 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient DP-SGD Mechanism for Large Scale NLP Models
Jul 14, 2021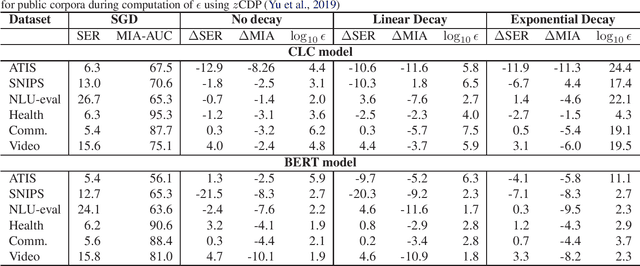
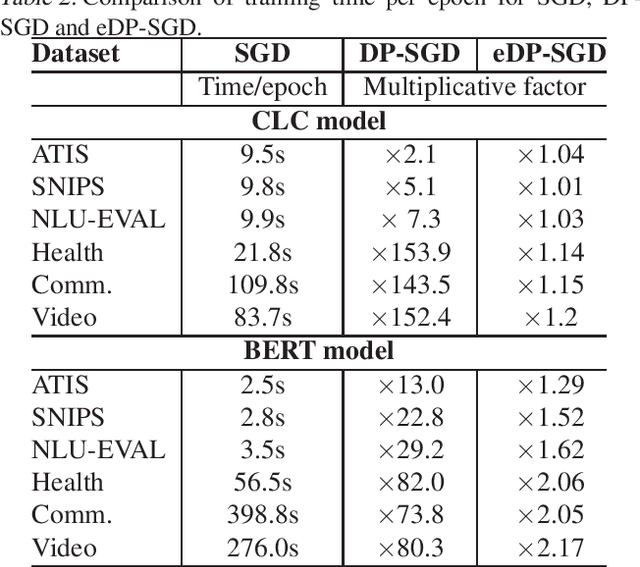
Recent advances in deep learning have drastically improved performance on many Natural Language Understanding (NLU) tasks. However, the data used to train NLU models may contain private information such as addresses or phone numbers, particularly when drawn from human subjects. It is desirable that underlying models do not expose private information contained in the training data. Differentially Private Stochastic Gradient Descent (DP-SGD) has been proposed as a mechanism to build privacy-preserving models. However, DP-SGD can be prohibitively slow to train. In this work, we propose a more efficient DP-SGD for training using a GPU infrastructure and apply it to fine-tuning models based on LSTM and transformer architectures. We report faster training times, alongside accuracy, theoretical privacy guarantees and success of Membership inference attacks for our models and observe that fine-tuning with proposed variant of DP-SGD can yield competitive models without significant degradation in training time and improvement in privacy protection. We also make observations such as looser theoretical $\epsilon, \delta$ can translate into significant practical privacy gains.
BERT Busters: Outlier Dimensions that Disrupt Transformers
Jun 02, 2021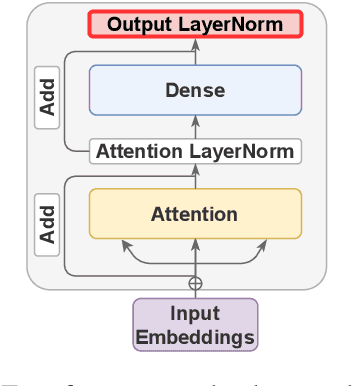

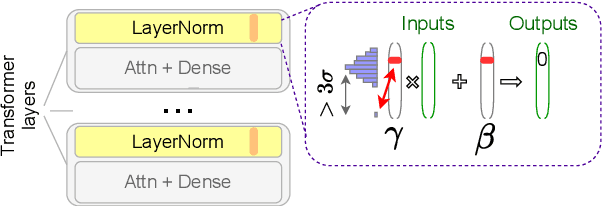
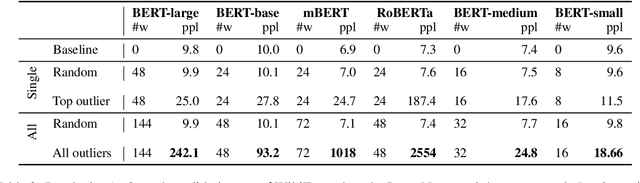
Multiple studies have shown that Transformers are remarkably robust to pruning. Contrary to this received wisdom, we demonstrate that pre-trained Transformer encoders are surprisingly fragile to the removal of a very small number of features in the layer outputs (<0.0001% of model weights). In case of BERT and other pre-trained encoder Transformers, the affected component is the scaling factors and biases in the LayerNorm. The outliers are high-magnitude normalization parameters that emerge early in pre-training and show up consistently in the same dimensional position throughout the model. We show that disabling them significantly degrades both the MLM loss and the downstream task performance. This effect is observed across several BERT-family models and other popular pre-trained Transformer architectures, including BART, XLNet and ELECTRA; we also show a similar effect in GPT-2.
