 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Robustness of Predictive Uncertainty Estimation: Are Dirichlet-based Models Reliable?
Oct 28, 2020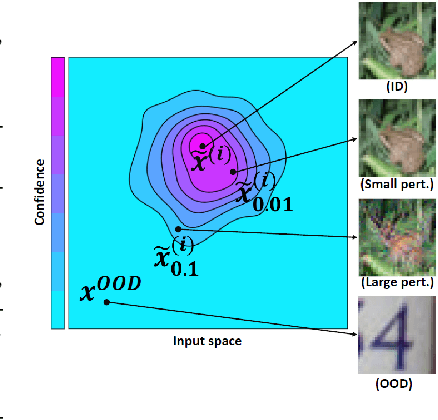


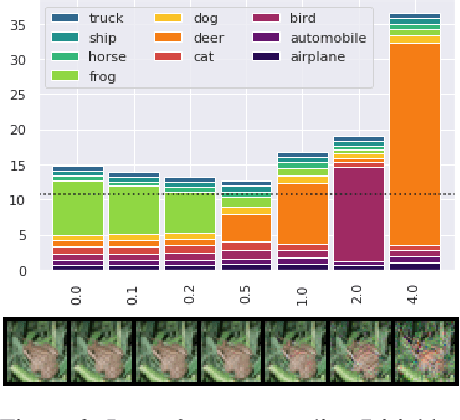
Robustness to adversarial perturbations and accurate uncertainty estimation are crucial for reliable application of deep learning in real world settings. Dirichlet-based uncertainty (DBU) models are a family of models that predict the parameters of a Dirichlet distribution (instead of a categorical one) and promise to signal when not to trust their predictions. Untrustworthy predictions are obtained on unknown or ambiguous samples and marked with a high uncertainty by the models. In this work, we show that DBU models with standard training are not robust w.r.t. three important tasks in the field of uncertainty estimation. In particular, we evaluate how useful the uncertainty estimates are to (1) indicate correctly classified samples, and (2) to detect adversarial examples that try to fool classification. We further evaluate the reliability of DBU models on the task of (3) distinguishing between in-distribution (ID) and out-of-distribution (OOD) data. To this end, we present the first study of certifiable robustness for DBU models. Furthermore, we propose novel uncertainty attacks that fool models into assigning high confidence to OOD data and low confidence to ID data, respectively. Based on our results, we explore the first approaches to make DBU models more robust. We use adversarial training procedures based on label attacks, uncertainty attacks, or random noise and demonstrate how they affect robustness of DBU models on ID data and OOD data.
Reachable Sets of Classifiers & Regression Models: (Non-)Robustness Analysis and Robust Training
Jul 28, 2020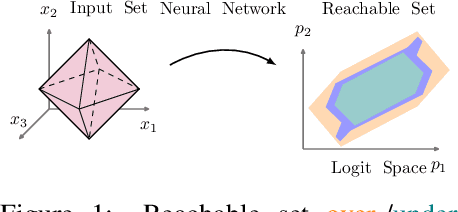
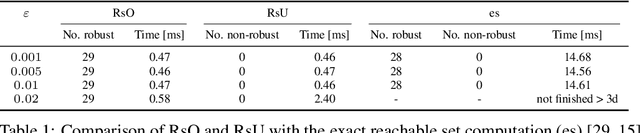

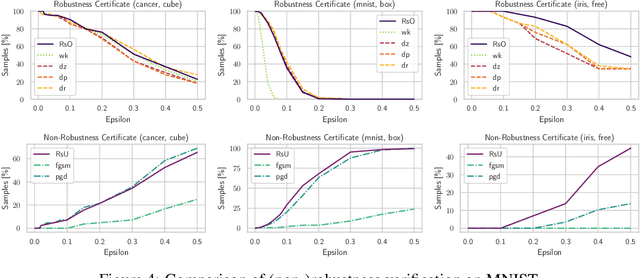
Neural networks achieve outstanding accuracy in classification and regression tasks. However, understanding their behavior still remains an open challenge that requires questions to be addressed on the robustness, explainability and reliability of predictions. We answer these questions by computing reachable sets of neural networks, i.e. sets of outputs resulting from continuous sets of inputs. We provide two efficient approaches that lead to over- and under-approximations of the reachable set. This principle is highly versatile, as we show. First, we analyze and enhance the robustness properties of both classifiers and regression models. This is in contrast to existing works, which only handle classification. Specifically, we verify (non-)robustness, propose a robust training procedure, and show that our approach outperforms adversarial attacks as well as state-of-the-art methods of verifying classifiers for non-norm bound perturbations. We also provide a technique of distinguishing between reliable and non-reliable predictions for unlabeled inputs, quantify the influence of each feature on a prediction, and compute a feature ranking.