 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in a Name? Reducing Bias in Bios without Access to Protected Attributes
Apr 10, 2019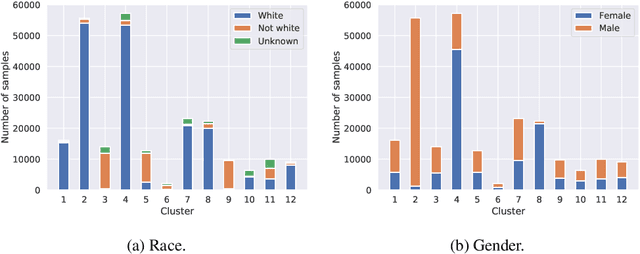
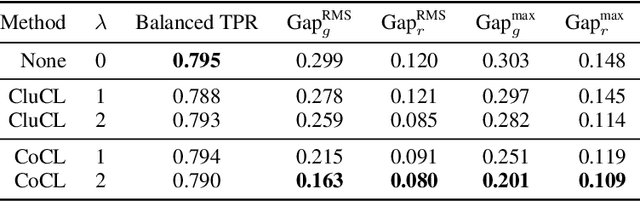
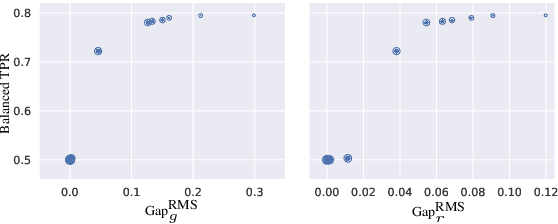
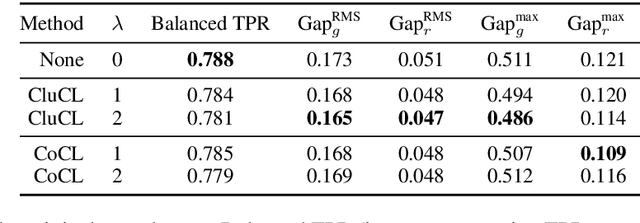
There is a growing body of work that proposes methods for mitigating bias in machine learning systems. These methods typically rely on access to protected attributes such as race, gender, or age. However, this raises two significant challenges: (1) protected attributes may not be available or it may not be legal to use them, and (2) it is often desirable to simultaneously consider multiple protected attributes, as well as their intersections. In the context of mitigating bias in occupation classification, we propose a method for discouraging correlation between the predicted probability of an individual's true occupation and a word embedding of their name. This method leverages the societal biases that are encoded in word embeddings, eliminating the need for access to protected attributes. Crucially, it only requires access to individuals' names at training time and not at deployment time. We evaluate two variations of our proposed method using a large-scale dataset of online biographies. We find that both variations simultaneously reduce race and gender biases, with almost no reduction in the classifier's overall true positive rate.