Continual Learning for Neural Semantic Parsing
Oct 15, 2020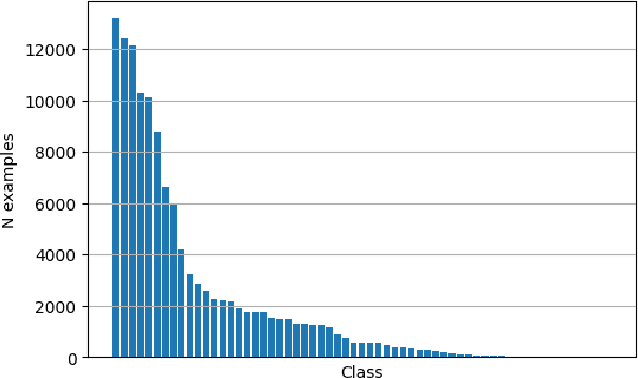
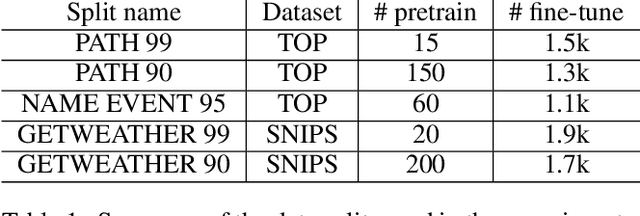
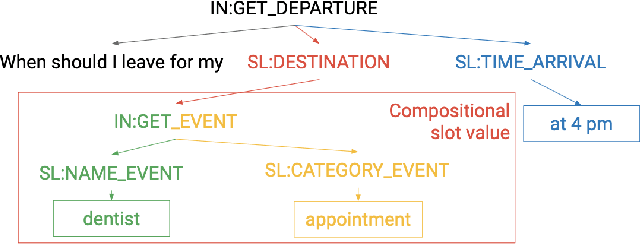
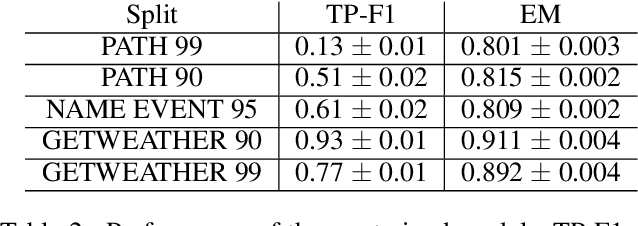
A semantic parsing model is crucial to natural language processing applications such as goal-oriented dialogue systems. Such models can have hundreds of classes with a highly non-uniform distribution. In this work, we show how to efficiently (in terms of computational budget) improve model performance given a new portion of labeled data for a specific low-resource class or a set of classes. We demonstrate that a simple approach with a specific fine-tuning procedure for the old model can reduce the computational costs by ~90% compared to the training of a new model. The resulting performance is on-par with a model trained from scratch on a full dataset. We showcase the efficacy of our approach on two popular semantic parsing datasets, Facebook TOP, and SNIPS.
