 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Text Mining with Sparse Generative Models
Feb 07, 2016


The information age has brought a deluge of data. Much of this is in text form, insurmountable in scope for humans and incomprehensible in structure for computers. Text mining is an expanding field of research that seeks to utilize the information contained in vast document collections. General data mining methods based on machine learning face challenges with the scale of text data, posing a need for scalable text mining methods. This thesis proposes a solution to scalable text mining: generative models combined with sparse computation. A unifying formalization for generative text models is defined, bringing together research traditions that have used formally equivalent models, but ignored parallel developments. This framework allows the use of methods developed in different processing tasks such as retrieval and classification, yielding effective solutions across different text mining tasks. Sparse computation using inverted indices is proposed for inference on probabilistic models. This reduces the computational complexity of the common text mining operations according to sparsity, yielding probabilistic models with the scalability of modern search engines. The proposed combination provides sparse generative models: a solution for text mining that is general, effective, and scalable. Extensive experimentation on text classification and ranked retrieval datasets are conducted, showing that the proposed solution matches or outperforms the leading task-specific methods in effectiveness, with a order of magnitude decrease in classification times for Wikipedia article categorization with a million classes. The developed methods were further applied in two 2014 Kaggle data mining prize competitions with over a hundred competing teams, earning first and second places.
Kaggle LSHTC4 Winning Solution
May 09, 2014


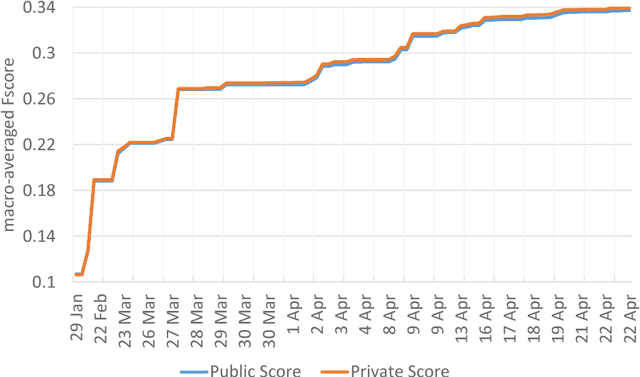
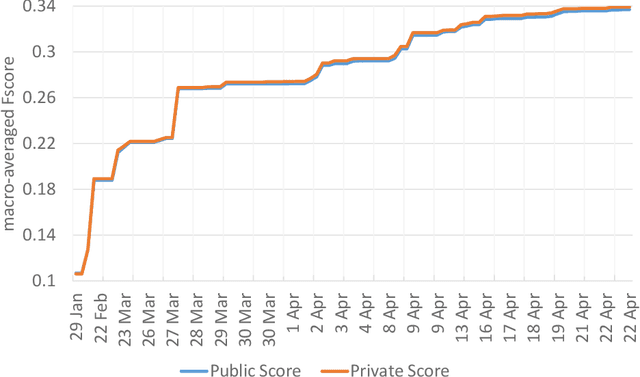
Our winning submission to the 2014 Kaggle competition for Large Scale Hierarchical Text Classification (LSHTC) consists mostly of an ensemble of sparse generative models extending Multinomial Naive Bayes. The base-classifiers consist of hierarchically smoothed models combining document, label, and hierarchy level Multinomials, with feature pre-processing using variants of TF-IDF and BM25. Additional diversification is introduced by different types of folds and random search optimization for different measures. The ensemble algorithm optimizes macroFscore by predicting the documents for each label, instead of the usual prediction of labels per document. Scores for documents are predicted by weighted voting of base-classifier outputs with a variant of Feature-Weighted Linear Stacking. The number of documents per label is chosen using label priors and thresholding of vote scores. This document describes the models and software used to build our solution. Reproducing the results for our solution can be done by running the scripts included in the Kaggle package. A package omitting precomputed result files is also distributed. All code is open source, released under GNU GPL 2.0, and GPL 3.0 for Weka and Meka dependencies.