Adversarial Text Generation Without Reinforcement Learning
Oct 11, 2018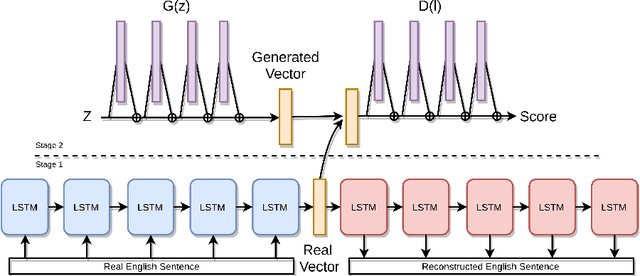

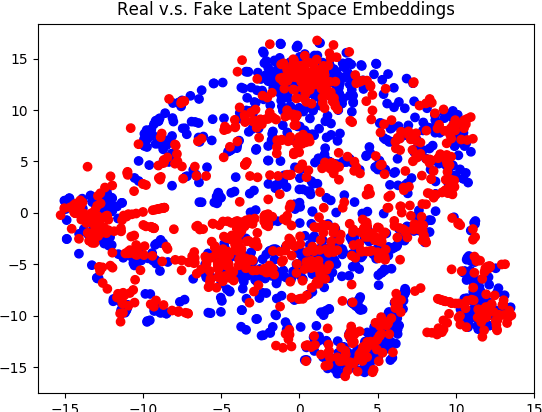
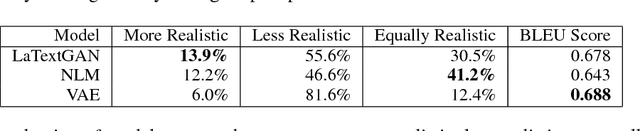
Generative Adversarial Networks (GANs) have experienced a recent surge in popularity, performing competitively in a variety of tasks, especially in computer vision. However, GAN training has shown limited success in natural language processing. This is largely because sequences of text are discrete, and thus gradients cannot propagate from the discriminator to the generator. Recent solutions use reinforcement learning to propagate approximate gradients to the generator, but this is inefficient to train. We propose to utilize an autoencoder to learn a low-dimensional representation of sentences. A GAN is then trained to generate its own vectors in this space, which decode to realistic utterances. We report both random and interpolated samples from the generator. Visualization of sentence vectors indicate our model correctly learns the latent space of the autoencoder. Both human ratings and BLEU scores show that our model generates realistic text against competitive baselines.
Triad-based Neural Network for Coreference Resolution
Sep 18, 2018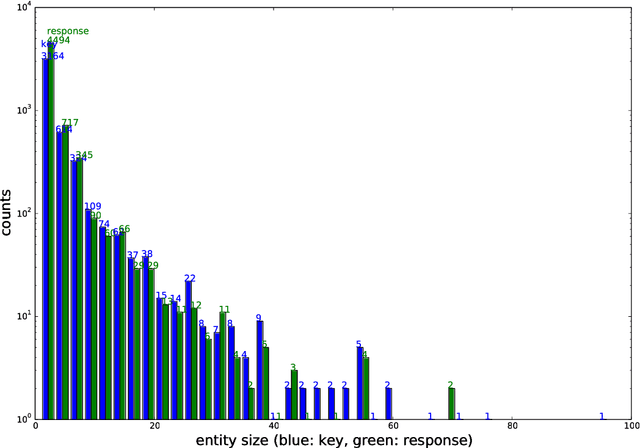
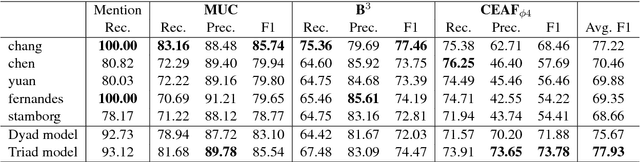

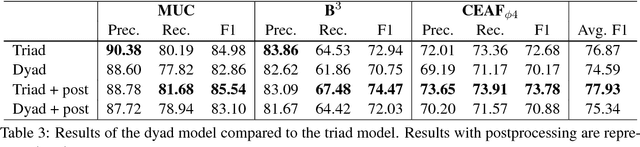
We propose a triad-based neural network system that generates affinity scores between entity mentions for coreference resolution. The system simultaneously accepts three mentions as input, taking mutual dependency and logical constraints of all three mentions into account, and thus makes more accurate predictions than the traditional pairwise approach. Depending on system choices, the affinity scores can be further used in clustering or mention ranking. Our experiments show that a standard hierarchical clustering using the scores produces state-of-art results with gold mentions on the English portion of CoNLL 2012 Shared Task. The model does not rely on many handcrafted features and is easy to train and use. The triads can also be easily extended to polyads of higher orders. To our knowledge, this is the first neural network system to model mutual dependency of more than two members at mention level.
