 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhispered-to-voiced Alaryngeal Speech Conversion with Generative Adversarial Networks
Nov 05, 2018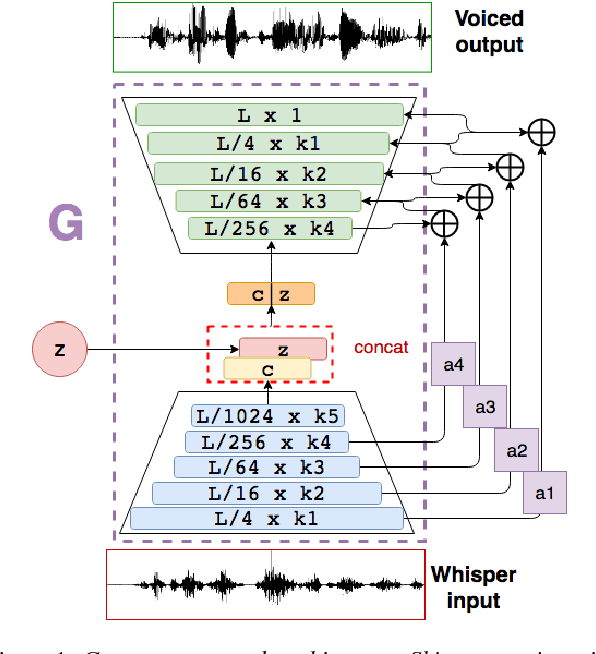


Most methods of voice restoration for patients suffering from aphonia either produce whispered or monotone speech. Apart from intelligibility, this type of speech lacks expressiveness and naturalness due to the absence of pitch (whispered speech) or artificial generation of it (monotone speech). Existing techniques to restore prosodic information typically combine a vocoder, which parameterises the speech signal, with machine learning techniques that predict prosodic information. In contrast, this paper describes an end-to-end neural approach for estimating a fully-voiced speech waveform from whispered alaryngeal speech. By adapting our previous work in speech enhancement with generative adversarial networks, we develop a speaker-dependent model to perform whispered-to-voiced speech conversion. Preliminary qualitative results show effectiveness in re-generating voiced speech, with the creation of realistic pitch contours.
Language and Noise Transfer in Speech Enhancement Generative Adversarial Network
Dec 18, 2017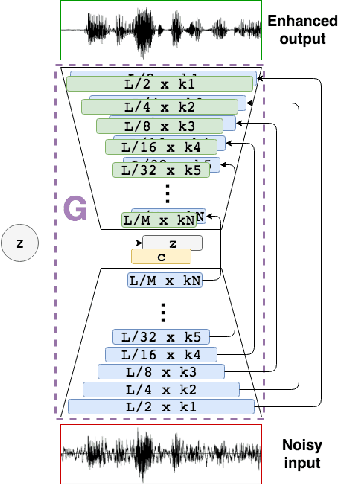
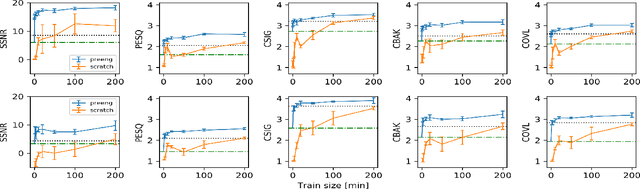
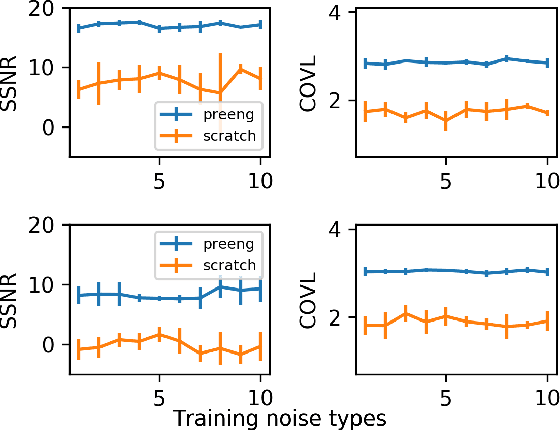
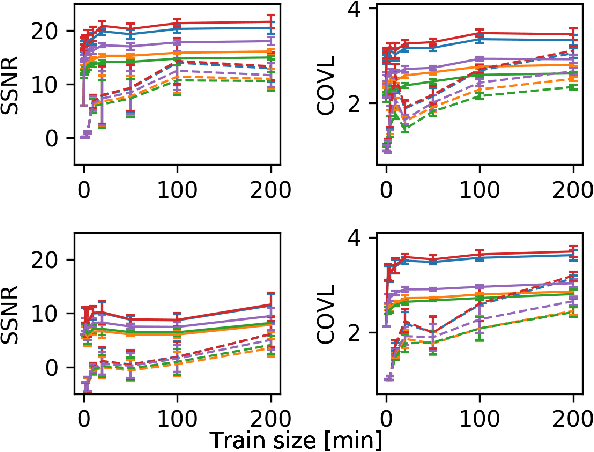
Speech enhancement deep learning systems usually require large amounts of training data to operate in broad conditions or real applications. This makes the adaptability of those systems into new, low resource environments an important topic. In this work, we present the results of adapting a speech enhancement generative adversarial network by finetuning the generator with small amounts of data. We investigate the minimum requirements to obtain a stable behavior in terms of several objective metrics in two very different languages: Catalan and Korean. We also study the variability of test performance to unseen noise as a function of the amount of different types of noise available for training. Results show that adapting a pre-trained English model with 10 min of data already achieves a comparable performance to having two orders of magnitude more data. They also demonstrate the relative stability in test performance with respect to the number of training noise types.
