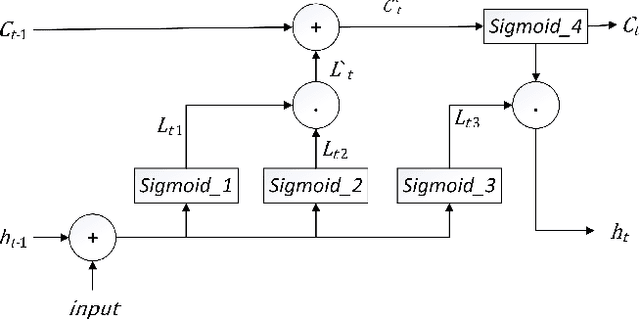
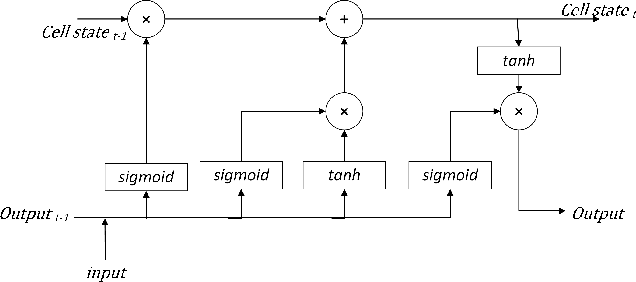
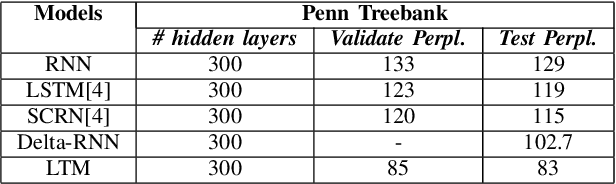
Recurrent Neural Networks (RNN), Long Short-Term Memory Networks (LSTM), and Memory Networks which contain memory are popularly used to learn patterns in sequential data. Sequential data has long sequences that hold relationships. RNN can handle long sequences but suffers from the vanishing and exploding gradient problems. While LSTM and other memory networks address this problem, they are not capable of handling long sequences (50 or more data points long sequence patterns). Language modelling requiring learning from longer sequences are affected by the need for more information in memory. This paper introduces Long Term Memory network (LTM), which can tackle the exploding and vanishing gradient problems and handles long sequences without forgetting. LTM is designed to scale data in the memory and gives a higher weight to the input in the sequence. LTM avoid overfitting by scaling the cell state after achieving the optimal results. The LTM is tested on Penn treebank dataset, and Text8 dataset and LTM achieves test perplexities of 83 and 82 respectively. 650 LTM cells achieved a test perplexity of 67 for Penn treebank, and 600 cells achieved a test perplexity of 77 for Text8. LTM achieves state of the art results by only using ten hidden LTM cells for both datasets.
Enhancing Semantic Word Representations by Embedding Deeper Word Relationships
Jan 22, 2019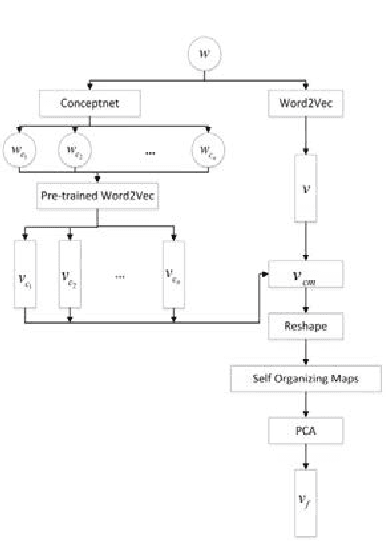



Word representations are created using analogy context-based statistics and lexical relations on words. Word representations are inputs for the learning models in Natural Language Understanding (NLU) tasks. However, to understand language, knowing only the context is not sufficient. Reading between the lines is a key component of NLU. Embedding deeper word relationships which are not represented in the context enhances the word representation. This paper presents a word embedding which combines an analogy, context-based statistics using Word2Vec, and deeper word relationships using Conceptnet, to create an expanded word representation. In order to fine-tune the word representation, Self-Organizing Map is used to optimize it. The proposed word representation is compared with semantic word representations using Simlex 999. Furthermore, the use of 3D visual representations has shown to be capable of representing the similarity and association between words. The proposed word representation shows a Spearman correlation score of 0.886 and provided the best results when compared to the current state-of-the-art methods, and exceed the human performance of 0.78.