Adversarial Decomposition of Text Representation
Aug 27, 2018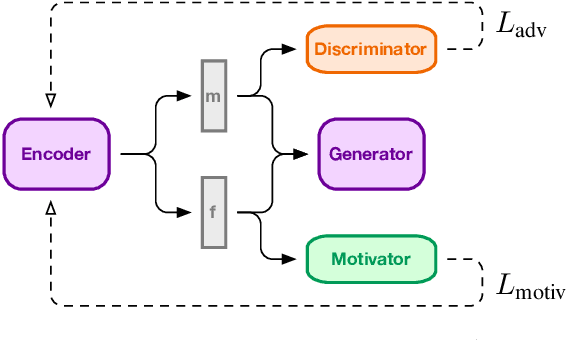

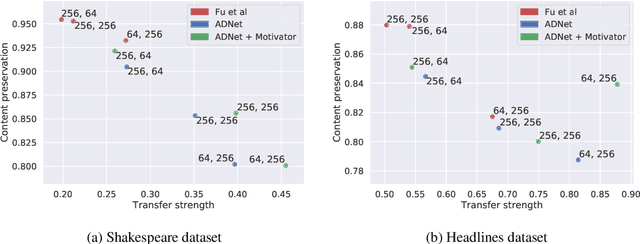

In this paper, we present a method for adversarial decomposition of text representation. This method can be used to decompose a representation of an input sentence into several independent vectors, where each vector is responsible for a specific aspect of the input sentence. We evaluate the proposed method on several case studies: the conversion between different social registers, diachronic language change and the decomposition of the sentiment polarity of input sentences. We show that the proposed method is capable of fine-grained controlled change of these aspects of the input sentence. The model uses adversarial-motivational training and includes a special motivational loss, which acts opposite to the discriminator and encourages a better decomposition. Finally, we evaluate the obtained meaning embeddings on a downstream task of paraphrase detection and show that they are significantly better than embeddings of a regular autoencoder.
CliNER 2.0: Accessible and Accurate Clinical Concept Extraction
Mar 06, 2018
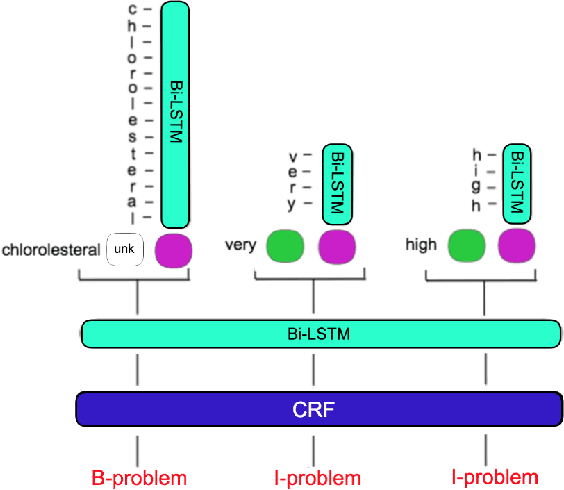

Clinical notes often describe important aspects of a patient's stay and are therefore critical to medical research. Clinical concept extraction (CCE) of named entities - such as problems, tests, and treatments - aids in forming an understanding of notes and provides a foundation for many downstream clinical decision-making tasks. Historically, this task has been posed as a standard named entity recognition (NER) sequence tagging problem, and solved with feature-based methods using handengineered domain knowledge. Recent advances, however, have demonstrated the efficacy of LSTM-based models for NER tasks, including CCE. This work presents CliNER 2.0, a simple-to-install, open-source tool for extracting concepts from clinical text. CliNER 2.0 uses a word- and character- level LSTM model, and achieves state-of-the-art performance. For ease of use, the tool also includes pre-trained models available for public use.
Temporal Information Extraction for Question Answering Using Syntactic Dependencies in an LSTM-based Architecture
Oct 05, 2017
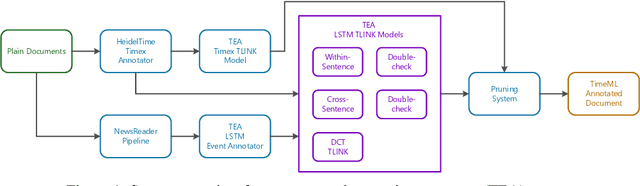

In this paper, we propose to use a set of simple, uniform in architecture LSTM-based models to recover different kinds of temporal relations from text. Using the shortest dependency path between entities as input, the same architecture is used to extract intra-sentence, cross-sentence, and document creation time relations. A "double-checking" technique reverses entity pairs in classification, boosting the recall of positive cases and reducing misclassifications between opposite classes. An efficient pruning algorithm resolves conflicts globally. Evaluated on QA-TempEval (SemEval2015 Task 5), our proposed technique outperforms state-of-the-art methods by a large margin.