When BERT Plays the Lottery, All Tickets Are Winning
May 01, 2020
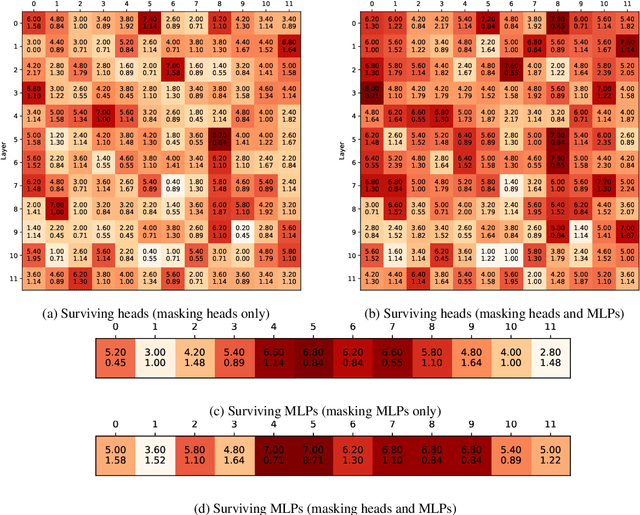
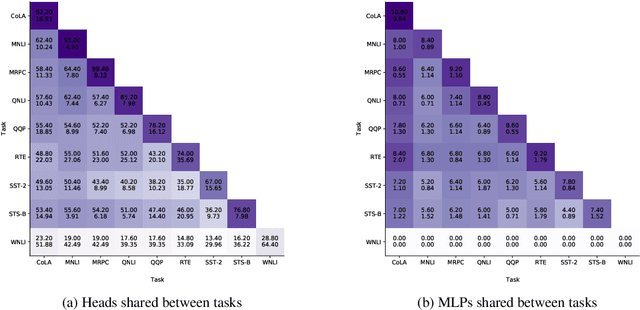
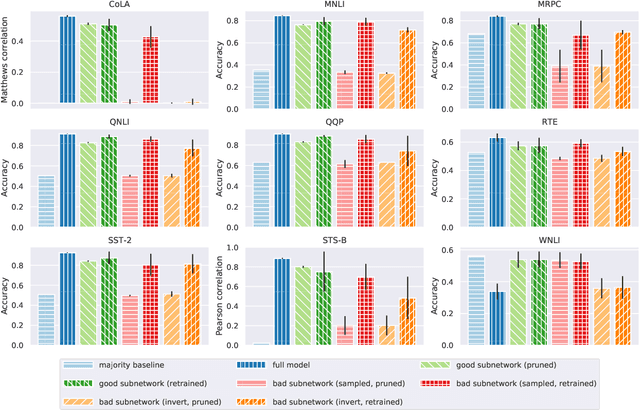
Much of the recent success in NLP is due to the large Transformer-based models such as BERT (Devlin et al, 2019). However, these models have been shown to be reducible to a smaller number of self-attention heads and layers. We consider this phenomenon from the perspective of the lottery ticket hypothesis. For fine-tuned BERT, we show that (a) it is possible to find a subnetwork of elements that achieves performance comparable with that of the full model, and (b) similarly-sized subnetworks sampled from the rest of the model perform worse. However, the "bad" subnetworks can be fine-tuned separately to achieve only slightly worse performance than the "good" ones, indicating that most weights in the pre-trained BERT are potentially useful. We also show that the "good" subnetworks vary considerably across GLUE tasks, opening up the possibilities to learn what knowledge BERT actually uses at inference time.
