 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Active Learning Algorithms using Real-World Crowd-sourced Text Annotations
Apr 25, 2026Active learning algorithms automatically identify the most informative samples from large amounts of unlabeled data and tremendously reduce human annotation effort in inducing a machine learning model. In a conventional active learning setup, the labeling oracles are assumed to be infallible, that is, they always provide correct answers (in terms of class labels) to the queried unlabeled instances, which cannot be guaranteed in real-world applications. To this end, a body of research has focused on the development of active learning algorithms in the presence of imperfect / noisy oracles. Existing research on active learning with noisy oracles typically simulate the oracles using machine learning models; however, real-world situations are much more challenging, and using ML models to simulate the annotation patterns may not appropriately capture the nuances of real-world annotation challenges. In this research, we first collect annotations of text samples (from 3 benchmark text classification datasets) from crowd-sourced workers through a crowd-sourcing platform. We then conduct extensive empirical studies of 8 commonly used active learning techniques (in conjunction with deep neural networks) using the obtained annotations. Our analyses sheds light on the performance of these techniques under real-world challenges, where annotators can provide incorrect labels, and can also refuse to provide labels. We hope this research will provide valuable insights that will be useful for the deployment of deep active learning systems in real-world applications. The obtained annotations can be accessed at https://github.com/varuntotakura/al_rcta/.
* The proposed dataset can be accessed at https://github.com/varuntotakura/al_rcta/. To appear in Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN 2026)
DiffNMR2: NMR Guided Sampling Acquisition Through Diffusion Model Uncertainty
Feb 06, 2025



Nuclear Magnetic Resonance (NMR) spectrometry uses electro-frequency pulses to probe the resonance of a compound's nucleus, which is then analyzed to determine its structure. The acquisition time of high-resolution NMR spectra remains a significant bottleneck, especially for complex biological samples such as proteins. In this study, we propose a novel and efficient sub-sampling strategy based on a diffusion model trained on protein NMR data. Our method iteratively reconstructs under-sampled spectra while using model uncertainty to guide subsequent sampling, significantly reducing acquisition time. Compared to state-of-the-art strategies, our approach improves reconstruction accuracy by 52.9\%, reduces hallucinated peaks by 55.6%, and requires 60% less time in complex NMR experiments. This advancement holds promise for many applications, from drug discovery to materials science, where rapid and high-resolution spectral analysis is critical.
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021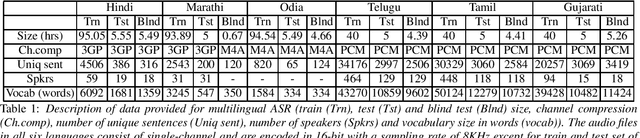
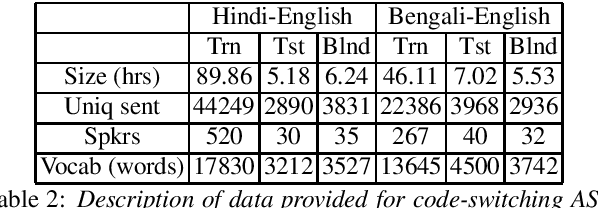
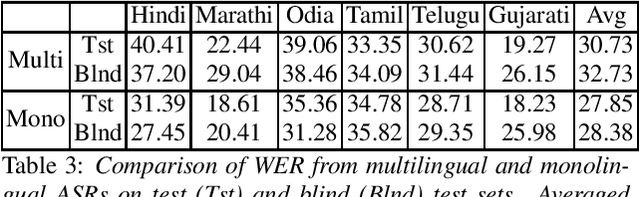
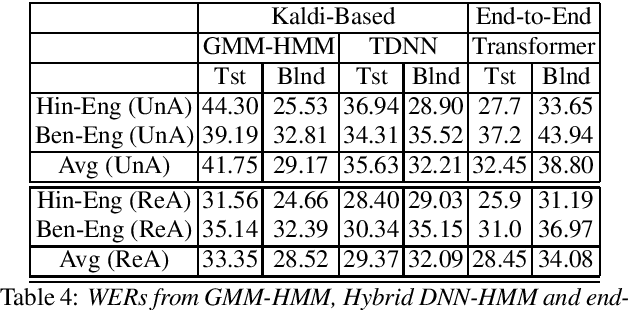
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.