Here's My Point: Joint Pointer Architecture for Argument Mining
May 08, 2017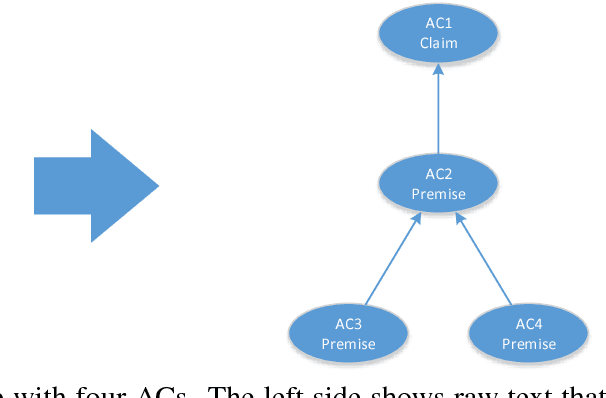
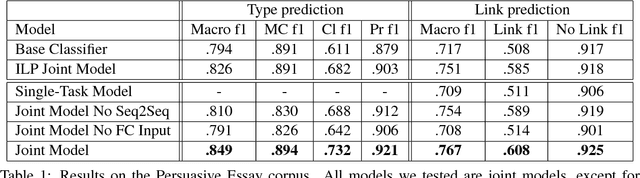
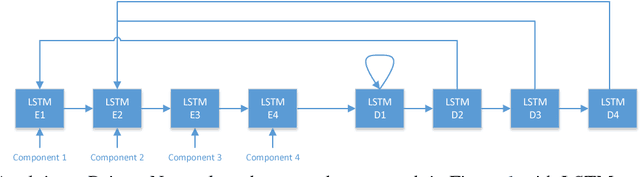
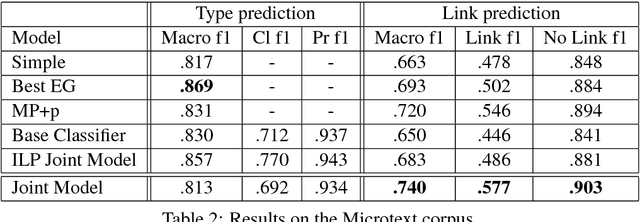
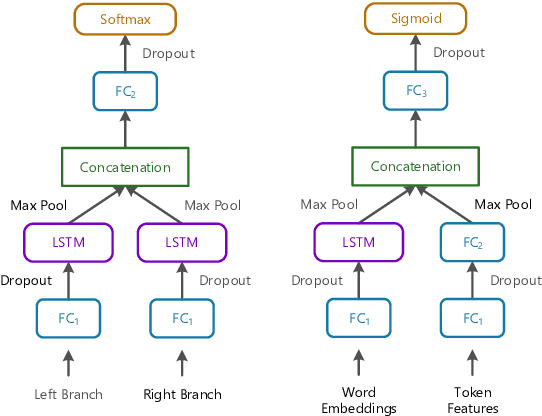
One of the major goals in automated argumentation mining is to uncover the argument structure present in argumentative text. In order to determine this structure, one must understand how different individual components of the overall argument are linked. General consensus in this field dictates that the argument components form a hierarchy of persuasion, which manifests itself in a tree structure. This work provides the first neural network-based approach to argumentation mining, focusing on the two tasks of extracting links between argument components, and classifying types of argument components. In order to solve this problem, we propose to use a joint model that is based on a Pointer Network architecture. A Pointer Network is appealing for this task for the following reasons: 1) It takes into account the sequential nature of argument components; 2) By construction, it enforces certain properties of the tree structure present in argument relations; 3) The hidden representations can be applied to auxiliary tasks. In order to extend the contribution of the original Pointer Network model, we construct a joint model that simultaneously attempts to learn the type of argument component, as well as continuing to predict links between argument components. The proposed joint model achieves state-of-the-art results on two separate evaluation corpora, achieving far superior performance than a regular Pointer Network model. Our results show that optimizing for both tasks, and adding a fully-connected layer prior to recurrent neural network input, is crucial for high performance.