SEGAN: Speech Enhancement Generative Adversarial Network
Jun 09, 2017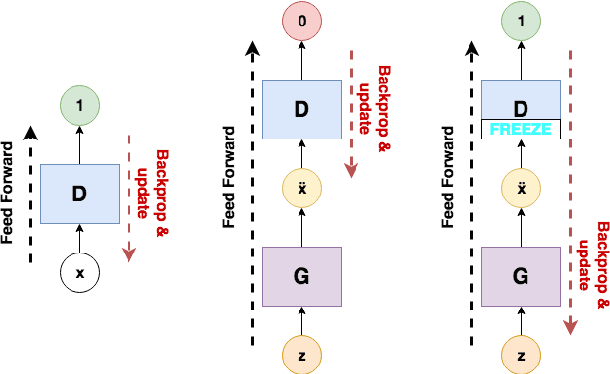
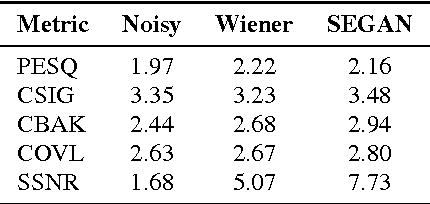
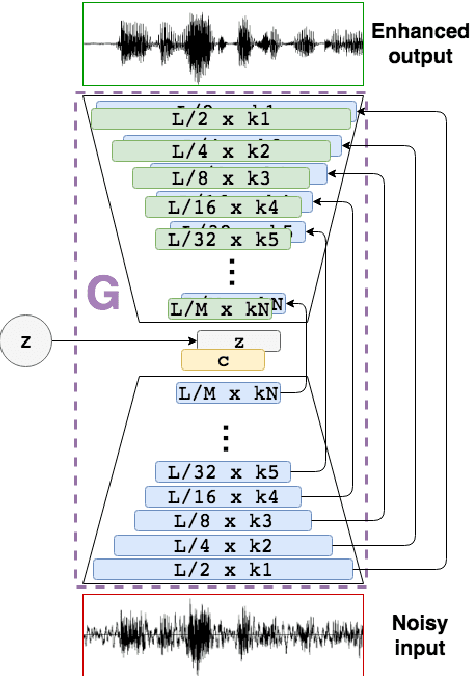
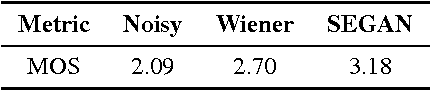
Current speech enhancement techniques operate on the spectral domain and/or exploit some higher-level feature. The majority of them tackle a limited number of noise conditions and rely on first-order statistics. To circumvent these issues, deep networks are being increasingly used, thanks to their ability to learn complex functions from large example sets. In this work, we propose the use of generative adversarial networks for speech enhancement. In contrast to current techniques, we operate at the waveform level, training the model end-to-end, and incorporate 28 speakers and 40 different noise conditions into the same model, such that model parameters are shared across them. We evaluate the proposed model using an independent, unseen test set with two speakers and 20 alternative noise conditions. The enhanced samples confirm the viability of the proposed model, and both objective and subjective evaluations confirm the effectiveness of it. With that, we open the exploration of generative architectures for speech enhancement, which may progressively incorporate further speech-centric design choices to improve their performance.