A Primer in BERTology: What we know about how BERT works
Feb 27, 2020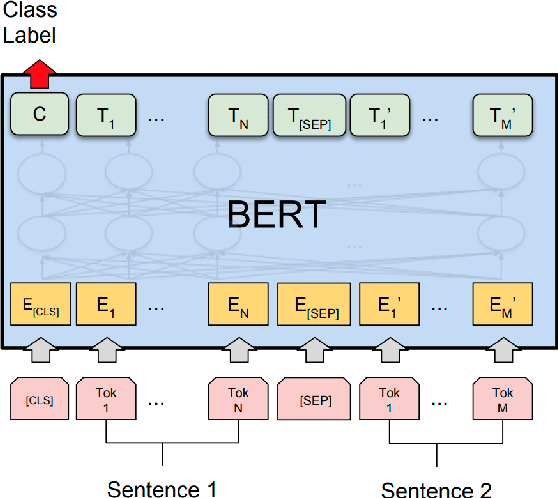
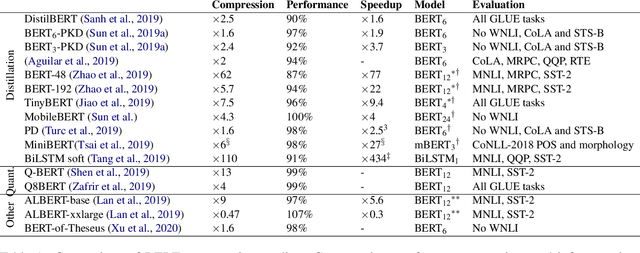
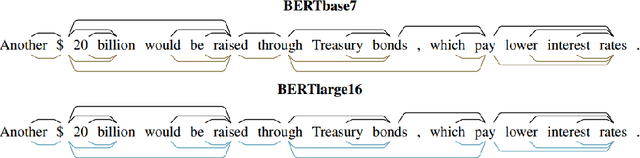
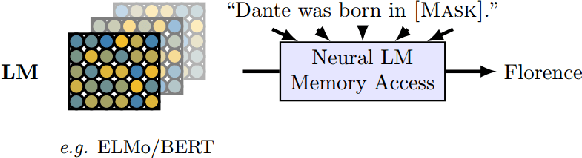
Transformer-based models are now widely used in NLP, but we still do not understand a lot about their inner workings. This paper describes what is known to date about the famous BERT model (Devlin et al. 2019), synthesizing over 40 analysis studies. We also provide an overview of the proposed modifications to the model and its training regime. We then outline the directions for further research.
Memory-Augmented Recurrent Networks for Dialogue Coherence
Oct 16, 2019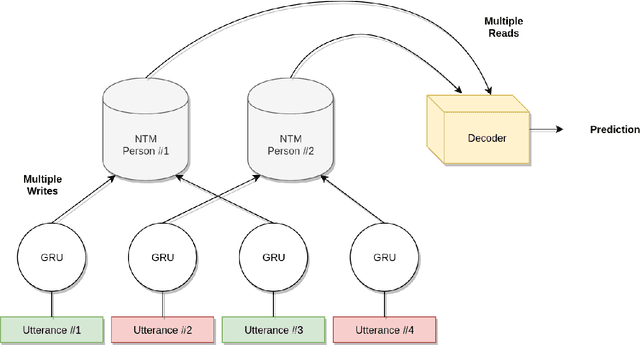
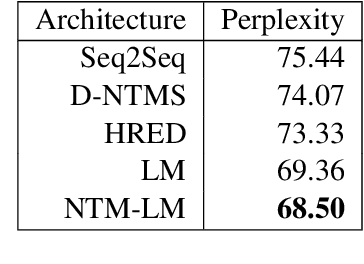
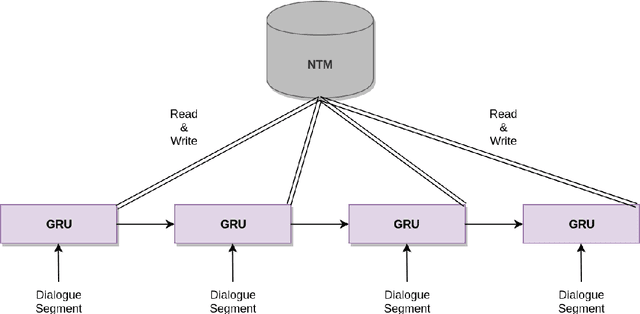

Recent dialogue approaches operate by reading each word in a conversation history, and aggregating accrued dialogue information into a single state. This fixed-size vector is not expandable and must maintain a consistent format over time. Other recent approaches exploit an attention mechanism to extract useful information from past conversational utterances, but this introduces an increased computational complexity. In this work, we explore the use of the Neural Turing Machine (NTM) to provide a more permanent and flexible storage mechanism for maintaining dialogue coherence. Specifically, we introduce two separate dialogue architectures based on this NTM design. The first design features a sequence-to-sequence architecture with two separate NTM modules, one