 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMU: Selective Influence Machine Unlearning
Oct 09, 2025The undesired memorization of sensitive information by Large Language Models (LLMs) has emphasized the need for safety mechanisms that can regulate model behavior. This has led to the development of machine unlearning techniques that enable models to precisely forget sensitive and unwanted information. For machine unlearning, first-order and second-order optimizer-based methods have shown significant progress in enabling LLMs to forget targeted information. However, in doing so, these approaches often compromise the model's original capabilities, resulting in unlearned models that struggle to retain their prior knowledge and overall utility. To address this, we propose Selective Influence Machine Unlearning (SIMU), a two-step framework that enhances second-order optimizer-based unlearning by selectively updating only the critical neurons responsible for encoding the forget-set. By constraining updates to these targeted neurons, SIMU achieves comparable unlearning efficacy while substantially outperforming current methods in retaining the model's original knowledge.
Cluster Based Deep Contextual Reinforcement Learning for top-k Recommendations
Nov 29, 2020

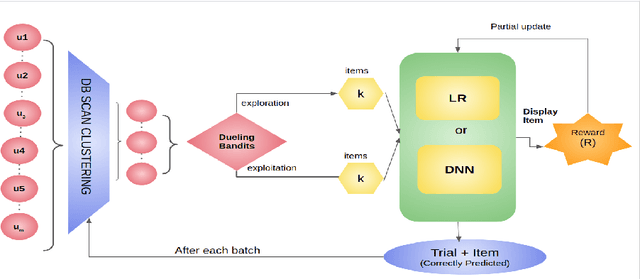
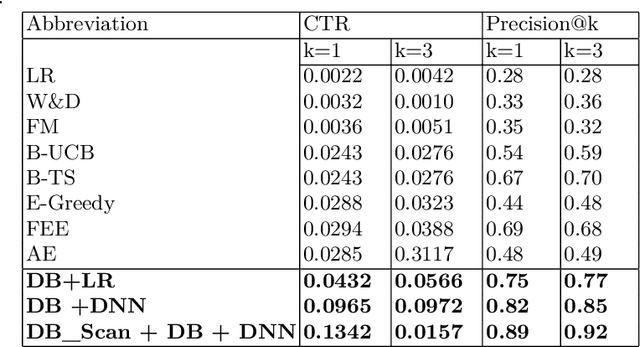
Rapid advancements in the E-commerce sector over the last few decades have led to an imminent need for personalised, efficient and dynamic recommendation systems. To sufficiently cater to this need, we propose a novel method for generating top-k recommendations by creating an ensemble of clustering with reinforcement learning. We have incorporated DB Scan clustering to tackle vast item space, hence in-creasing the efficiency multi-fold. Moreover, by using deep contextual reinforcement learning, our proposed work leverages the user features to its full potential. With partial updates and batch updates, the model learns user patterns continuously. The Duelling Bandit based exploration provides robust exploration as compared to the state-of-art strategies due to its adaptive nature. Detailed experiments conducted on a public dataset verify our claims about the efficiency of our technique as com-pared to existing techniques.