Forced to Learn: Discovering Disentangled Representations Without Exhaustive Labels
May 01, 2017
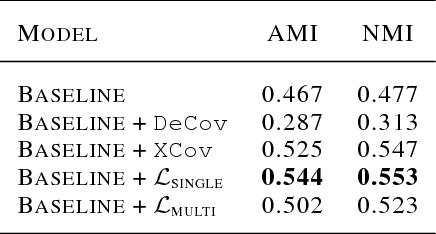
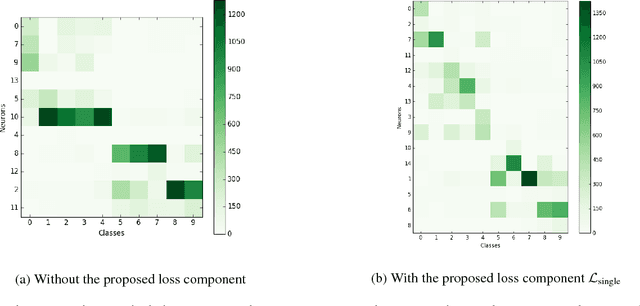
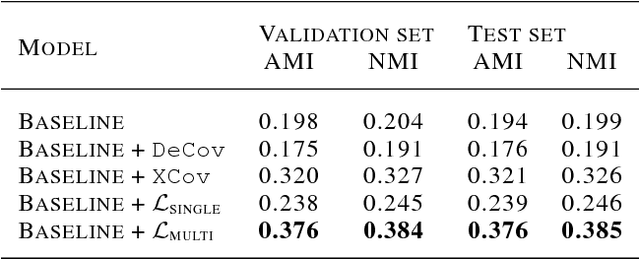
Learning a better representation with neural networks is a challenging problem, which was tackled extensively from different prospectives in the past few years. In this work, we focus on learning a representation that could be used for a clustering task and introduce two novel loss components that substantially improve the quality of produced clusters, are simple to apply to an arbitrary model and cost function, and do not require a complicated training procedure. We evaluate them on two most common types of models, Recurrent Neural Networks and Convolutional Neural Networks, showing that the approach we propose consistently improves the quality of KMeans clustering in terms of Adjusted Mutual Information score and outperforms previously proposed methods.
#HashtagWars: Learning a Sense of Humor
Apr 15, 2017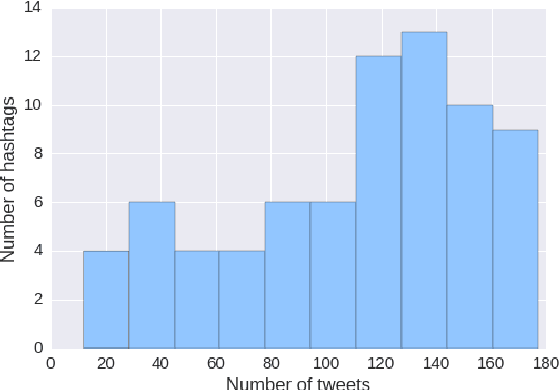
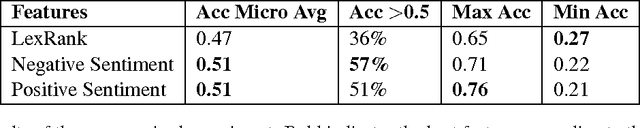

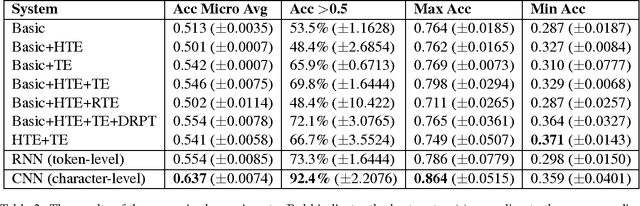
In this work, we present a new dataset for computational humor, specifically comparative humor ranking, which attempts to eschew the ubiquitous binary approach to humor detection. The dataset consists of tweets that are humorous responses to a given hashtag. We describe the motivation for this new dataset, as well as the collection process, which includes a description of our semi-automated system for data collection. We also present initial experiments for this dataset using both unsupervised and supervised approaches. Our best supervised system achieved 63.7% accuracy, suggesting that this task is much more difficult than comparable humor detection tasks. Initial experiments indicate that a character-level model is more suitable for this task than a token-level model, likely due to a large amount of puns that can be captured by a character-level model.