for each participant in the conversation. The second memory architecture incorporates a single NTM module, which stores parallel context information for both speakers. This second design also replaces the sequence-to-sequence architecture with a neural language model, to allow for longer context of the NTM and greater understanding of the dialogue history. We report perplexity performance for both models, and compare them to existing baselines.
Injecting Hierarchy with U-Net Transformers
Oct 16, 2019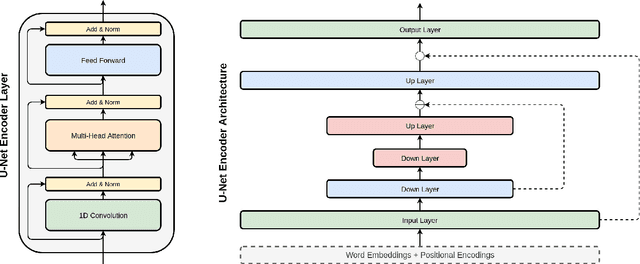

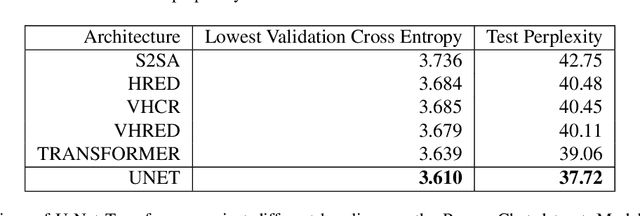
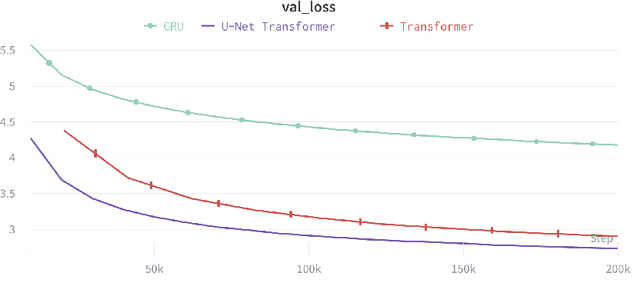
The Transformer architecture has become increasingly popular over the past couple of years, owing to its impressive performance on a number of natural language processing (NLP) tasks. However, it may be argued that the Transformer architecture lacks an explicit hierarchical representation, as all computations occur on word-level representations alone, and therefore, learning structure poses a challenge for Transformer models. In the present work, we introduce hierarchical processing into the Transformer model, taking inspiration from the U-Net architecture, popular in computer vision for its hierarchical view of natural images. We propose a novel architecture that combines ideas from Transformer and U-Net models to incorporate hierarchy at multiple levels of abstraction. We empirically demonstrate that the proposed architecture outperforms the vanilla Transformer and strong baselines in the chit-chat dialogue and machine translation domains.