Evaluating Creative Language Generation: The Case of Rap Lyric Ghostwriting
Dec 09, 2016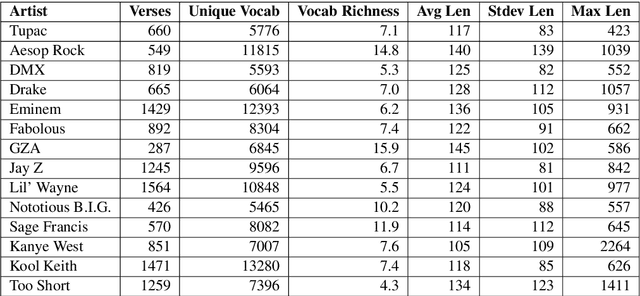

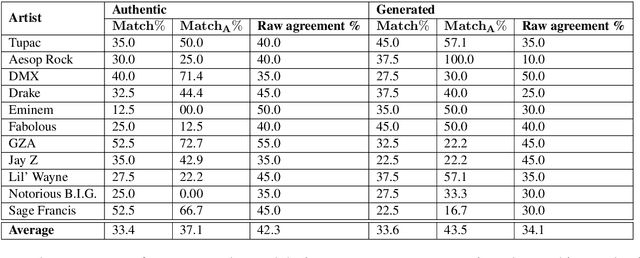
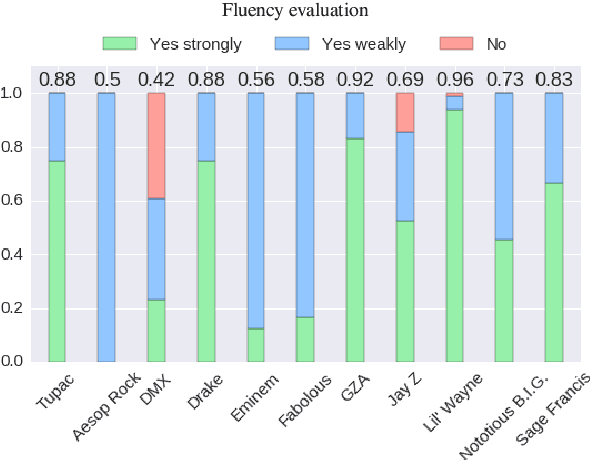
Language generation tasks that seek to mimic human ability to use language creatively are difficult to evaluate, since one must consider creativity, style, and other non-trivial aspects of the generated text. The goal of this paper is to develop evaluation methods for one such task, ghostwriting of rap lyrics, and to provide an explicit, quantifiable foundation for the goals and future directions of this task. Ghostwriting must produce text that is similar in style to the emulated artist, yet distinct in content. We develop a novel evaluation methodology that addresses several complementary aspects of this task, and illustrate how such evaluation can be used to meaningfully analyze system performance. We provide a corpus of lyrics for 13 rap artists, annotated for stylistic similarity, which allows us to assess the feasibility of manual evaluation for generated verse.