Revealing the Dark Secrets of BERT
Sep 11, 2019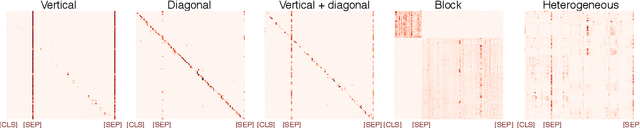
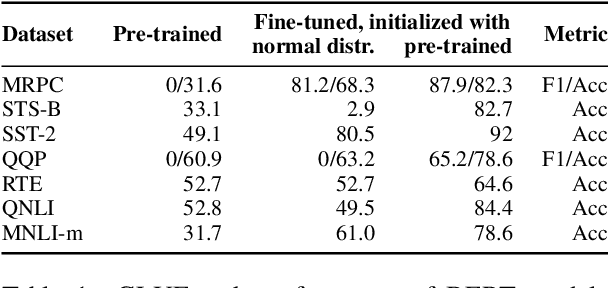
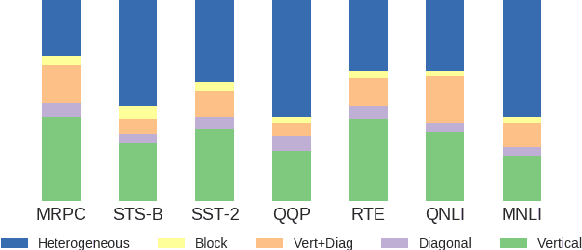
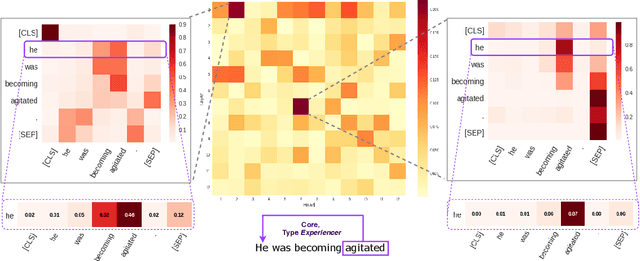
BERT-based architectures currently give state-of-the-art performance on many NLP tasks, but little is known about the exact mechanisms that contribute to its success. In the current work, we focus on the interpretation of self-attention, which is one of the fundamental underlying components of BERT. Using a subset of GLUE tasks and a set of handcrafted features-of-interest, we propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT's heads. Our findings suggest that there is a limited set of attention patterns that are repeated across different heads, indicating the overall model overparametrization. While different heads consistently use the same attention patterns, they have varying impact on performance across different tasks. We show that manually disabling attention in certain heads leads to a performance improvement over the regular fine-tuned BERT models.
NarrativeTime: Dense High-Speed Temporal Annotation on a Timeline
Aug 29, 2019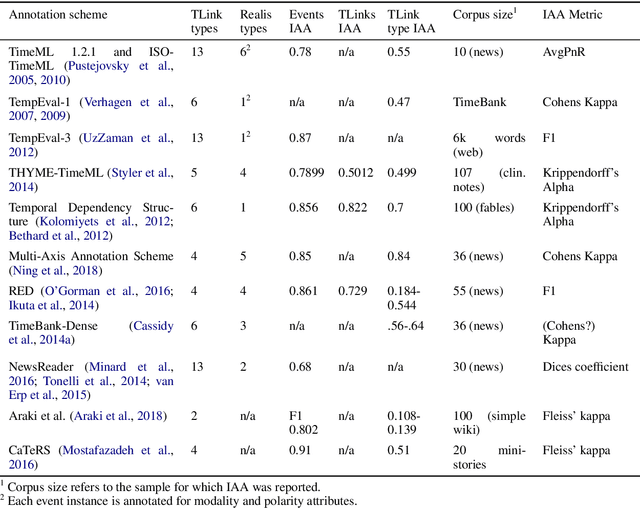
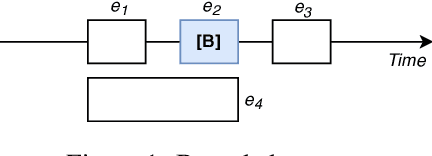
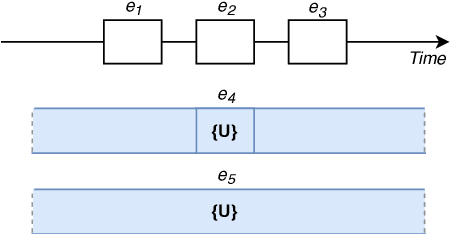
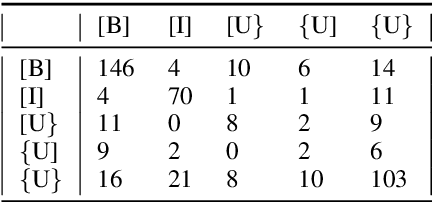
We present NarrativeTime, a new timeline-based annotation scheme for temporal order of events in text, and a new densely annotated fiction corpus comparable to TimeBank-Dense. NarrativeTime is considerably faster than schemes based on event pairs such as TimeML, and it produces more temporal links between events than TimeBank-Dense, while maintaining comparable agreement on temporal links. This is achieved through new strategies for encoding vagueness in temporal relations and an annotation workflow that takes into account the annotators' chunking and commonsense reasoning strategies. NarrativeTime comes with new specialized web-based tools for annotation and adjudication.
Solving Math Word Problems with Double-Decoder Transformer
Aug 28, 2019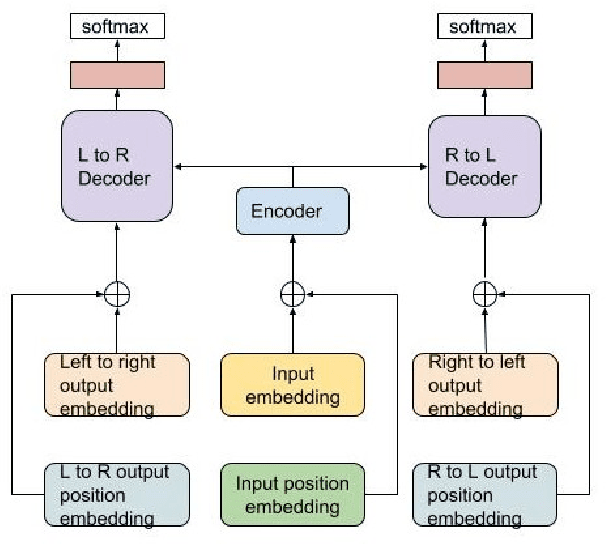
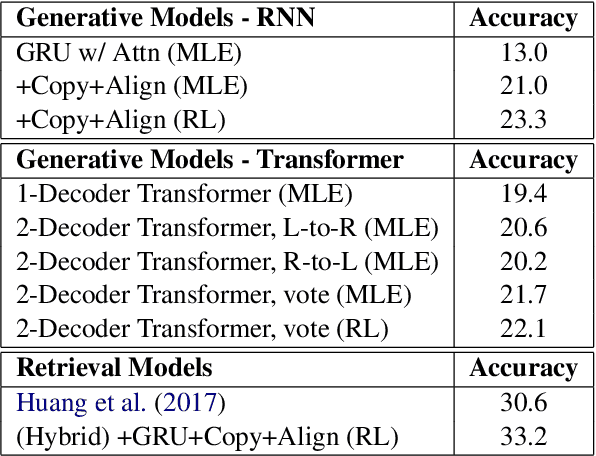
This paper proposes a Transformer-based model to generate equations for math word problems. It achieves much better results than RNN models when copy and align mechanisms are not used, and can outperform complex copy and align RNN models. We also show that training a Transformer jointly in a generation task with two decoders, left-to-right and right-to-left, is beneficial. Such a Transformer performs better than the one with just one decoder not only because of the ensemble effect, but also because it improves the encoder training procedure. We also experiment with adding reinforcement learning to our model, showing improved performance compared to MLE training.